






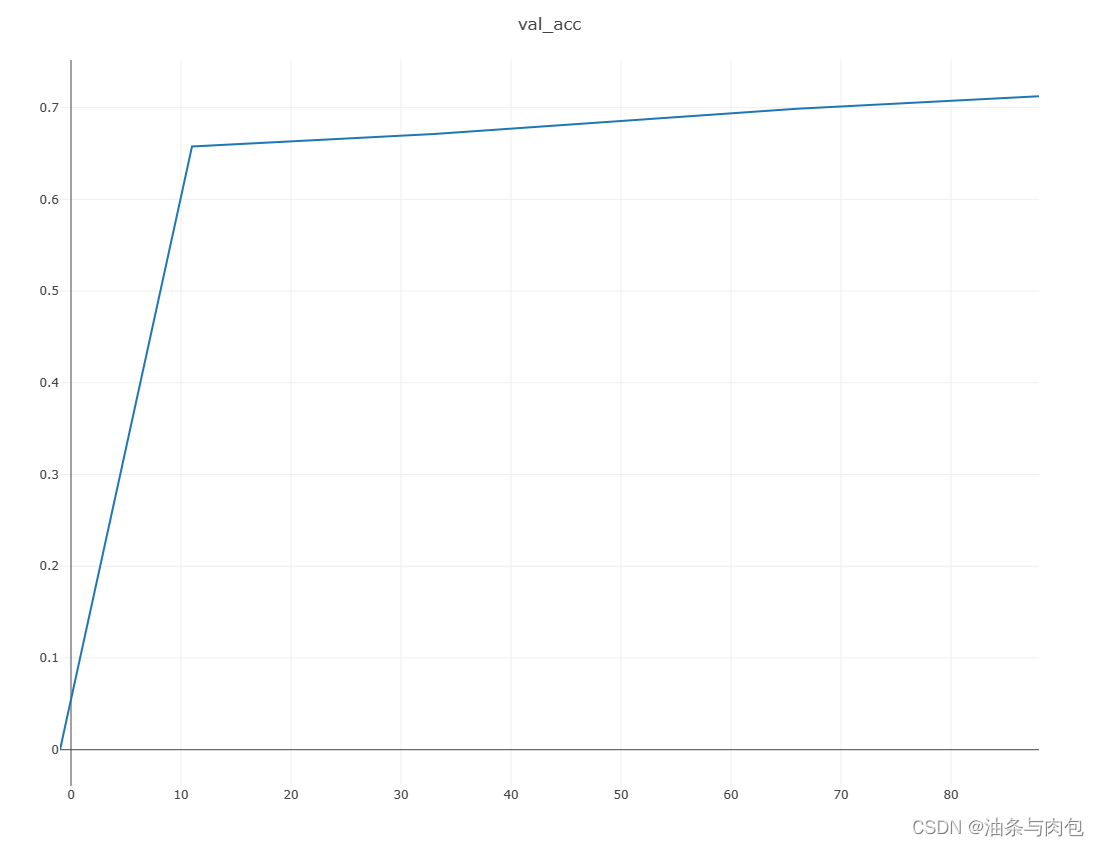
链接:https://pan.baidu.com/s/1rVWr6Y2eQ6g8zahOLjDjAQ?pwd=8888 提取码:8888 青光眼数据集共有364张图:Glaucoma:32,Normal:225,Suspect Glaucoma:107,收集到的青光眼数据集图片较少,后续需要继续补充。代码如下,卷积模型仍然用:ResNet18。 best acc: 0.7123287671232876 best epoch: 7 test acc: 0.6986301369863014
准确率达到70%,说明残差网络模型性能针对多分类图像数据集的预测性能比较优的。
transforms.Normalize(mean=[0, 0, 0], std=[1, 1, 1])问题:图片均值化函数均值和方差设定的0,1. 并没有参考图片数据给出更合理的均值和方差,可能会影响准确率。
train.py
import torch
from torch import optim, nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from data_loader import DIYData_loader
from resnet import ResNet18
batchsz = 20
picture_resize = 224
lr = 1e-3
epochs = 10
device = torch.device('cuda')
torch.manual_seed(1234)
train_db = DIYData_loader('D:\python pycharm learning\清华大佬课程\second\青光眼分类', picture_resize, mode='train')
val_db = DIYData_loader('D:\python pycharm learning\清华大佬课程\second\青光眼分类', picture_resize, mode='val')
test_db = DIYData_loader('D:\python pycharm learning\清华大佬课程\second\青光眼分类', picture_resize, mode='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True,
num_workers=4)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
viz = visdom.Visdom()
def evalute(model, loader):
model.eval()
correct = 0
total = len(loader.dataset)
for x, y in loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(5).to(device)
optimizer = optim.Adam(model.parameters(),lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc,best_epoch =0, 0
global_step = 0
viz.line([0],[-1], win='loss',opts = dict(title='loss'))
viz.line([0],[-1], win='val_acc', opts=dict(title='val_acc'))
for epoch in range(epochs):
for step, (x,y) in enumerate(train_loader):
#x:[b,3,224,224],y :[b]
x,y = x.to(device),y.to(device)
model.train()
logits = model(x)
loss = criteon(logits,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update = 'append')
global_step+=1
if epoch %1 ==0:
val_acc = evalute(model,val_loader)
if val_acc > best_acc:
best_epoch =epoch
best_acc =val_acc
torch.save(model.state_dict(),'best.mdl')
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:',best_acc,'best epoch:',best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(model,test_loader)
print('test acc:', test_acc)
if __name__=='__main__':
main()resnet.py
import torch
from torch import nn
from torch.nn import functional as F
"定义残差块,改变通道数,改变高宽[b,ch_in,h,w]=>[b.ou_ch,(h-3+stride+2)/stride,(w-3+stride+2)/stride]"
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
#[b,ch_in,h,w]=>[b,ch_out,h,w]
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
#对小批量数据进行正则化处理
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, (h-1+stride)/stride, (w-1+stride)/stride]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
"定义残差网络"
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h ,w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# # [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# # [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
# [b, 256, 3, 3]
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x)) #[b,16,74,74]
#print('conv1(x):',x.shape)
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x) #[b,32,25,25]
#print('blk1(x):',x.shape)
x = self.blk2(x) #[b,64,9,9]
#print('blk2(x):',x.shape)
x = self.blk3(x) #[b,128,5,5]
#print('blk3(x):',x.shape)
x = self.blk4(x) #[b,256,3,3]
#print('blk4(x):',x.shape)
x = x.view(x.size(0), -1)
#print('flatten:',x.shape)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128,3)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
print('block:', out.shape)
model = ResNet18(5)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if __name__ == '__main__':
main()
DIYdata_loader.py
# 数据集共有364张图:Glaucoma:32,Normal:225,Suspect Glaucoma:107
import torch
import os, glob
import random, csv
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from torchvision import transforms
# 自定义数据加载类
class DIYData_loader(Dataset):
def __init__(self, root, resize, mode): # root:文件所在目录,resize:图像分辨率调整一致,mode:当前类何功能
super(DIYData_loader, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # 对每个加载的文件进行编码:'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4
for name in sorted(os.listdir((os.path.join(root)))): # 对指定root中的文件进行排序
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys()) # keys返回列表当中的value,len计算列表长度
#print(self.name2label) # 根据文件顺序,以idx:文件名,vlaue:0,1,2,3,4,生成列表
# images labels
self.images, self.labels = self.load_csv('images.csv') # load_csv要么先创建images.csv,要么直接读取images.csv,
#print('data_len:',len(self.images))
if mode == 'train': # train dataset 60% of ALL DATA
self.images = self.images[:int(0.6 * len(self.images))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'validation': # val dataset 60%-80% of ALL DATA
self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # test dataset 80%-100% of ALL DATA
self.images = self.images[int(0.8 * len(self.images)):int(len(self.images))]
self.labels = self.labels[int(0.8 * len(self.labels)):int(len(self.labels))]
# images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
# images 还是图片的地址列表,需要__getitem__继续转换
# image,label 不能把所有图片全部加载到内存,可能会爆内存
def load_csv(self, filename): # 生成,读取filename文件
# filename 不存在:生成filename
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
# .../pokemen/mewtwo/00001.png 加载进images列表
# 实际上是加载每张图片的地址
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images), images[0])
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # .....\bulbasaur\00000000.png
name = img.split(os.sep)[-2] # 指:bulbasaur 图片真实类别
label = self.name2label[name] # 在name2label列表根据name找出对应的value:0,1...
# .....\bulbasaur\00000000.png , 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# filename 存在:直接读取filename
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
# '...pokemon\bulbasaur\00000000.png', 0
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
return len(self.images)
def denormalize(self, x_hat): # 对已经进行规范化处理的totensor,去除规范化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std +mean
# x:[c,h,w]
# mean:[3]=>[3,1,1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def __getitem__(self, idx):
pass
# idx~[0~len(images)]
# self.iamges,self.labels
# images[0]: D:\python pycharm learning\清华大佬课程\fisrt\pokemon\mewtwo\00000081.png
# #labels[0]:2
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string image => image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))), # 压缩到稍大
transforms.RandomRotation(20), # 图片旋转,增加图片的复杂度,但是又不会使网络太复杂
transforms.CenterCrop(self.resize), # 可能会有其他的底存在
transforms.ToTensor(),
#transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transforms.Normalize(mean=[0, 0, 0], std=[1, 1, 1])
# R mean:0.854,std:0.229
])
img = tf(img)
label = torch.tensor(label)
# Pokemon类根据一个索引每次返回一个img(三位张量),一个label(0维张量)
return img, label # img,label打包成元组返回
def main():
import visdom # 启动 python -m visdom.server,http://localhost:8097
import time
viz = visdom.Visdom()
db = DIYData_loader('D:\python pycharm learning\清华大佬课程\second\青光眼分类', 224, 'train')
# x,y = next(iter(db))
# print('sample:',x.shape,y.shape,y)
# viz.images(db.denormalize(x), win='sample_x', opts=dict(title='sample_x'))
# DataLoader加载器按batch_size打乱所有依次在内存当中按批次顺序加载每次批次,
# 每个批次内含batch个Pokemon类返回的对象(元组,列表,字符串)
loader = DataLoader(db, batch_size=20, shuffle=True)
for x, y in loader:
print('x_shape:',x.shape)
viz.images(db.denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
time.sleep(10)
break
if __name__ == '__main__':
main()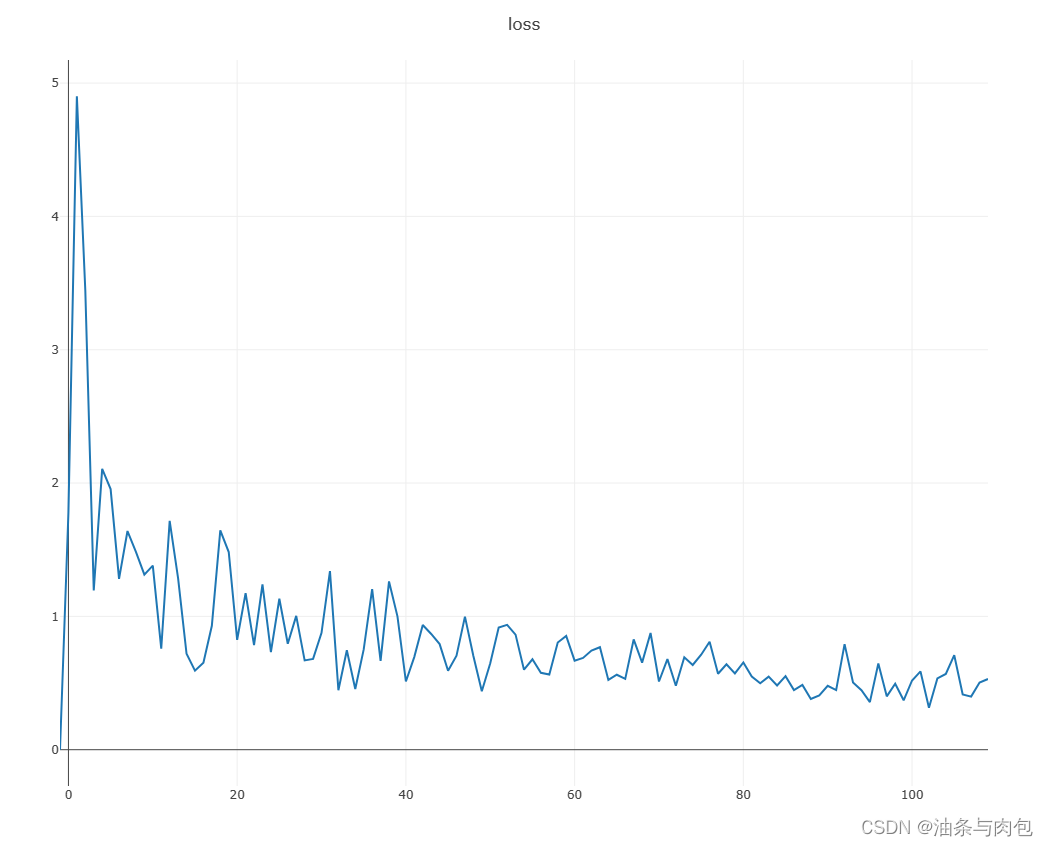















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









