






Transformer本身是一个典型的encoder-decoder模型。
一、Encoder端&Decoder端总览
简单来看一个编码器和一个解码器的作用。

Encoder端由N(原论文中N=6)个相同的大模块堆叠而成。
Decoder端同样由N(原论文中N=6)个相同的大模块堆叠而成。

但是两个模块的组成有所不同。
左:Encoder 右:Decoder

Encoder端每个大模块又由 两 个子模块构成,这两个子模块分别为多头self-attention模块,以及一个前馈神经网络模块。
Encoder端每个大模块接收的输入是不一样的:
(1)第一个大模块接收的输入是输入序列的embedding(embedding可以通过word2vec预训练得来)
(2)其余大模块接收的是其前一个大模块的输出
(3)最后一个模块的输出作为整个Encoder端的输出。
Decoder端每个大模块由 三 个子模块构成,这三个子模块分别为多头self-attention模块、多头Encoder-Decoder attention 交互模块,以及一个前馈神经网络模块。
Decoder端第一个大模块训练时和测试时接收的输入是不一样的,并且每次训练时接收的输入也是不一样的(shifted right)。
二、Encoder端各个子模块
2.1多头注意力模块
缩放点乘积注意力(常用)

多头注意力模块,例如八头。
是把同一个词向量初始化八组不同的QKV。
对每组QKV做 attention 计算,再把结果拼接起来。
最后送入一个全连接层。

多头注意力的作用:学习不同的表征子空间。
2.2前馈神经网络模块
前馈神经网络模块(即图示中的Feed Forward)由两个线性变换组成,中间有一个ReLU激活函数。
三、Decoder端各个子模块
3.1多头注意力模块
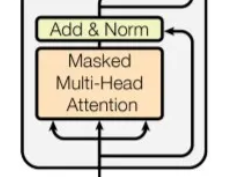
从图中可以看到,Decoder端的多头self-attention相对于Encoder端的多头注意力模块多了一步mask。
因为它在预测时,是“看不到未来的序列的”,所以要将当前预测的单词(token)及其之后的单词(token)全部mask掉。
3.2多头Encoder-Decoder attention 交互模块
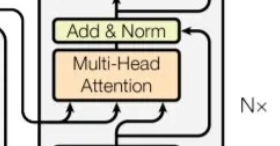
从形式来看
多头Encoder-Decoder attention 交互模块与多头self-attention模块是一致的。
唯一不同的是其Q,K,V矩阵的来源:
其Q矩阵来源于下面子模块的输出(对应到图中即为masked多头self-attention模块经过Add&Norm后的输出)
而K,V矩阵则来源于整个Encoder端的输出
目的:在于让Decoder端的单词(token)给与Encoder端对应的单词(token)“更多的关注(attention weight)”。
3.3 前馈神经网络模块
与Encoder端一致。
四、其他模块
4.1 Add&Norm模块
Add&Norm模块接在Encoder端和Decoder端每个子模块的后面。
Add模块
Add表示残差连接。
Norm模块
Norm表示LayerNorm(LN),层归一化。
因此这个模块的实际输出为
LayerNorm( x + Sublayer(x) )--------Sublayer(x)为子模块的输出。
4.2 Position Encoder
使用原因: transformer模型的attention机制并没有包含位置信息,即一句话中词语在不同的位置时在transformer中是没有区别的。
位置编码:Position Encoder,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置。
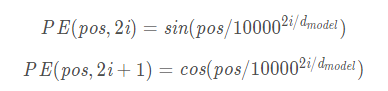
论文中以以上方法计算。
其中,PE为二维矩阵,大小跟输入embedding的维度一样。
参考博客:















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









