







文章目录

详解Linux-进阶
本篇博客是上一篇 详解Linux(基础篇) 的进阶篇,还没有看过上篇博客的同学建议先花上20多分钟浏览一下上篇的基础,有了上篇博客的基础,再看本文,就会事半功倍,不然就会觉得本文的内容有点突兀。
本文主要介绍了Linux中的定时任务调度、磁盘分区、网络配置、进程管理以及RPM软件包的安装,其中每一个难点都有详细的文字说明和案例以及截图证明,适合新手村的同学快速掌握Linux的知识,也适合高手用来复习和查看指令,毕竟那么多的指令,不可能一下子都记住。
这是2021年的第一篇博客,是在过年这几天忙里偷闲写的🤦♂️,整理不易,如果您觉得本文不错,望一键三连加分享。🤞🤞
关注✨✨博主



1. 定时任务调度
1.1 crond 任务调度
(1)概述
Linux中有一个后台程序,crond,它可以定时的去调度我们设置的任务。
crond的定时任务是反复执行的。
任务调度:是指系统在某个时间执行的特定的命令或程序。

任务调度分类:
- 系统工作:有些重要的工作必须周而复始地执行。如病毒扫描等
- 个别用户工作:个别用户可能希望执行某些程序,比如对mysql 数据库的备份
crontab 进行定时任务的设置
# 基本语法
crontab [选项]
# 编辑Linux后台程序crond去执行某一脚本或程序,编辑调度文件
crontab -e
# 接着输入任务到调度文件
# 执行的脚本,每隔一分钟执行一次 ls -l /etc > /tmp/test.txt
*/1 * * * * ls -l /etc > /tmp/test.txt
| 选项 | 功能 |
|---|---|
| -e | 编辑crontab定时任务 |
| -l | 查询crontab定时任务 |
| -r | 删除当前用户的所有crontab定时任务 |
参数说明:
(1)5个占位符的说明
| 参数 | 含义 | 范围 |
|---|---|---|
第一个 * | 一小时中的第几分钟 | 0-59 |
第二个 * | 一天中的第几个小时 | 0-23 |
第三个 * | 一月中的第几天 | 1-31 |
第四个 * | 一年中的第几个月 | 1-12 |
第五个 * | 一周中的周几 | 0-7(0和7都表示周末) |
(2)特殊符号的说明:
| 符号 | 含义 |
|---|---|
* | 表示任何时间,例:第一个*就表示每小时中的每分钟都执行一次 |
, | 表示不连续的时间,例:0 8,12,16 * * * 表示在每天的8点0分、12点0分,16点0分都执行一次 |
- | 表示连续的时间,例:0 5 * * 1-6 表示在周一到周六的每一天的5点0分都执行一次。 |
*/n | 表示每隔多久执行一次,例:*/10 * * * * 表示每天每隔10分钟就执行一次 |
(3)特定时间案例
| 时间 | 含义 |
|---|---|
30 8 * * * | 每天的8点30分执行一次 |
20 9 * * 3 | 每周三的9点20执行一次 |
0 10 1,15 * * | 每月的1号和15号的10点0分执行一次 |
*/10 5 * * * | 每天的5点,每隔10分钟执行一次 |
10 9 * * 4-6 | 每周的周四到周六的9点10分执行一次 |
(2)应用案例
# 案例一:每隔一分钟,就将当前的日期信息追加到到文件 /tmp/mydate.txt
crontab -e
*/1 * * * * date >> /tmp/mydate.txt
# 案例二:使用脚本完成每隔一分钟,将当前日期和日历都追加到 /home/mycal.txt 文件中
cd /home
# 编写脚本
vim my.sh
date >> /home/mycal.txt
cal >> /home/mycal.txt
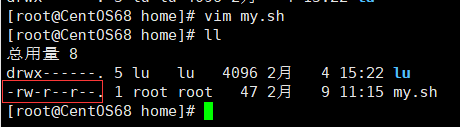
现在这个 my.sh 文件是没有执行权限的,要给他赋予执行权限。
# 给我们写的脚本赋予执行权限
chmod u+x my.sh
写好脚本之后,可以直接使用命令执行,命令如下:
# 执行当前目录下的 my.sh 脚本
./my.sh
但是我们不可能每分钟都手动执行一下这个命令,因此我们可以将其写入调度文件中,让crond去定时调度执行它。
crontab -e
*/1 * * * * /home/my.sh
# 案例三:每天凌晨一点,备份mysql数据库mytest到文件 /home/db.bak文件中
crontab -e
0 1 * * * mysqldump -u root -p 密码 mytest > /home/db.bak
crond 相关指令
# 终止任务调度
crontab -r
# 查看当前用户的所有任务调度
crontab -l
# 重启任务调度
service crond restart
1.2 at 定时任务
1、原理概述
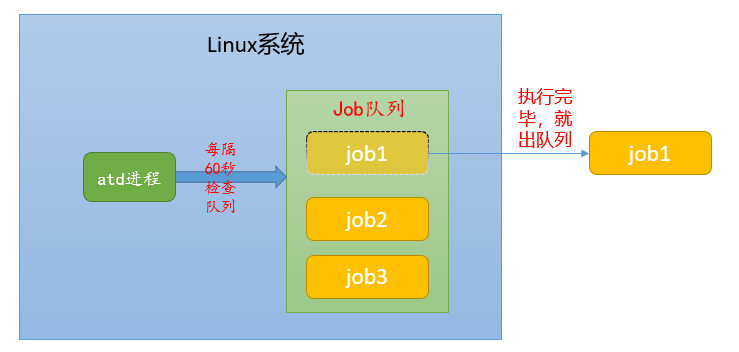
- at 命令是一次性定时计划任务(只执行一次),at 的守护进程 atd 会以后台模式运行,检查作业队列来运行。
- 默认情况下,atd 守护进程每 60 秒检查作业队列,有作业时,会检查作业运行时间,如果时间与当前时间匹配,则运行此作业。
- at 命令是一次性定时计划任务,执行完一个任务后不再执行此任务了
- 在使用 at 命令的时候,一定要保证 atd 进程的启动 , 可以使用相关指令来查看。
# ps -ef 检测当前正在运行的所有进程
ps -ef
# 使用过滤查询,只查看 atd 进程。
ps -ef | grep atd
出现如下内容,则表明 atd 进程正在运行中。

2、at 命令格式
# at 命令,Ctrl+D 结束at命令的输入(输入两次才有效)
at [选项] [时间]
选项如下:
| 选项 | 含义 |
|---|---|
| -m | 当指定的任务完成后,给用户发送邮件,即使没有标准输出 |
| -I | at q 查询的别名 |
| -d | at rm 删除的别名 |
| -v | 显示任务将被执行的时间 |
| -c | 打印任务的内容到标准输出 |
| -V | 显示版本信息 |
| -q <队列> | 使用指定的队列 |
| -f <文件> | 从指定文件中读取任务而不是从标准输入中读取 |
| -t <时间参数> | 以时间参数的形式提交要运行的任务 |
3、at 时间定义
at 指定时间的方法:
- 接受在当天的
hh:mm(小时:分钟)式的时间指定。假如该时间已过去,那么就放在第二天执行。 例如:04:00,表示在当天的 4点整执行一次。 - 使用 midnight(深夜),noon(中午),teatime(饮茶时间,一般是下午 4 点)等比较模糊的词语来指定时间。
- 采用 12 小时计时制,即在时间后面加上AM(上午)或 PM(下午)来说明是上午还是下午。 例如:12pm,表示凌晨12点。
- 指定命令执行的具体日期,指定格式为month day(月 日)或 mm/dd/yy(月/日/年)或 dd.mm.yy(日.月.年),指定的日期必须跟在指定时间的后面。 例如:04:00 2021-03-1
- 使用相对计时法。指定格式为:
now + count time-units,now就是当前时间,time-units 是时间单位,这里能够是minutes (分钟)、hours(小时)、days(天)、weeks(星期)。count 是时间的数量,几天,几小时。 例如:now + 5 minutes,表示5分钟后执行一次。 - 直接使用 today(今天)、tomorrow(明天)来指定完成命令的时间。
4、应用实例
# 查询系统中没有执行的任务(以下两条命令等价)
atq
at -l
# 案例一:设置三天后的下午5点执行命令, ls /home
# 注意,如果在这里输入错误,想要删除的话,按住Ctrl+删除键。
at 5pm + 2 days
at> /bin/ls /home
# 案例二:设置明天 凌晨3点钟,输出时间到指定文件内
at 3am tomorrow
at> date > /home/mydate.txt
# 案例三:设置2分钟后,输出时间到指定文件内
at now + 2 minutes
at> date > /home/mytime.txt
# 案例四:使用脚本执行定时任务,输出日历到指定文件中
# 编辑脚本
vim test.sh
cal > mytest.txt
# 给脚本赋予执行的权限
chmod u+x test.sh
# 设置定时任务
at now + 1 minutes
at> /home/test.sh
# 删除定时任务(一下两条指令等价)
atrm 任务编号
at -d 任务编号
2. 磁盘分区
2.1 Linux分区
(1)Linux中分区的概念
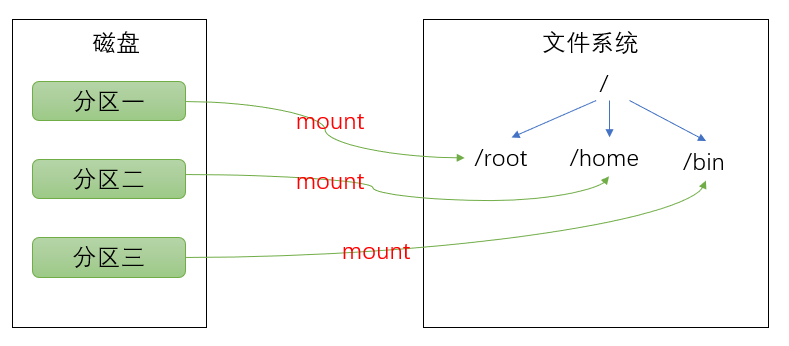
- Linux 来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构 , Linux 中每个分区都是用来组成整个文件系统的一部分。
- Linux 采用了一种叫 “载入” 的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录 联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得。
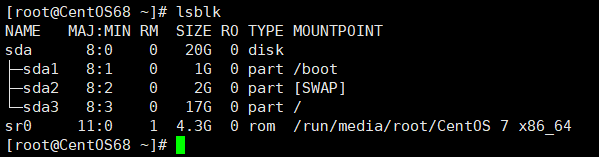
# 查看当前系统的分区情况(怎么记这个命令?老sb唠嗑)
lsblk
(2)Linux硬盘类型
Linux 硬盘分 IDE 硬盘和 SCSI 硬盘,目前基本上是 SCSI 硬盘。
- IDE硬盘:驱动器标识符为 hdx~ 。
hd:表明分区所在设备的类型,这里是指 IDE 硬盘。x:为盘号- a 为 基本盘
- b 为基本从属盘
- c 为辅助主盘,
- d 为辅助从属盘)
~:代表分区。- 前四个分区用数字 1 到 4 表示,它们是主分区或扩展分区
- 从 5 开始就是逻辑分区。
- 例:
hda3表示为第一个 IDE 硬盘上的第三个主分区或扩展分区。hdb2表示为第二个 IDE 硬盘上的第二个主分区或扩展分区。
- SCSI 硬盘:标识为 sdx~ 。
sd:表示分区所在设备的类型的,这里是指 SCSI 硬盘。- 其余则和 IDE 硬盘的表示方法一样
# 查看设备的挂载详细情况
lsblk -f

2.2 增加硬盘
(1)步骤:
- 虚拟机添加硬盘
- 分区
- 格式化
- 挂载
- 设置可以自动挂载
(2)具体添加硬盘的步骤如下:
1、点击设置
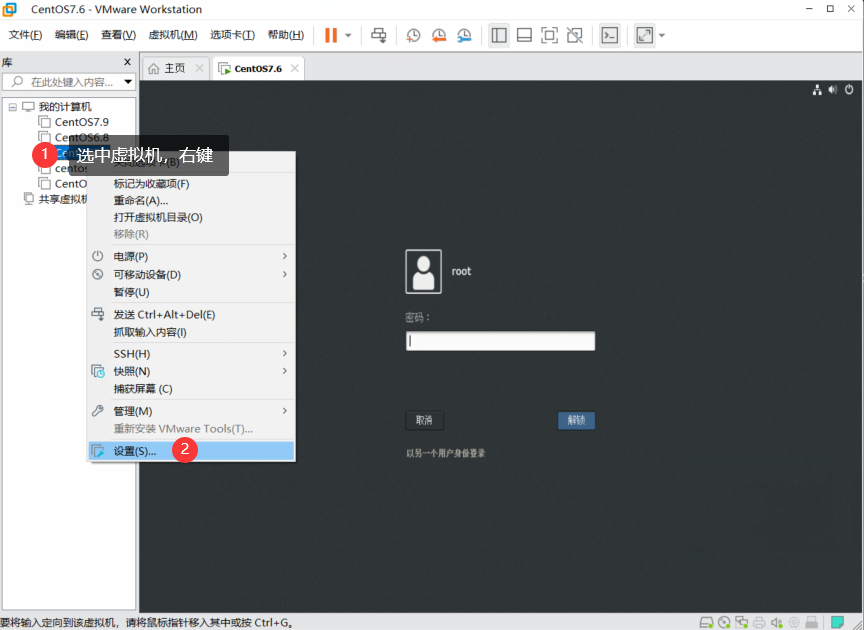
2、选中硬盘,点击添加。
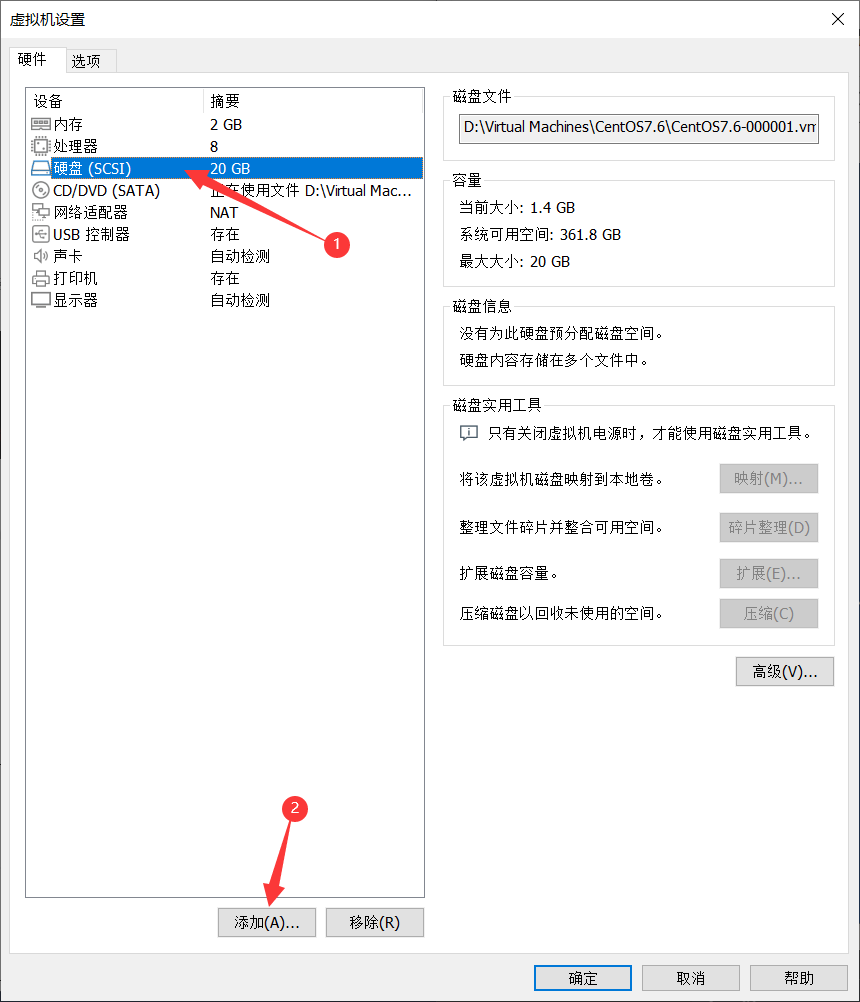
3、选中硬盘,点击下一步。

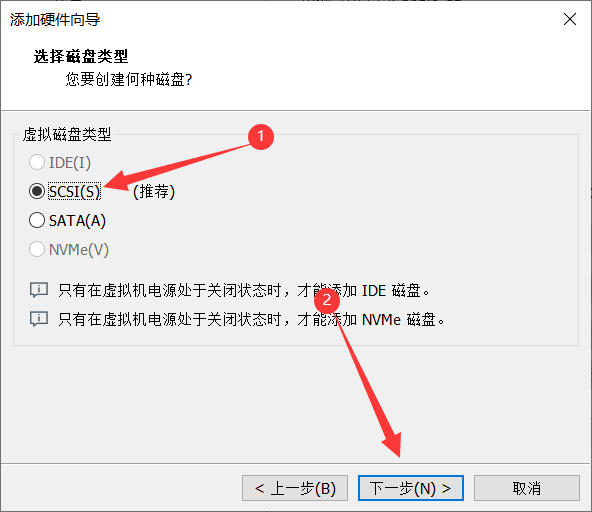
4、选择磁盘类型为 SCSI,下一步。
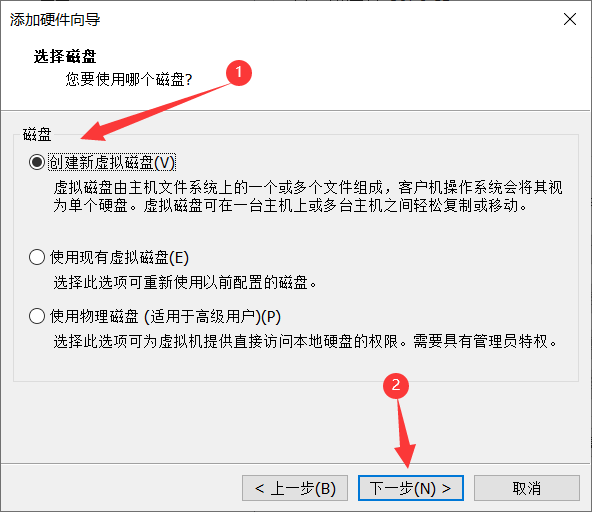
5、创建新的虚拟磁盘
6、设置磁盘容量。
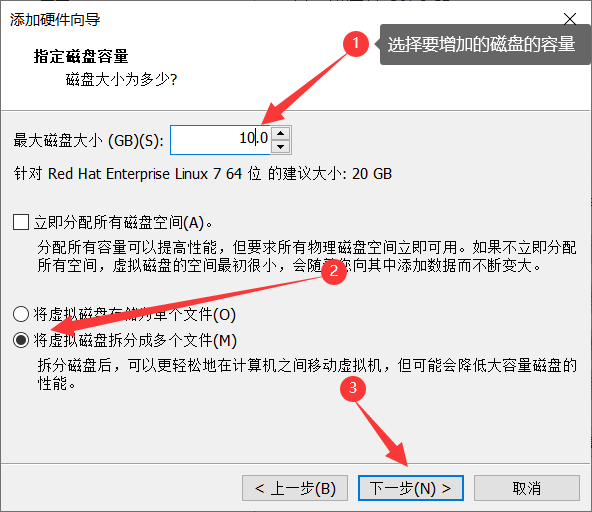
7、指定磁盘文件(默认即可)
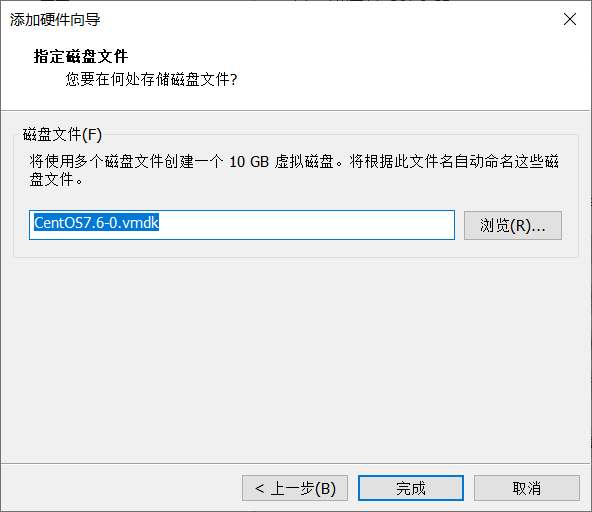
8、可以看到这里多了个新硬盘,点击确定。
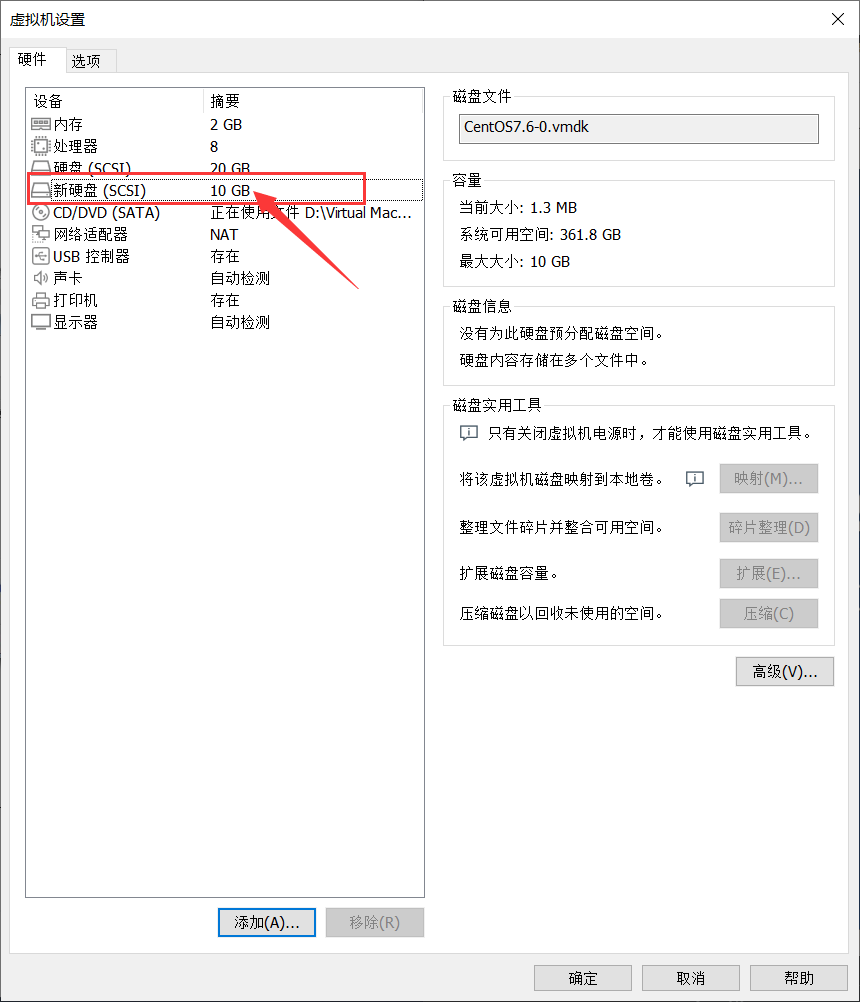
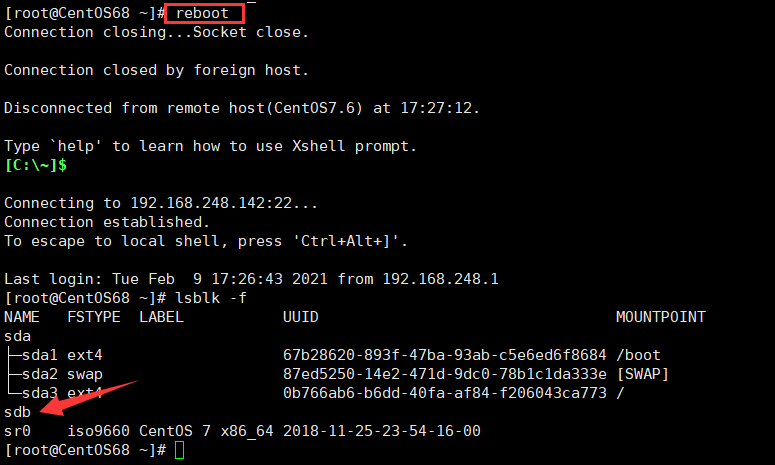
9、然后重启系统即可识别到新硬盘。
- 我们可以看到新增的磁盘的编号是
sdb,因为我们的第一块磁盘编号是sda。 - 现在还没有分区,所以只能看到是一块单独的磁盘。
(3)给新增的磁盘分区
# 分区命令
fdisk /dev/磁盘编号
例:fdisk /dev/sdb
输入分区命令,显示如下,
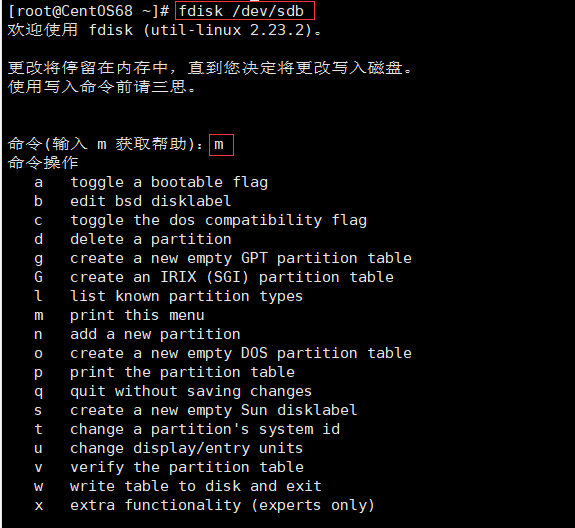
常用操作:
| 操作 | 含义 |
|---|---|
| m | 显示帮助信息 |
| d | 删除分区 |
| q | 直接退出,不保存修改 |
| n | 添加一块新的分区 |
| w | 保存退出 |
| p | 显示磁盘分区,等同于 fdisk –l |
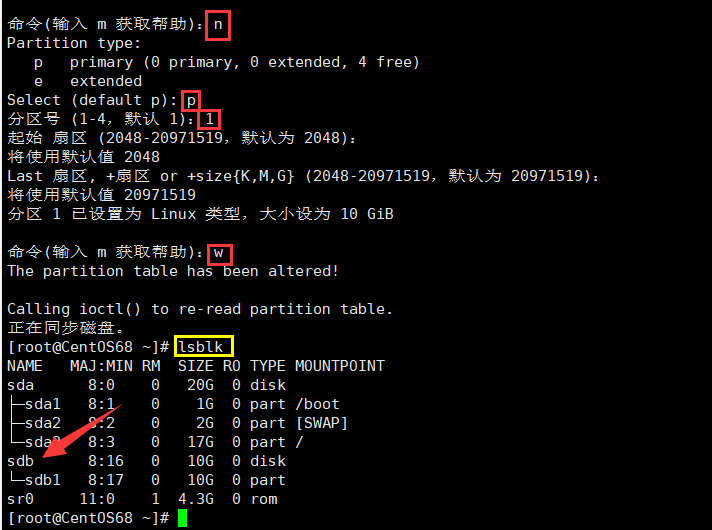
说明:
- 开始分区后输入 n,新增分区,然后选择 p ,分区类型为主分区。两次回车默认剩余全部空间。最后输入w 写入分区并退出,若不保存退出输入 q。
现在有了分区之后,还不能直接挂载,需要进行格式化。格式化的原因是要给这个分区指定它的文件类型。
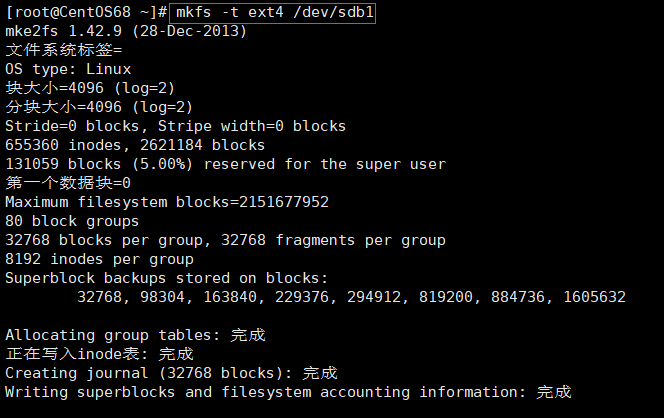
(4)格式化分区
# 分区命令,文件类型一般为 ext4,分区编号就是上面执行分区时生成的编号。
mkfs -t 文件类型 /dev/分区编号
# 例
mkfs -t ext4 /dev/sdb1
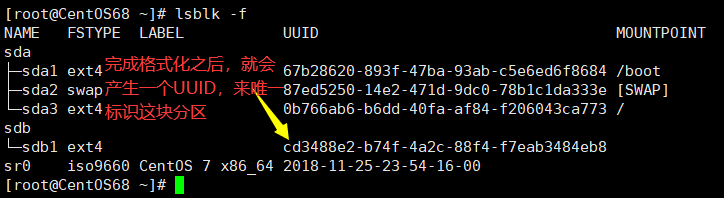
格式化完成之后,系统就会生成一个UUID,来唯一标识这块分区。
(5)挂载
我们在根目录下创建一个目录,/mydisk,来挂载这块分区。因为Linux中将一个分区和一个目录联系起来,打开一个目录,就相当于进入一块分区。
挂载:就是将一个目录和分区联系起来。
# 先切换到根分区(这里不一定分要挂载到根分区下,也可以挂载到/home或/root下)
cd /
# 创建一个目录
mkdir mydisk
# 挂载分区
mount /dev/sdb1 /mydisk
挂载完毕之后,我们在查看系统分区情况。可以发现新的分区已经有了挂载点。
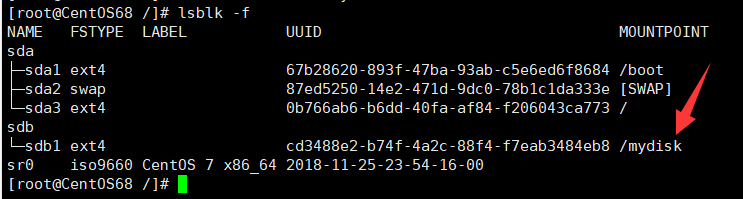
卸载分区,分区中的内容不会被删除。
# 卸载命令
umount 设备名称或挂载目录
# 例
umount /dev/sdb1
umount /mydisk
注意:用命令行挂载的方式,Linux系统重启之后就会失效。
(6)设置为永久挂载
编辑 /etc/fstab 文件实现永久挂载。
# 编辑 /etc/fatab 文件,实现永久挂载
vim /etc/fstab
这里可以写分区的UUID,也可以写分区编号(例:/dev/sdb1 )。
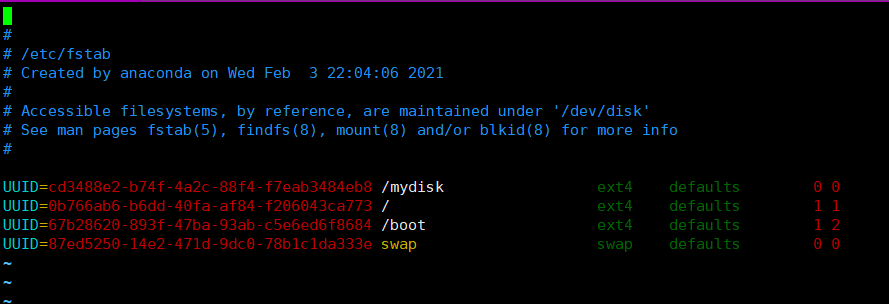
# 添加完成后 执行以下命令,使挂载即刻生效
mount –a
2.3 磁盘情况查询
在Linux的使用过程中,随着我们不断的给Linux系统中添加上传文件,它的磁盘空间肯定是越来越少的,因此,我们应该实时掌握磁盘的使用情况,以做出相应操作,如:增加磁盘、增加分区等。
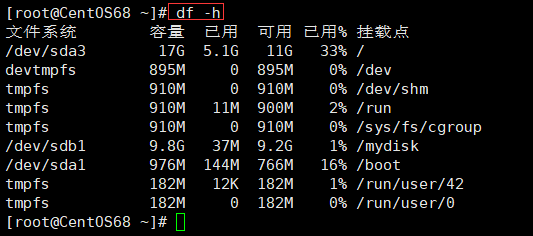
查询系统整体磁盘使用情况:
# 查看的命令如下
df -h
查看指定目录的磁盘使用情况
# 如果不指定目录,则默认查看当前目录的磁盘使用情况
du [选项]
# 指定目录
du -h /home
常用选项:
| 选项 | 含义 |
|---|---|
| -h | 显示时加上单位,k |
| -s | 指定目录占用大小汇总 |
| -a | 含文件 |
| -c | 列出明细的同时,显示汇总值 |
| –max-depth=num | 指定子目录深度为num |
# 查询 /home 目录的磁盘占用情况,深度为 1
du -hac --max-depth=1 /home
2.4 实用指令
# 统计数据
wc
1、统计目录下文件的个数
# Linux的命令是支持正则表达式的。因此可以使用其模糊匹配。
# 显示 /root 目录下文件的个数,使用 wc 指令统计数量。
# 因为文件是以 - 开头的
ls -l /root | grep "^-" | wc -l
2、统计目录下目录的个数
# 统计 /root 目录下目录的个数
ls -l /root | grep "^d" | wc -l
3、统计目录包括子目录中文件的个数
# R 表示递归的意思
ls -lR /root | grep "^-" | wc -l
4、以树状显示目录下的文件及目录结构
tree 目录
例:tree /root
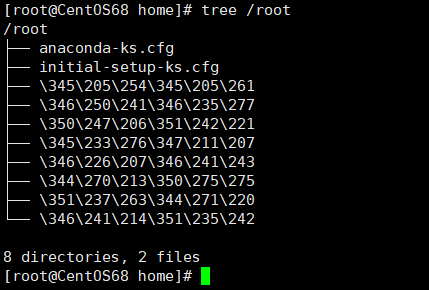
注意,Linux中默认是没有 tree 指令的,我们需要手动安装一下。安装指令如下:
# 安装的前提是Linux系统需连通外网。可以是 ping 命令检测一下。
yum install tree
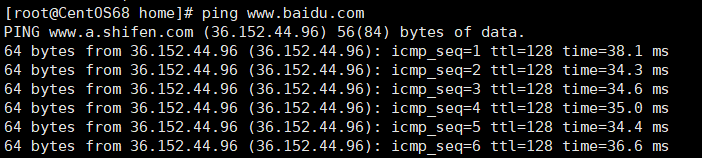
# ping 百度
ping www.baidu.com
出现以下内容则表示网络畅通。
3. 网络配置
3.1 网络概述
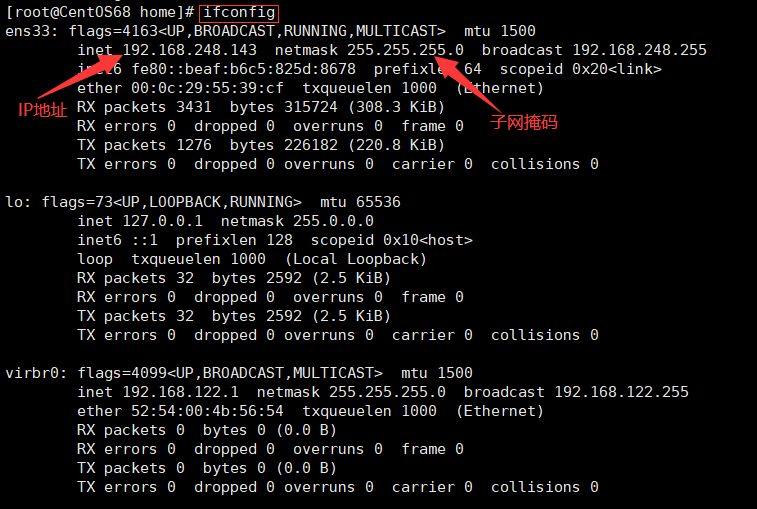
1、Linux下查看IP地址
ifconfig
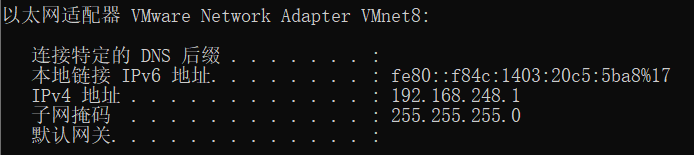
2、Windows下查看IP地址。
NAT网络连接模式下,Linux和Windows母机的通信是通过VMNet 8 完成的。
ipconfig
(1)NAT网络配置原理图
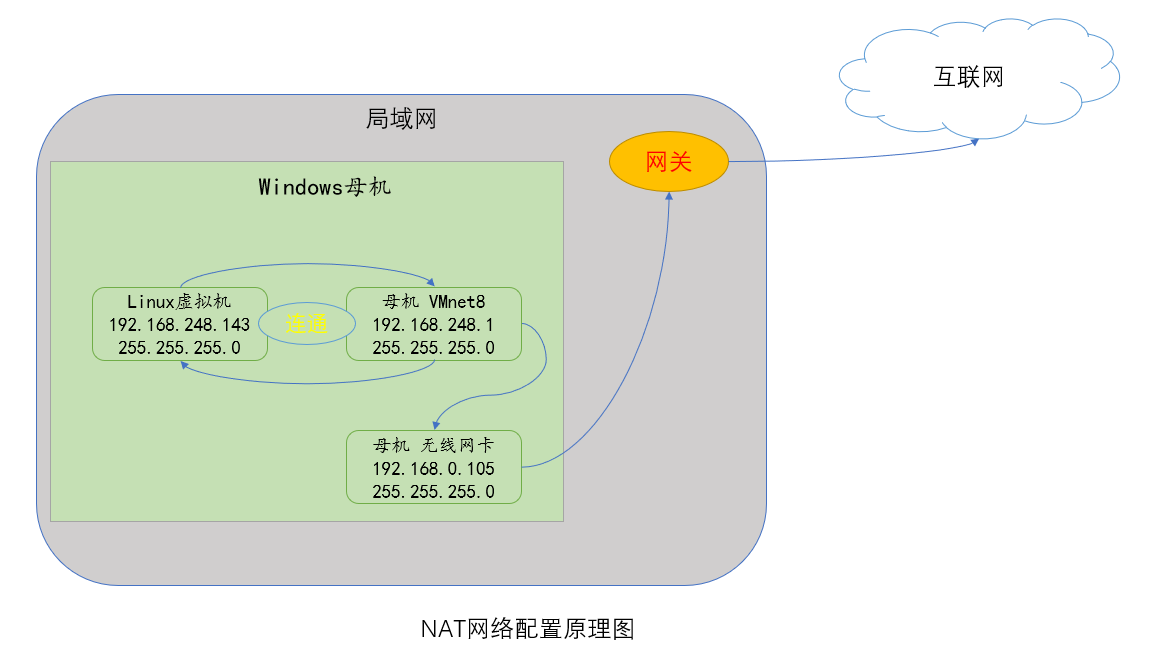
注意:如果你的Windows母机和Linux虚拟机是在同一网段下,但是出现互相 ping 不通的情况,可以尝试将Windows的防火墙关闭。
Linux的IP地址的网段是可以指定的。
(2)查看虚拟网络编辑器
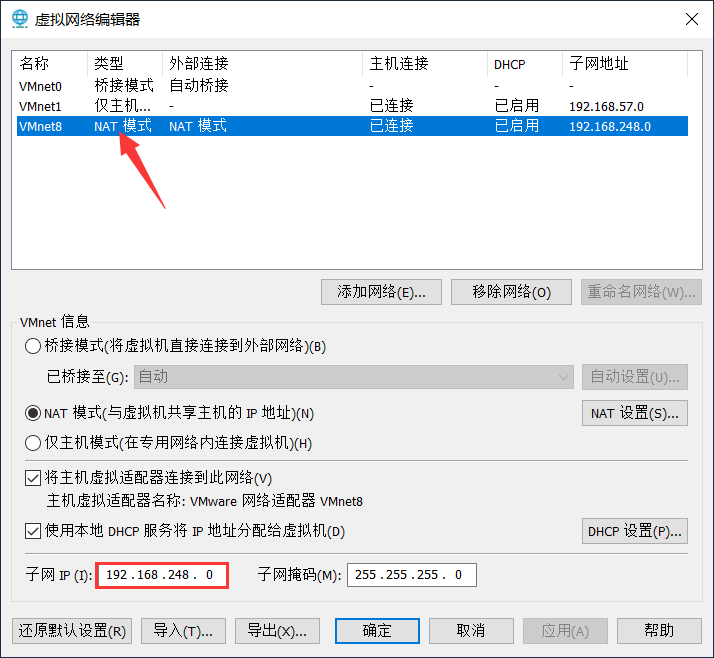
(3)测试网络连通性
# 测试当前主机是否可用连通目的主机
ping 目的主机的IP
# 测试当前主机是否可以连通互联网
ping www.baidu.com
3.2 网络配置
(1)第一种配置方法—自动获取
- 优点:可以自动规避IP冲突。
- 缺点:Linux每次重启后自动获取的IP地址可能会不同,这样就无法做服务器使用。
1、打开Linux的网络设置
2、修改网络设置
3、修改网络连接方式为自动获取
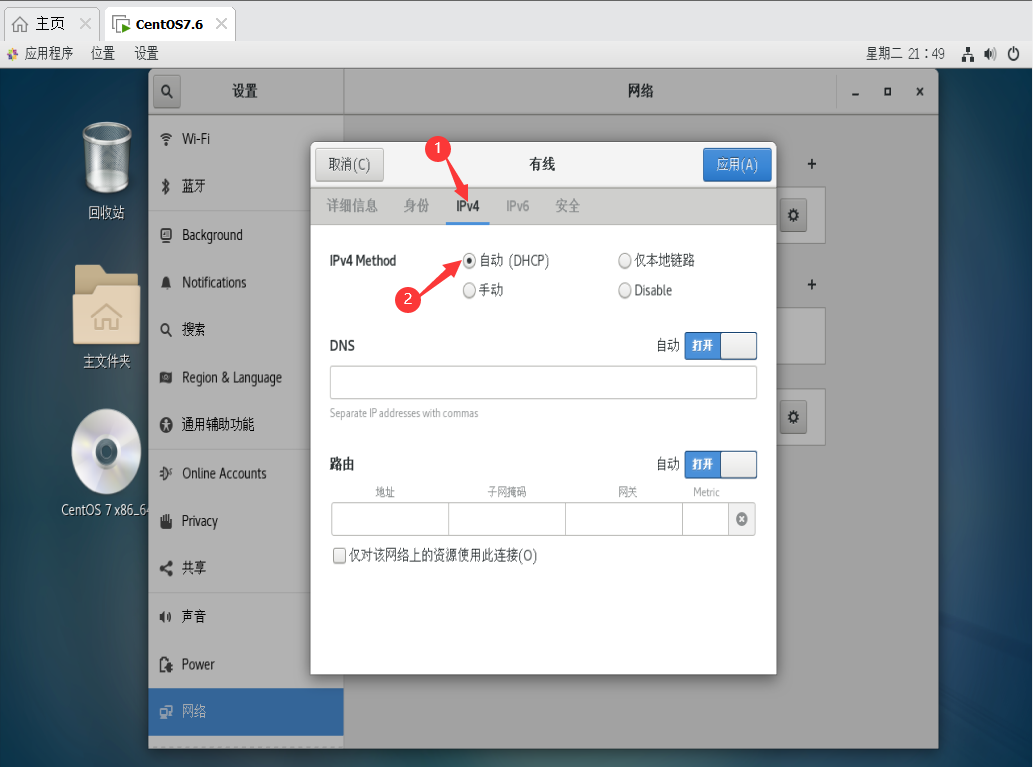
(2)第二种配置方法—指定IP
ifcfg-ens33 文件参数说明
# 网络类型,通常是 Ethernet,一般还有bond,bridge
TYPE="Ethernet"
# 是否允许非root用户控制该设备
USERCTL=no
PROXY_METHOD="none"
BROWSER_ONLY="no"
# IP的配置方法(none/static/bootp/dhcp)
# none 引导时不使用协议
# static 静态IP
# bootp BOOTP协议
# dhcp 动态分配
BOOTPROTO="dhcp"
# 是否设置默认路由
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
# IPV6 是否有效,(yes/no)
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
# 这个参数对应的值是网卡名,是给用户看的
NAME="ens33"
# 随机id
UUID="7415a862-a57f-44c7-8946-6a5ee37621ee"
# 接口名(设备、网卡)
DEVICE="ens33"
# 系统启动的时候网络接口是否有效(yes/no)
ONBOOT="yes"
# IP地址(static时使用)
IPADDR=192.168.100.140
#网关 (static时使用)
GATEWAY=192.168.100.2
#域名解析器 (static时使用)
DNS1=192.168.100.2
ens33 就类似于网卡
第一步:修改Linux的IP地址。
- 通过编辑修改
/etc/sysconfig/network-scripts/ifcfg-ens33该文件实现
# 修改 ifcfg-ens33 文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
-
在
ifcfg-ens33文件中做如下修改 -
将
BOOTPROTO="dhcp"由 dhcp 改为 static 。 -
再在文件中添加一下内容:
# IP地址,这里指定为 192.168.200.130
IPADDR=192.168.200.130
#网关,这里指定为 192.168.200.2
GATEWAY=192.168.200.2
#域名解析器,这里指定为 192.168.200.2
DNS1=192.168.200.2
第二步:修改 VMNet 8 的网络IP
- 打开 VMware的 虚拟网络编辑器进行修改。
- 将子网IP 修改为和刚才指定的Linux的IP地址在同一网段下。
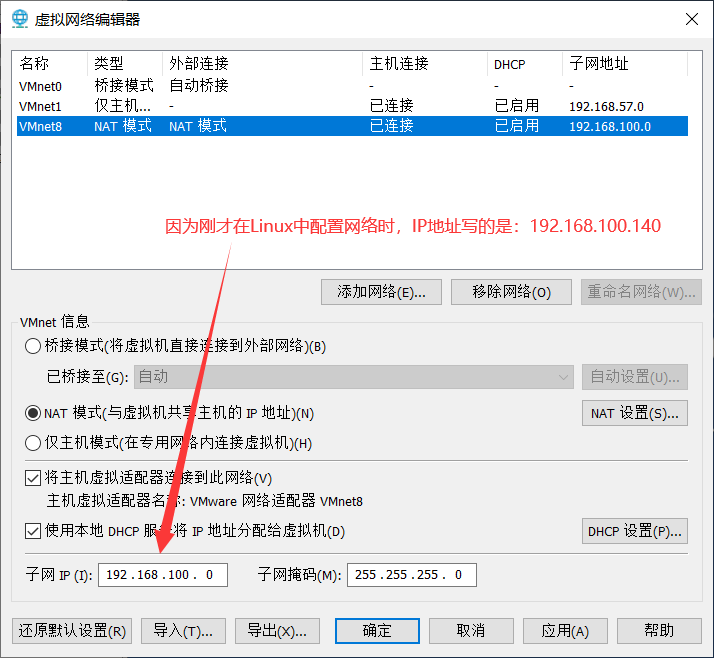
- 修改VMNet 8 的网关。
- 将网关也修改为刚才
ifcfg-ens33文件中的网关。
- 将网关也修改为刚才
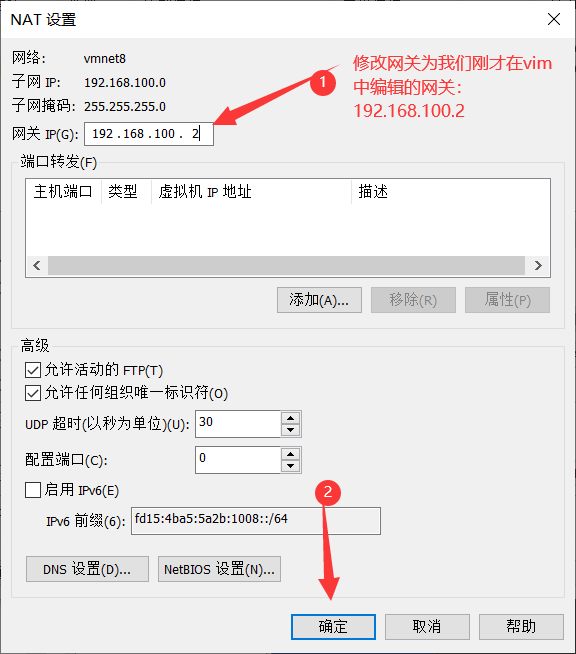
- 重启网络服务 或 重启Linux系统,使配置生效。
# 重启网络服务
service network restart
重启之后,查看Linux的IP地址。
- 可以验证我们刚才的配置生效了
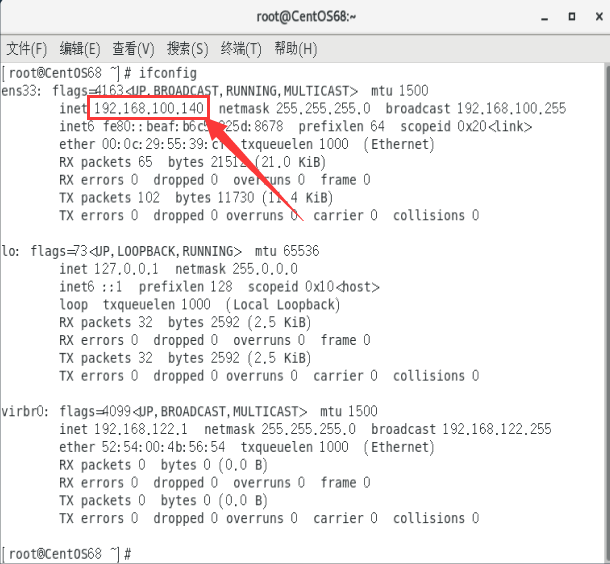
再查看 VMNet 8 的IP地址。配置同样生效。
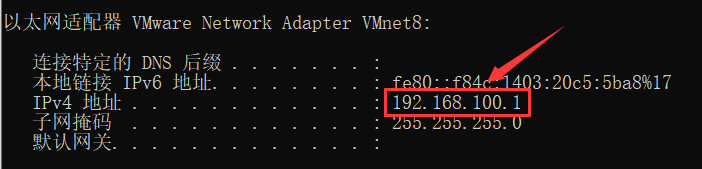
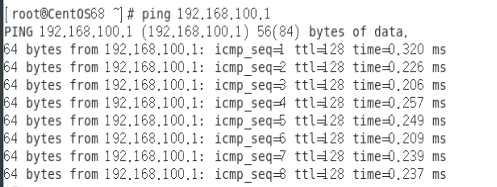
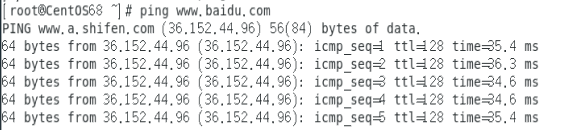
使用 ping 命令检测 Linux和 Windows以及互联网的连通性。
- Windows是可以 ping 通Linux虚拟机的
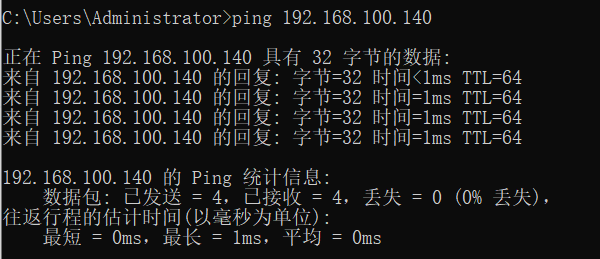
- Linux也是可以 ping 通Windows的
- Linux也是可以 ping 通互联网的,这里以百度为例。
3.3 host 映射
(1)设置主机名
疑问一:IP地址就可以标识一台主机,为什么要设置主机名呢?
- 原因很简单:因为懒,不想记那么长的IP地址。因此可以给主机设置主机名,方便记忆。
# 查看主机名
hostname
疑问二:如何设置或修改主机名呢?
- 通过修改文件
/etc/hostname,在该文件中指定。
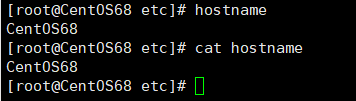
# 先查看一下 /etc/hostname 文件,也是显示当前主机名
cat /etc/hostname
# 编辑修改 /etc/hostname 文件
vim /etc/hostname
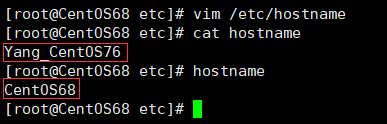
上图中,可以看到主机名已修改完成,但是还没有生效,需要重启系统才能生效。
reboot
(2)设置 host 映射
疑问三:设置完主机名之后,就能使用主机名来标识一台主机吗?我们可以使用 ping 命令测试一下

可以看到,现在是不能 ping 通的,原因很简单,现在还没有做 host 映射,Windows母机还不知道 Yang_CentOS76 代表的是哪个主机,因为它只是一个名字,这个名字是可以重复的。
因此我们需要明确的告诉系统,这个名字是指向哪个主机的。
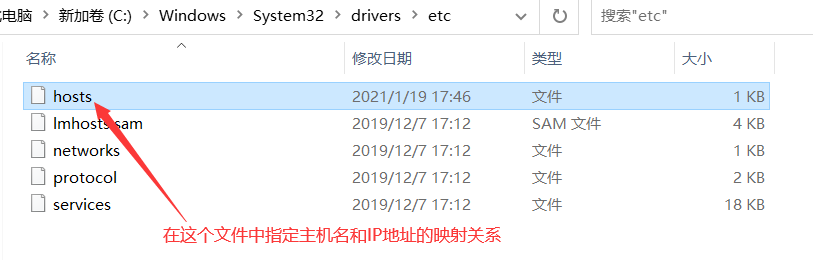
- 在 Windows 中指定host映射:指定我们刚才设置的Linux主机名
- 在文件:C:\Windows\System32\drivers\etc\hosts 中指定。
- 指定之后,如果执行
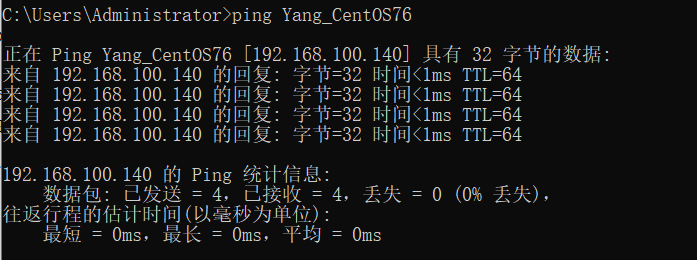
ping Yang_CentOS76,系统就会先在host文件中找 Yang_CentOS76 对应的是哪个主机。
设置完成之后,在 Windows中就可以ping 通 Linux主机了
- 在 Linux中 指定Windows主机名:
- 在
/etc/hosts文件中指定。 - 这里指定的Windows主机名可以任意,它只是和Windows的VMNet 8 的IP地址绑定。
- 比如:我这里指定 Windows的主机名为:Yang。以后我们在Linux中
ping Yang就相当于ping 192.168.100.1
- 比如:我这里指定 Windows的主机名为:Yang。以后我们在Linux中
- 在

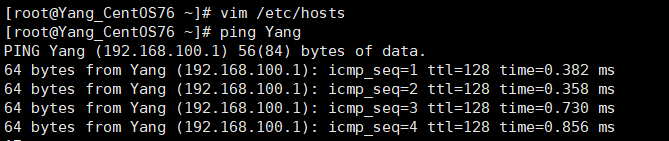
(3)主机名解析
- Hosts:Linux中的一个文本文件,用来记录 IP 和 Hostname(主机名)的映射关系。
- DNS:就是Domain Name System的缩写,翻译过来就是域名系统,是互联网上作为域名和 IP 地址相互映射的一个分布式数据库。
例:用户在浏览器访问百度(www.baidu.com),就会经历以下过程:
- 浏览器先检查浏览器缓存中有没有该域名对应的 IP 地址。
- 如果有,就直接使用 IP 完成解析。
- 如果没有,就转到第二步。
- 检查DNS 解析器缓存。
- 如果有直接返回 IP 完成解析。
- 如果没有,就转第三步。
- 检查系统中 hosts 文件中有没有配置对应的域名 IP 映射。
- 如果有,则返回IP,完成解析,
- 如果没有,则执行第四步。
- 到域名服务DNS 进行域名解析。
- 如果有,就返回该IP,完成解析。
- 如果没有,则返回域名不存在。
图解如下:
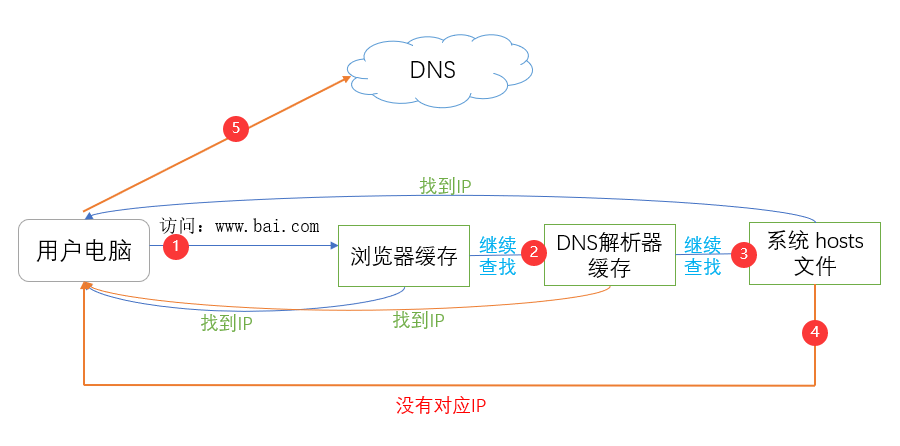
浏览器缓存和DNS解析器缓存,,可以理解为本地解析器缓存。
一般来说,当电脑第一次成功访问某一网站后,在一定时间内,浏览器或操作系统会缓存他的 IP 地址(DNS 解析记 录)
可以在 cmd 窗口中使用命令查询:
# 查看DNS域名解析缓存
ipconfig /displaydns
# 清除电脑的域名缓存
ipconfig /flushdns
(4)域名劫持
如果非法修改了Hosts文件,就形成了域名劫持。
如下:
# 在 hosts 文件中加一行
192.168.100.140 www.baidu.com
我们 ping 的明明是 www.baidu.com,但实际上是ping 向我们刚才配置的IP。
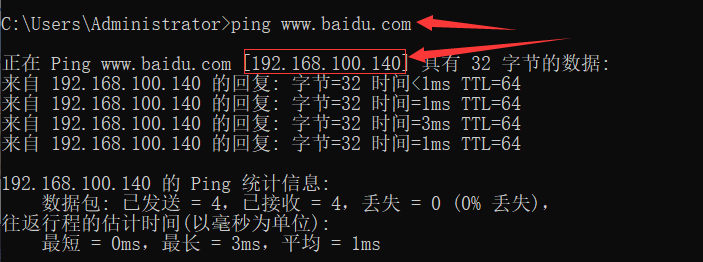
试想一下,如果黑客入侵我们电脑,修改了hosts文件,将我们访问的网站换成了他的钓鱼网站……
不过不用担心,黑客入侵也没那么容易
4. 进程管理
4.1 进程概述
(1)进程与程序:
- 进程是程序的一次运行过程,是系统资源分配和系统调度的基本单位。
- 进程是动态的,程序是静态的。(进程是暂时的,程序是永久的)。
- 将程序装入内存执行就形成了进程。
- 进程由三部分组成:
- 程序段:因为一个程序可能会很大,不可能全部装入内存。
- 数据:程序运行所需要的数据。
- PCB(进程控制块):包含进程执行所需要的控制信息。
(2)Linux进程
-
在Linux中,每个执行的程序都称为一个进程。每一个进程都分配一个 ID号(pid,进程号)。
-
每个进程都可能以两种方式存在的。
-
前台:所谓前台进程就是用户目前的屏幕上可以进行操作的。
-
后台:后台进程则是实际在运行,但屏幕上无法看到的进程,通常使用后台方式执行。
-
一般系统的服务都是以后台进程的方式存在,而且都会常驻在系统中,直到关机才才结束。
-
Windows中的进程:
- Linux中的进程:

4.2 查看Linux进程
(1)ps相关指令
ps 指令是用来查看目前系统中,有哪些进程,以及他们的执行情况。
# 显示当前终端的所有进程信息
ps -a
# 以用户的格式显示进程信息
ps -u
# 显示后台进程
ps -x
# 一般情况下,都进行组合使用,如下:
ps -axu

说明:
USER:进程执行用户PID:进程号%CPU:当前进程占用CPU的百分比%MEM:当前进程占用内存的百分比VSZ:进程占用的虚拟内存大小(单位:KB)RSS:进程占用的物理内存大小(单位:KB)TTY:终端信息STAT:当前进程运行情况- S:睡眠状态。表示正在休眠
- s:表示该进程是会话的先导进程
- N:表示进程拥有比普通优先级更低的优先级
- R:表示正在运行
- Z:表示僵死进程。进程死掉了,但是它占用的内存没有被释放。
- T:表示被跟踪或停止的进程
START:当前进程开始执行的时间TIME:当前进程占用CPU的时间COMMAND:启动进程所用的命令和参数,如果过长会被截断显示
# 以全格式显示当前所有的进程 -e 显示所有进程。-f 全格式
ps -ef
Linux中,一个进程可以生成或创建别的进程,因此就有父进程的概念。
# 查询 sshd 进程的详细信息
ps -ef | grep sshd
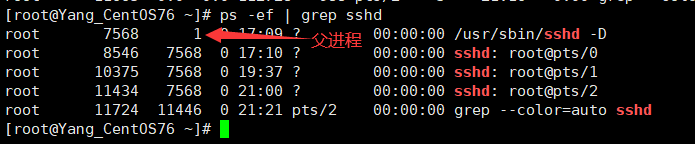
说明:
- PPID:父进程ID,为0表示它没有父进程,它本身就是一个根进程。
- C:CPU用于计算执行优先级的因子。数值越大,表明进程是 CPU密集型运算,执行优先级会降低;数值越小,表明进程是 I/O密集型运算,执行优先级会提高。
- CMD:等同于上面的COMMAND。
(2)查看进程树
# 以树状图显示进程关系
pstree [选项]
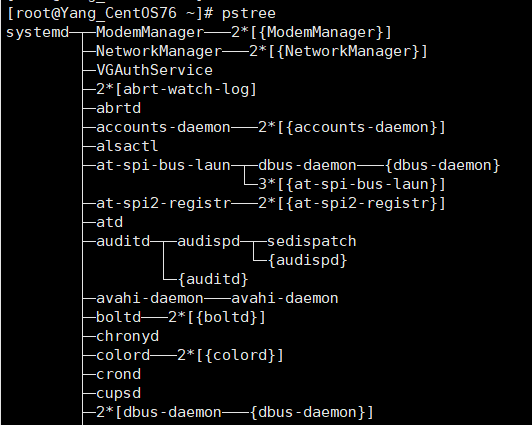
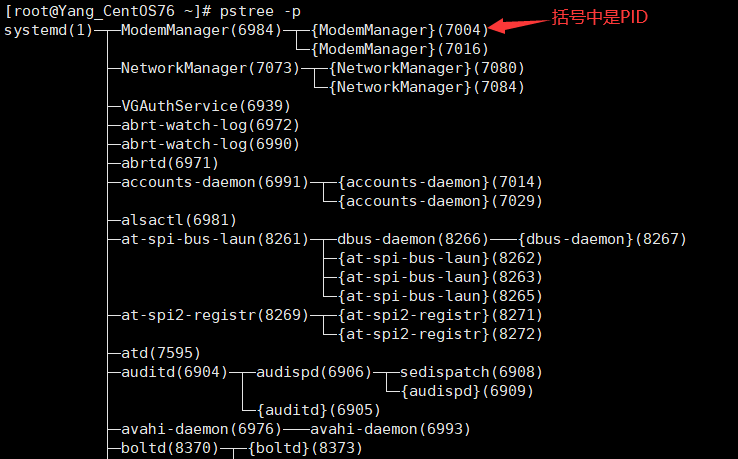
常用选项:
-p:显示进行的PID。-u:显示进程所属用户。
pstree -p
4.3 终止进程
若是某个进程执行一半需要停止时,或是已消了很大的系统资源时,此时可以考虑停止该进程。使用 kill 命令来完成此项任务。
# 通过进程号终止进程
kill [选项] 进程号
# 通过进程名终止进程,同时终止该进程的子进程,也支持通配符的使用。
killall 进程名称
常用选项:
-9:强制终止一个进程。
sshd服务就是支持远程登录的一个服务。
# 案例一:踢掉某个非法用户
# 先使用 ps 指令查询到该用户登录使用的 sshd 的进程号
ps -ef | grep sshd
# 再使用 kill 指令终止该进程
kill 进程号
# 案例二:终止远程登录服务 sshd, 在适当时候再次重启 sshd 服务
# 先使用 ps 指令查询 sshd 的进程号
ps -ef | grep sshd
# 再使用 kill 指令终止该进程
kill 进程号
# 重启 sshd 服务
/bin/systemctl restart sshd.service
# 案例三:终止多个 gedit 进程,该进程是Linux下的文本编辑器的进程
killall gedit
# 强制终止一个进程,我们在虚拟机中打开两个终端,然后使用一个终端去关闭另外一个终端的进程,终端的进程名是 bash
kill -9 进程号
4.4 服务管理
(1)服务的概念
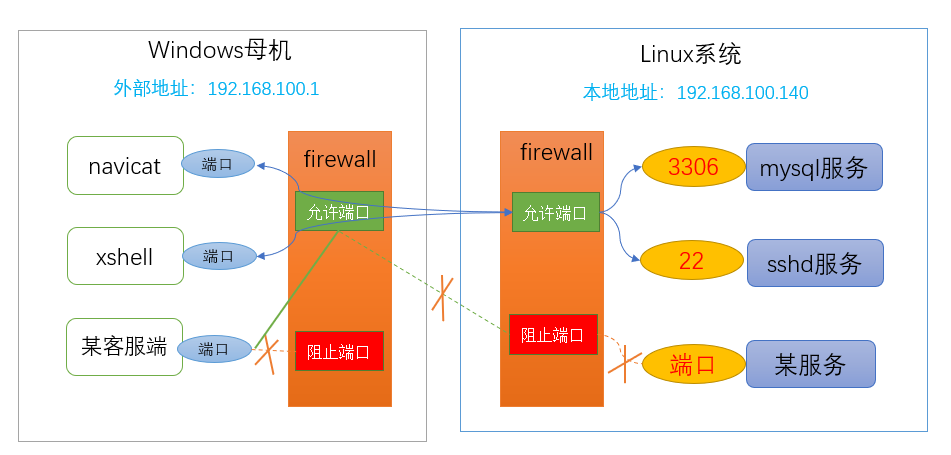
服务(service) 本质就是进程,它一般是运行在后台的,通常都会监听某个端口,等待其它程序的请求,比如:mysql监听3306端口,sshd监听22端口,因此我们又将这些进程称为守护进程。
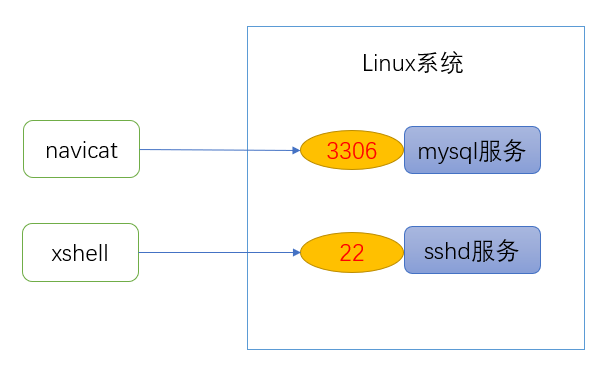
监听端口,就可以理解为打开一个耳朵,时刻探测有没有人发起请求。
(2)service管理指令
# 服务的 启动、停止、重启、重新加载、查看状态
service 服务名 [start | stop | restart | reload | status]
注意:在 CentOS7.0 后 很多服务不再使用 service ,而是systemctl 。
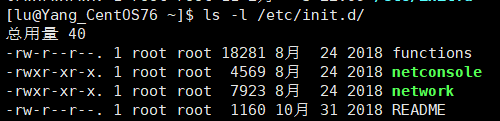
查看哪些服务还可以被 service 指令管理,使用如下命令进行查看:
# 在 /etc/init.d/ 目录下
ls -l /etc/init.d/
可以看到有如下几条服务可以使用 service 指令管理:
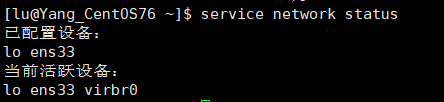
比如,查看 network 的状态:
service network status
# 重启 network 服务
service network restart
# 停止 network 服务
service network stop
# 启动 network 服务
service network start
(3)查看服务名
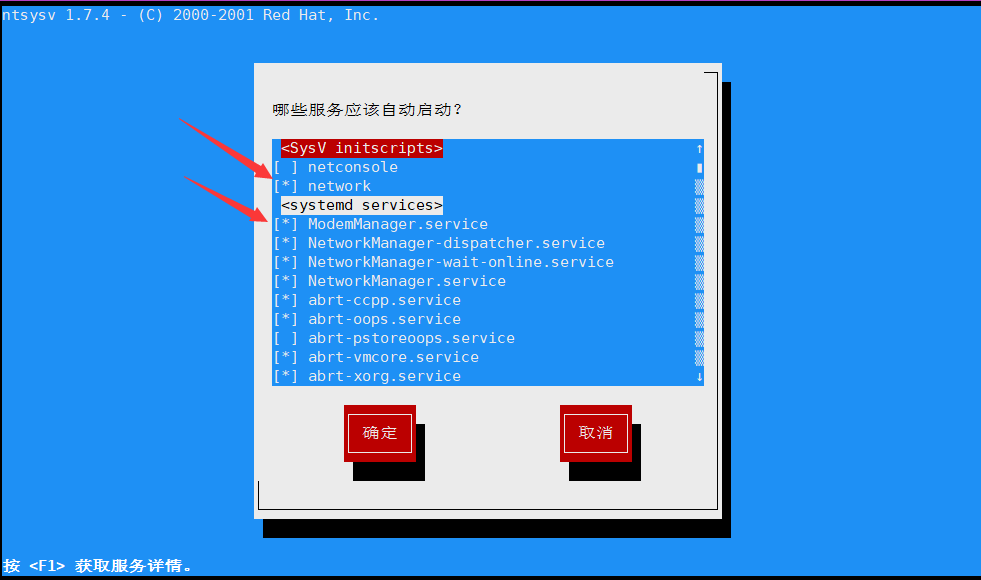
方式一:使用 setup 指令,查看所有服务
setup
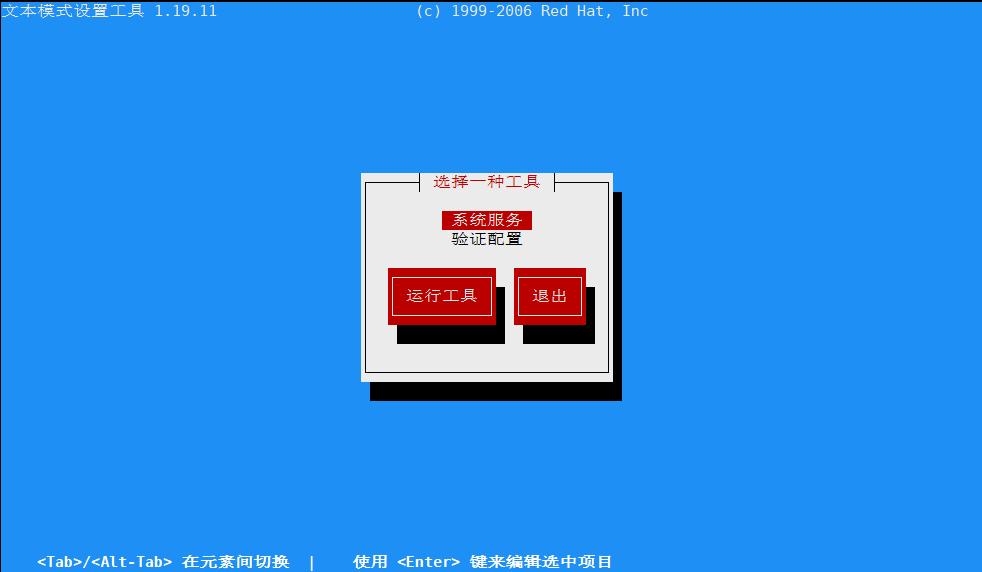
前面显示 * 星号的,表示在Linux系统启动的时候,会自动启动。
停止服务:
- 将光标停在某个服务的上,按下空格键。
- 再按下确定键,就停止了该服务。
方式二:查看 service 管理的指令
ls -l /etc/init.d/
开机流程:

4.5 chkconfig 指令
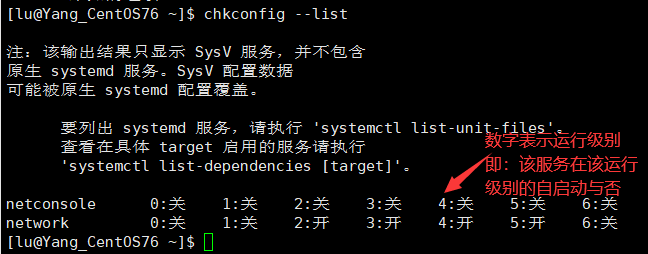
(1)复习 Linux中的运行级别:
由前面的学习可知,Linux中有7个运行级别:
- 运行级别 0:系统停机状态,系统默认运行级别不能设为 0,否则不能正常启动 。
- 运行级别 1:单用户工作状态,root 权限,用于系统维护,禁止远程登陆。
- 运行级别 2:多用户状态(没有NFS),不支持网络 。
- 运行级别 3:完全的多用户状态(有NFS),无界面,登陆后进入控制台命令行模式 。
- 运行级别 4:系统未使用,保留 。
- 运行级别 5:X11 控制台,登陆后进入图形GUI 模式 。
- 运行级别 6:系统正常关闭并重启,默认运行级别不能设为 6,否则不能正常启动。
# 查看当前系统运行级别
systemctl get-default
# 这是默认运行级别
# multi-user.target 表示运行级别 3
# graphical.target 表示运行级别 5
systemctl set-dafault xxx.target
(2)chkconfig 指令
作用:通过 chkconfig 命令可以给服务的各个运行级别设置 自启动/关闭。即:指定某个服务在哪个运行级别是自启动的,在哪个级别是关闭的。
chkconfig 指令和 service 指令一样,可以在 /etc/init.d/ 目录下查看它所能管理的指令。因为在 CentOS 7 之后,更多的指令是通过 systemctl 指令管理的。
# 查看 chkconfig 指令管理的服务在7个级别中的状态
chkconifg --list
# 指定某个服务在某个运行级别是否自启动
chkconfig --level 运行级别对应的数字 服务名 on/off
# 案例: 把 network在 3 运行级别,关闭自启动。重启系统生效。
chkconfig --level 3 network off
# network在 3 运行级别,自启动
chkconfig --level 3 network on
4.6 systemctl 指令
(1)systemctl 指令
# 基本语法,设置服务的 启动、停止、重启、重新加载、查看状态
systemctl [start | stop | restart | status] 服务名
systemctl 指令管理的服务在 /usr/lib/systemd/system 查看
ll /usr/lib/systemd/system
# 查看当前各个服务的启动状态
systemctl list-unit-files [ | grep 服务名]
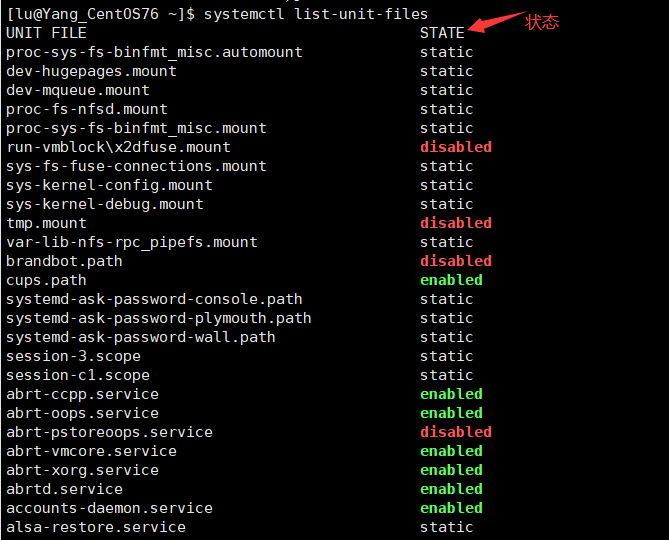
说明:
- enable:开机自启动。
- disable:开机不自启。
- static:静态。
# 设置服务开机启动,表示同时设置 3 和 5 两个级别。
systemctl enable 服务名
# 关闭服务开机启动
systemctl disable 服务名
# 查询某个服务是否是自启动的
systemctl is-enabled 服务名
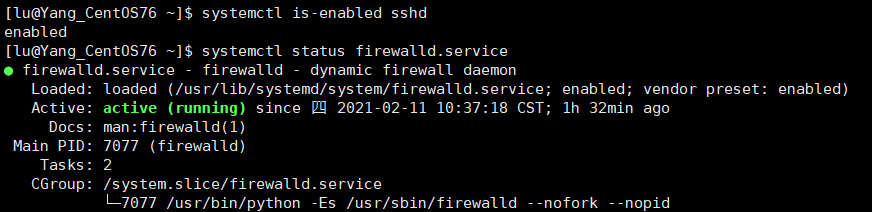
# 案例:查看当前防火墙的状况,
# 先得查询到Linux中防火墙服务的名称。
# 使用如下指令,查询知,防火墙的服务为:firewalld.service
ll /usr/lib/systemd/system | grep fire
# 查看防火墙状态
systemctl status firewalld
# 关闭防火墙
systemctl stop firewalld
# 重启防火墙
systemctl restart firewalld
注意:
- 关闭或启动防火墙之后,它是立即生效的。
- 这种方式只是临时生效,当重启系统后,还是回归以前对服务的设置。
- 如果希望设置某个服务自启动或关闭永久生效,要使用以下指令关闭或开启服务。
systemctl [enable|disable] 服务名
(2)防火墙原理:
请求先到防火墙,如果它将要访问的端口是服务器允许通过的,则该请求可以访问到指定服务。如果它请求的服务的端口是不允许通过的,则该请求不能访问到指定服务。
因此防火墙可以防止我们的系统被恶意的访问。

验证防火墙的作用:
# 查看网络状态
netstat -anp
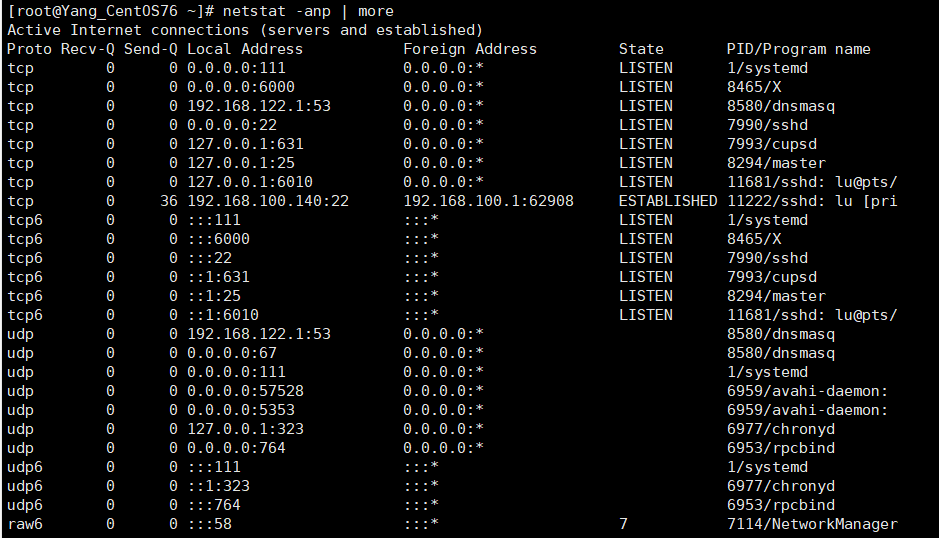
我们可以在 Windows的cmd窗口,尝试访问上图中的一个处于监听状态的端口:
(如果 telnet 指令无法使用,请往下看,后面有解决方案)
# telnet 指令语法
telnet IP地址 端口号
# 例 访问 192.168.100.140 的 111 端口
telnet 192.168.100.140 111
显示连接失败,表示Linux的防火墙是打开的,并且该端口不允许通过。

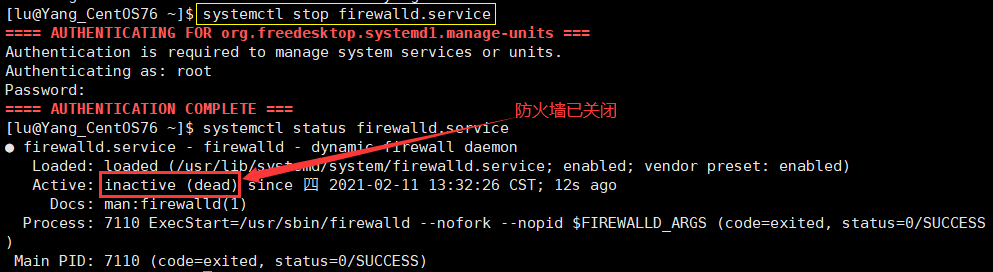
我们现在关闭Linux的防火墙,再次连接该端口,发现可以连接成功。
# 关闭防火墙
systemctl stop firewalld
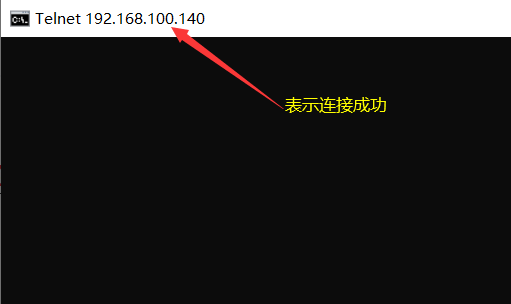
至此,我们就理解了防火墙的基本作用,就是可以防止程序恶意访问我们的系统。
因此在真正的生产环境,往往需要将防火墙打开。
(3)firewall 指令
因此在生产环境下,需要防火墙打开。在这种情况下,如果我们想要访问Linux的某个端口,肯定是不能直接访问的,而我们又不能直接关闭防火墙。
因此可以使用 firewall 指令。
# 打开端口(该命令需要 root 用户才能执行)
firewall-cmd --permanent --add-port=端口号和协议
# 关闭端口
firewall-cmd --permanent --remove-port=端口号和协议
# 不论是打开端口还是关闭端口,都需要重新载入一下才能生效,
firewall-cmd --reload
# 查询端口是否开放
firewall-cmd --query-port=端口/协议
# 查看端口对应的协议
netstat -anp | more
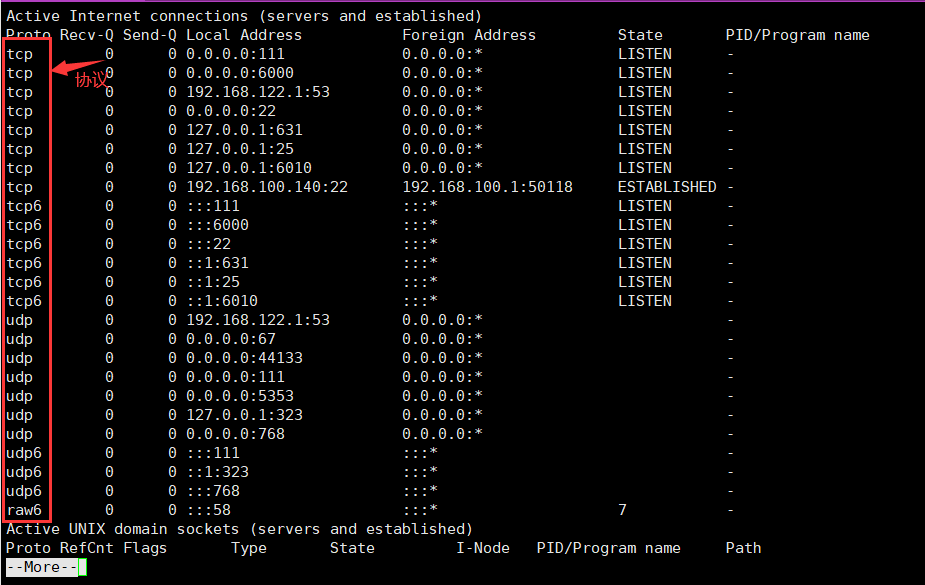
# 案例:打开111端口
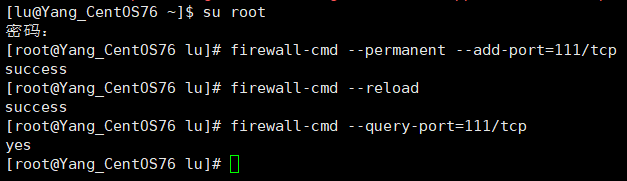
firewall-cmd --permanent --add-port=111/tcp
# 重新载入,使命令生效。
firewall-cmd --reload
# 查询端口状态,显示为 yes
firewall-cmd --query-port=111/tcp
端口打开之后,再次使用Windows的cmd窗口连接该端口,是可以成功的。
# 关闭111端口
firewall-cmd --permanent --remove-port=111/tcp
# 重新载入,使命令生效。
firewall-cmd --reload
# 查询端口状态,显示为 no
firewall-cmd --query-port=111/tcp
telnet 指令无法使用的解决方案:
如果在使用 telnet 指令的时候,出现以下错误,是因为Windows中的Telnet客户端服务没有打开。

使用以下方法打开即可:
1、打开 “应用和功能”
2、打开 ”程序和功能“。
在最下面。
3、启用或关闭Windows功能。
4、打开服务
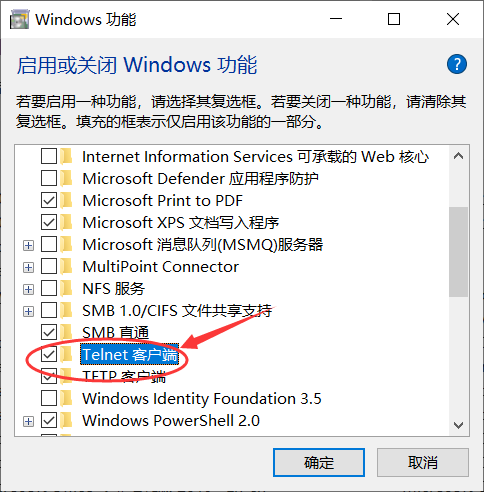
5、重启电脑,即可使用 telnet 指令。
4.7 动态监控进程
top 与 ps 命令很相似。它们都用来显示正在执行的进程。
Top 与 ps 指令又有不同之处,就是 top 指令在可以动态更新正在运行的的进程。
# 语法
top [选项]
| 选项 | 含义 |
|---|---|
| -d | 指定top指令的刷新间隔,默认是 3 秒 |
| -i | 不显示闲置或僵死进程 |
| -p | 通过指定监控进程id来仅监控某个进程的状态 |
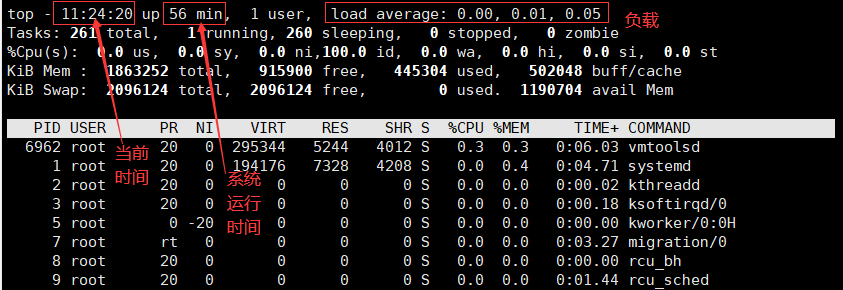
说明:
-
load average:负载值,三个值加起来除以3,如果大于0.7,则表示系统负载教大。
-
Tasks:任务数
- total:任务总数
- running:正在运行的任务。
- sleeping:正在休眠的任务。
- zombie:僵死进程,如果这个值很大,就要清除一下,因为它会占用内存。
-
%CPU:CPU的利用率。
- us:用户占用CPU的百分比。
- sy:系统占用CPU的百分比。
- id:可用CPU。
-
Men:物理内存
- total:总数。
- free:空闲内存大小。
- used:已用的内存大小。
- buff/cache:缓存占用的内存大小。
-
Swap:交换分区
- total:总数。
- free:空闲的交换分区大小。
- used:已用大小。
- avail Men:可获取的大小。
动态监控时的交互操作:
| 操作 | 功能 |
|---|---|
| P | 以CPU使用率排序,默认。降序 |
| M | 以内存使用率排序。降序 |
| N | 以PID排序。降序 |
| q | 退出程序。 |
# 不显示闲置进程或僵死进程
top -i
# 监控指定进程
top -p 进程的PID
# 监控指定用户
top u 用户名
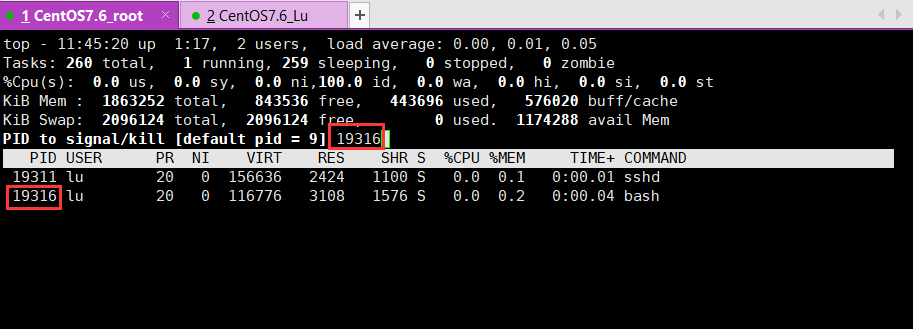
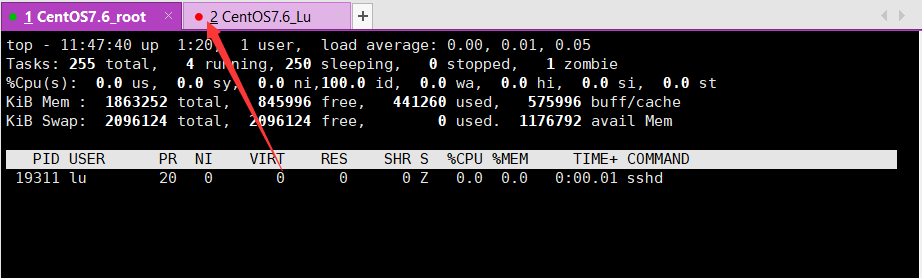
# 案例:监控 lu 用户,并踢他下线
top u lu

在此界面,按下 k。然后输入 lu 用户的 bash 的进程PID。
输入 9,强制杀死进程。
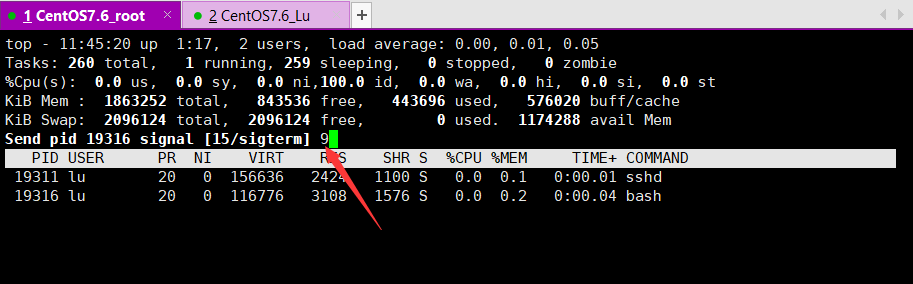
用户 lu 下线。
4.8 监控网络状态
服务连接的基本原理:
# 查看系统网络情况
netstat [选项]
| 选项 | 含义 |
|---|---|
| -an | 按一定顺序排序输出 |
| -p | 显示哪个进程在调用 |
显示信息如图:
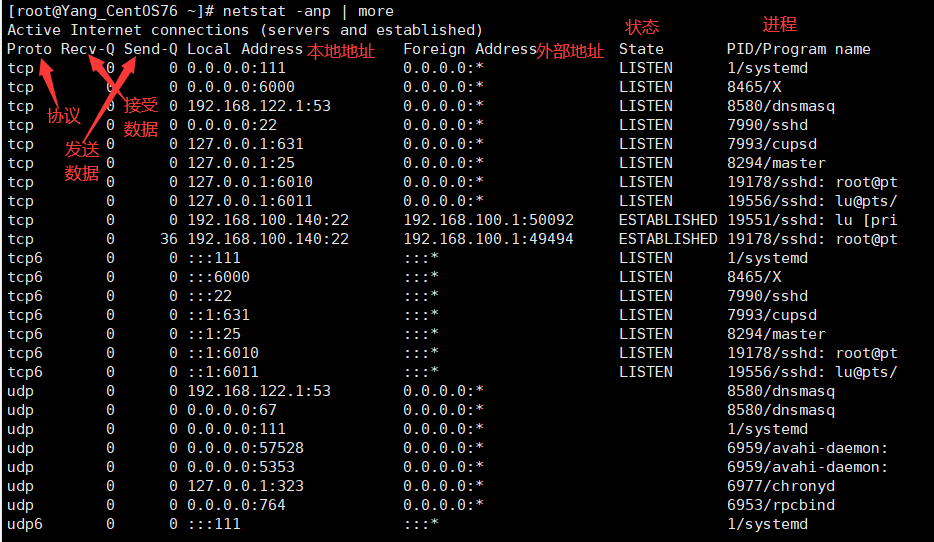
说明:
- Proto:连接使用的协议。
- Recv-Q:接收到的数据。
- Send-Q:发送的数据。
- Local Address:Linux虚拟机的本地地址。
- Foreign Address:相对Linux虚拟机的外部地址。
- State:连接状态
- Listen:监听状态,时刻准备连接。
- ESTABLISHED:连接成功。
- TIME WITE:超时等待。一个连接并不会立即断开,它会等待一段时间后再断开。
- PID:该连接发起的进程。
5. RPM 与 YUM
5.1 软件包管理概述
CentOS中主要有两种软件包管理方式,分别是YUM和RPM。
- YUM使用简单,但需要联网,YUM会去YUM包源获取需要的软件包。
- RPM不需要联网使用,但需要较高的操作水平和繁琐的依赖处理。
软件的安装和卸载应该是一件稀松平常的事,例如我们平常使用的Windows一样,想要安装一个软件,直接去官网下载安装包,然后双击开始安装即可,但是在Linux中,安装一个软件却不是这么简单。
因为Linux有一个理念就是一个程序只做好一件小事,一个大的程序就需要几个小的程序组合起来完成,这就导致了各个小的程序之间有复杂的依赖关系,比如:要完成某件任务,就需要安装程序A,而程序A的安装需要程序B的支持,程序B的安装又需要程序C的支持……,这便是依赖。
为了很好的组织管理这种复杂的依赖,就有了RPM软件包管理,Redhat Package Manager,类似windows 的 setup.exe,RPM是以一种数据库记录的方式来将需要的软件及其依赖关系安装到Linux主机的一套软件管理程序。也就是说,Linux中有一个关于RPM的数据库,它记录了安装软件的包与包之间的依赖关系。
RPM包时预先在Linux主机上编译并打包好的文件,安装起来非常便捷。
Linux中软件包的分类:
- 源码包:
- 脚本安装包:是基于源码包的再开发。Windows中是setup.exe,Linux中是install.sh。只需执行该程序即可通过点击下一步完成安装。
- 优点:
- 开源,可修改定制源代码。
- 自由,可以
- 源码包方式安装的软件要比RPM包安装的软件稳定高效。据统计,一般高5%。
- 卸载方便,可以直接删除对应的安装目录。
- 缺点:
- 安装步骤过多。
- 编译时间较长,比二进制安装时间长好多。
- 容易出错。
- 二进制包:如:RPM包
- 定义:RPM是经过编译之后的文件。例如:Windows中编译完之后是 .exe 可执行文件,Linux中编译完之后是 .rpm 文件。
- CentOS 中是RPM包。
- Ubuntu 中是DEB
- 优点:
- 包管理系统简单,只通过几个命令就可以实现包的安装,升级,查询和卸载。
- 安装速度比源码包安装快得多
- 缺点:
- 经过编译,源码不可见。
- 功能选择不如源码包灵活。
- 有依赖性:
- 依赖性是指是要想安装A包就得先安装B包,要想安装B包又得先安装C包,所以只能以CBA的顺序安装RPM包,删除的时候得按ABC顺序删除安装包,基本上所有的RPM包全有依赖性。
- 定义:RPM是经过编译之后的文件。例如:Windows中编译完之后是 .exe 可执行文件,Linux中编译完之后是 .rpm 文件。
5.2 RPM包管理–RPM命令
(1)RPM包命名规则
例:httpd-2.2.15.el6.centos.1.i686.rpm
说明:
- httpd 软件包包名
- 2.2.15 软件版本
- 15 软件发布的次数
- el6.centos 适合的Linux平台
- i686 适合的硬件平台
- noarch:表示任何硬件平台都可以安装。
- i686、i386:表示 32 位系统。
- x86_64:表示 64 为系统。
- .rpm:rpm包扩展名
注意:区分包名和包全名:
- 包名:类似上面的 httpd。如果操作的是已经安装的软件包时,使用包名即可,系统会去搜索 /var/lib/rpm/ 中的数据库。
- 包全名:包名+版本+发布次数+适用平台+扩展名。如果操作的是没有安装的软件包时,要使用包全名。而且要注意路径(所有的RPM包都在Linux的光盘文件的package目录下)。
/run/media/root/CentOS 7 x86_64/Packages在该目录下。
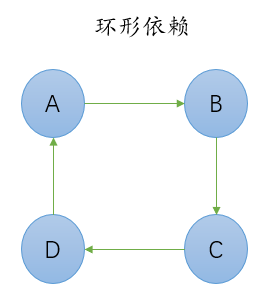
(2)RPM包依赖性
- 环形依赖:
- 树形依赖:
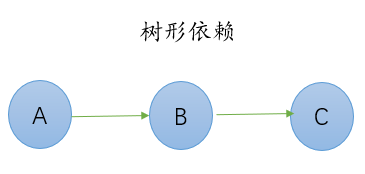
- 模块依赖
说明:
- 出现环形依赖时的解决方案,使用一条命令将a,b,c,d三个同时安装即可。
- 如果安装时遇到问题,出现依赖性错误,被依赖文件以.so.[数字] 结尾的为库依赖,需要直接安装这个软件,错误会自动解决。查询被依赖文件在哪个包中:在该网站查询网站 www.rpmfind.net.
yum主要就是为了解决RPM的依赖性。
(3)RPM包的安装、升级、卸载
1、安装
如果没有在RPM包所在目录,就需要使用绝对路径。
# RPM安装
rpm [选项] 包全名
# 一般组合使用
rpm -ivh 包全名
| 选项 | 含义 |
|---|---|
| -i | install,安装 |
| -v | verbose,显示详细信息。 |
| -h | hash,显示进度 |
| –nodeps | 不检测依赖性(不使用) |
2、升级
# RPM升级
rpm [选项] 包全名
# 一般组合使用
rpm -Uvh 包全名
| 选项 | 含义 |
|---|---|
| -U | update,升级更新 |
| -v | verbose,显示详细信息。 |
| -h | hash,显示进度 |
| –nodeps | 不检测依赖性(不使用) |
3、卸载
卸载不需要路径。
# rpm 卸载
rpm -e 包名
# 卸载firefox
rpm -e firefox
如果其它软件包依赖于您要卸载的软件包,卸载时则会产生错误信息。
removing these packages would break dependencies:foo is needed by bar-1.0-1
意思是说:要删除的 foo 会被 bar-1.0-1 使用到。
(4)RPM查询
#查询指定包是否安装
rpm -q 包名
# 查询所有已安装的包
rpm -qa
# 查询指定包的详细信息,i information。包信息是在组件这个包时就写好的。
rpm -qi 包名
# 查询未安装的软件包的信息。p package
rpm -qip 包全名
# 查询软件包中文件安装位置
rpm -ql 包名
# 查询系统文件属于哪个RPM包
rpm -qf 系统文件名
# 查询软件包的依赖性
rpm -qR 包名
# 查询是否安装firefox
rpm -q firefox
rpm -qa | grep firefox

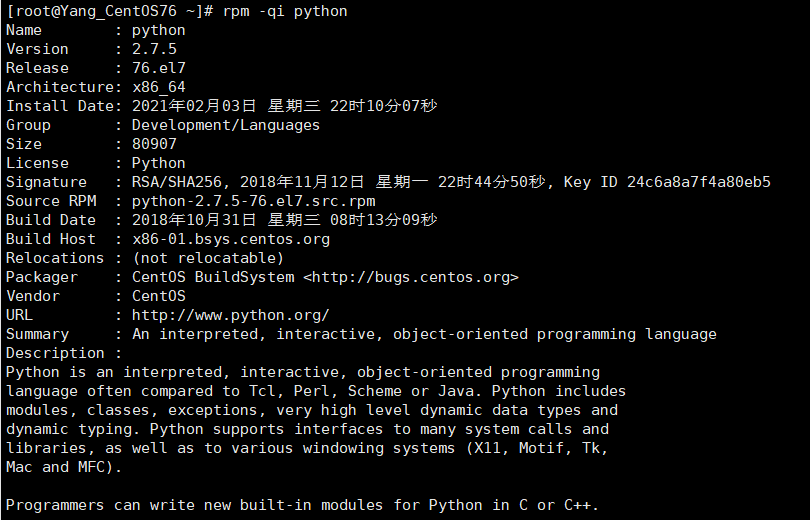
# 查询安装的 Python 的详细信息
rpm -qi python
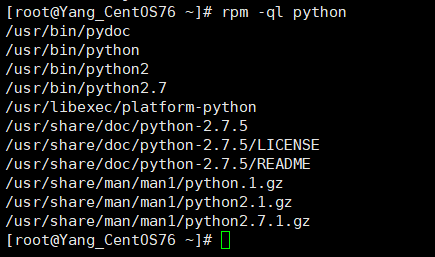
# 查询 Python 软件包的文件具体的安装路径
rpm -ql python
(5)校验
校验我们安装的软件有没有被修改过。
# RPM包校验
rpm -V 已安装的包名
如果没有任何修改,则不显示任何内容。
如果做了修改,则会显示如下内容:
S.5……T. c /etc/httpd/conf/httpd.conf
说明:
显示内容中的8个信息的具体内容: 如果某项没有变化,就用点表示。
- S:文件的大小是否改变。
- M:文件的类型或文件的权限(rwx)是否被改变
- 5:文件MD5校验和是否改变
- D:设备的中,从代码是否改变
- L:文件路径是否改变
- U:文件的属主(所有者)是否改变
- G:文件的属组是否改变
- T:文件的修改时间是否改变
文件类型:
- c:配置文件,config file
- d:普通文件,documentation
- g:“鬼”文件,ghost file,很少见,就是该文件不应该被这个RPM包包含。
- l:授权文件,license file
- r:描述文件,read me
(6)文件提取
当我们误删了某个系统文件或软件的配置文件时,就可以使用该指令,提取对应RPM软件包中的对应文件,而不需将整个系统或软件重装。
即:文件提取最大的作用就是修复。
# rpm2cpio 意思是将rpm格式文件转为cpio格式文件。
# 从cpio中提取指定的文件
rpm2cpio 包全名 | cpio -idv .文件绝对路径
-
rpm2cpio:将 rpm 包转换为 cpio 格式的命令。2 等于 to。
-
cpio:是一个标准工具,它用于创建软件档案文件和从档案文件中提取文件。
# < 输入重定向,从文件或指定设备中输入,而非标准输入
cpio [选项] < [文件|设备]
| 选项 | 含义 |
|---|---|
| -i | copy-in 模式,从文件中提取数据 |
| -d | 还原时自动新建目录 |
| -v | 显示还原过程 |
# 案例:我们误删除了 ls 指令
# 查询 ls 指令属于哪个软件包
rpm -qf /bin/ls
# 制造删除了 ls 指令的假象,这里只是将它移动到别的目录下。
mv /bin/ls /tmp/
# 提取 RPM 软件包中的ls命令到当前目录下,执行完指令后,当前目录下就会多一个 bin 目录,bin目录下有ls目录
rpm2cpio /run/media/root/CentOS\ 7\ x86_64/Packages/coreutils-8.22-23.el7.x86_64 | cpio -idv ./bin/ls
# 将 当前目录下的ls到根目录的 /bin/ls
cp /home/bin/ls /bin/
5.3 RPM包管理–YUM
(1)YUM概述
Yum 是一个 Shell 前端软件包管理器。基于RPM包管理,能够从指定的服务器自动 下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包。
RPM命令和YUM在线管理都是管理RPM包,区别在于RPM命令是手动安装,YUM是自动安装。
YUM并不是非得上网才能使用,可以配置本地光盘作为YUM的源
(2)网络yum源
YUM 源保存在 /etc/yum.repos.d/ 目录下。后缀为 .repo 的都是合法的YUM源。默认是 Base 这个源生效。CentOS-Media.repo 是本地光盘YUM源。
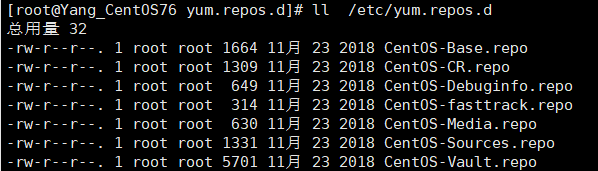
打开看一下配置好的yum源。
vim /etc/yum.repos.d/CentOS-Base.repo
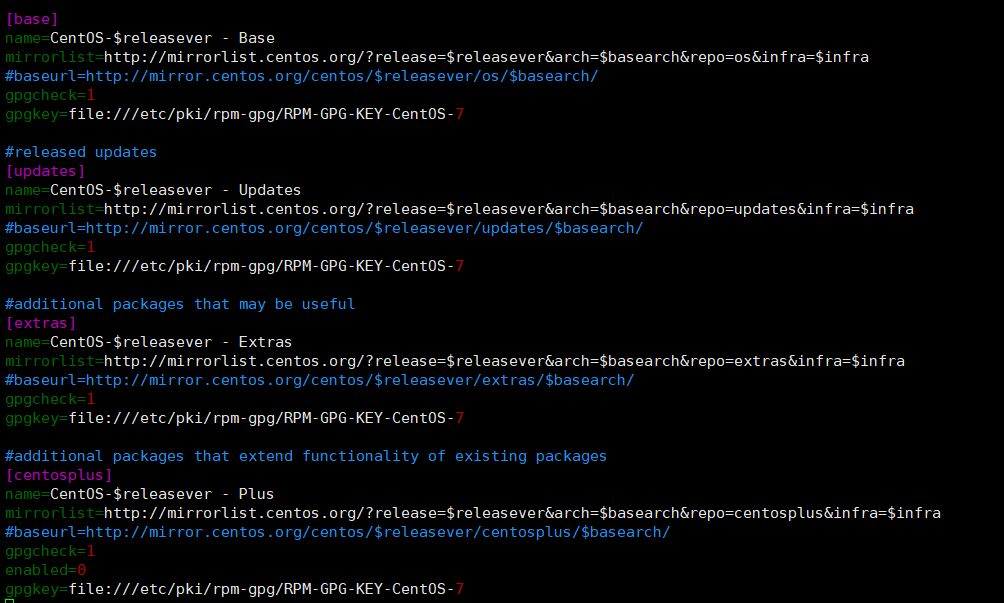
如上图,一共默认是由四个软件池,默认是第一个软件池生效。
说明:
- [base] 容器名称,一定要放在 [] 中 。
- name 容器说明,可以自己随便写 。
- mirrorlist:是地址镜像。
- baseurl:yum源服务器的地址。默认是CentOS官方的yum源服务器。
- enabled:值为1,表示容器生效。值为0,表示容器不生效。不写enabled也默认是1。
- gpgcheck:我们的RPM包是否进行数字证书验证。如果是1是指RPM的数字证书生效,如果是0则不生效。
- gpgkey:数字证书的公钥文件保存位置。不用修改
(3)YUM命令
# 查询服务器上所有的软件
yum list
# 查询是否有需要安装的软件
yum list | grep 软件
# 搜索服务器上所有和关键字相关的包
yum search 包名
# 安装软件
yum install 软件包
# -y 自动回答yes
yum -y install 软件包
# 升级软件包(注意:如果不加包名,则全部升级,包括Linux内核)
yum -y update 包名
# 卸载软件(如果不加包名,则全部卸载)
yum -y remove 包名
注意:一般不要轻易卸载软件,因为它会同时卸载该软件依赖的软件包,而这些软件包有可能被其他软件依赖,如果一旦卸载,会导致其他软件也不能使用。
(4)光盘YUM源搭建
当无法连接网络或网速较慢时,可以考虑搭建光盘YUM源来代替网络YUM源。缺点是软件不一定是最新的。
Linux一般是有两张光盘的,如果一个软件没有在当前光盘中,有较大可能是在另外一张光盘中。
搭建步骤:
- 第一步:挂载光盘。
- 第二步:修改YUM源配置文件。只让光盘源配置文件生效,这里有三种方法。
- 第一种:在其他源配置文件的每个软件池中加
enabled=0,使其失效。 - 第二种:删除或移动其他配置文件。
- 第三种:改后缀。将其他配置文件的后缀改掉,不是reop即可。
- 第一种:在其他源配置文件的每个软件池中加
- 第三步:编辑修改光盘源配置文件。
- 改光盘挂载点。
- enabled=1,使其生效。
# 挂载光盘
mount /dev/cdrom /mnt/cdrom
# 这里采用第三种方法
mv CentOS-Vault.repo CentOS-Vault.repo.A
mv CentOS-Base.repo CentOS-Base.repo.A
mv CentOS-Debuginfo.repo CentOS-Debuginfo.repo.A
# 修改光盘YUM源文件
vim /etc/yum.repos.d/CentOS-Media.repo

挂载光盘:
1、第一步:在 /mnt/ 目录下创建挂载点。
cd /mnt
mkdir cdrom
2、第二步:查看光盘完整路径名。
ls -l /dev | grep cdrom

3、第三步:挂载
# 将 /dev/cdrom 挂载到 /mnt/cdrom
mount /dev/cdrom /mnt/cdrom
4、查看光盘中的数据
cd /mnt/cdrom
ls -l

5、卸载光盘
不能在挂载点目录下解除挂载,必须先切换到其他目录。
# 卸载 /mnt/cdrom 挂载的目录
umount /mnt/cdrom
5.4 源码包管理
(1)源码包和RPM包的区别
上面我们已经了解了源码包和RPM包的区别,这里说的主要是它们安装位置的区别。
- RPM包是安装在默认位置中,不建议更改。如下:
| 路径 | 内容 |
|---|---|
| /etc/ | 配置文件安装目录 |
| /usr/bin/ | 可执行命令安装目录 |
| /usr/lib/ | 程序所使用的函数库保存位置 |
| /usr/share/doc/ | 基本的软件使用手册保存位置 |
| /usr/share/man/ | 帮助文件保存位置 |
| /var | 保存日志文件等可变文件 |
- 源码包安装位置:
- 安装在指定位置当中,一般是 /usr/local/软件名/
安装位置不同带来的影响
-
RPM包安装的服务可以使用系统服务管理命令(service、systemctl)来管理,network 的启动方法是:
- 完整路径加命令的格式:/etc/rc.d/init.d/network start
- 简化:service network start
-
源码包安装的服务则不能被服务管理命令管理,因为没有安装到默认路径中。所以只能用绝对路径进行服务的管理,如:
- /usr/local/apache/bin/apachectl start
(2)源码包安装过程
第一步:安装前的准备
- 安装C语言编译器,gcc
- 下载软件对应的源码包。 http://mirror.bit.edu.cn
第二步:安装注意事项
- 源代码,即源码包保存位置
/usr/local/src - 软件安装位置:
/usr/local/
第三步:源码包的具体安装过程
- 下载源码包。
- 将源码包上传到Linux中。
- 解压源码包。
tar -zxvf httpd-2.4.46.tar.gz - 进入解压之后的源码包目录,继续后续操作。
- INSTALL:该文件是安装说明。
- README:该文件是使用说明。
- 执行
./configure命令,软件配置与检查。- 定义需要的功能选项。例如:指定安装位置。
- 检测系统环境是否符合安装要求。
- 将定义好的功能选项和检测系统环境的信息都写入 MakeFile 文件。后续的安装都基于此文件。
- 执行命令,进行编译。
make- 如果这一步骤报错或上一步骤报错,可以使用指令
make clean进行清空。
- 如果这一步骤报错或上一步骤报错,可以使用指令
- 执行命令,进行安装。
make install
# 指定安装路径
./configure --prefix=/usr/local/软件名
注意:如果执行完上一条命令之后,报错如下:
configure: error: APR not found . Please read the documentation
- 这是因为缺少相关包。
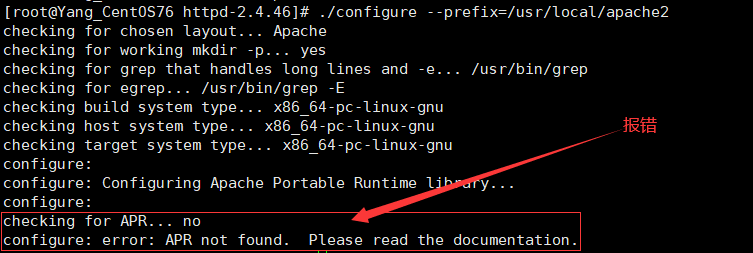
解决:
- 下载相关包(三个),下载链接如下:
http://archive.apache.org/dist/apr/apr-1.4.5.tar.gz
http://archive.apache.org/dist/apr/apr-util-1.3.12.tar.gz
http://jaist.dl.sourceforge.net/project/pcre/pcre/8.10/pcre-8.10.zip
- 下载完成之后,上传到Linux,进行安装
- 解决apr not found问题
# 解压
tar -zxf apr-1.4.5.tar.gz
# 进入目录
cd apr-1.4.5
# 软件配置与检查
./configure --prefix=/usr/local/apr
# 安装
make
make install
- 解决APR-util not found问题
tar -zxf apr-util-1.3.12.tar.gz
cd apr-util-1.3.12
./configure --prefix=/usr/local/apr-util -with-apr=/usr/local/apr/bin/apr-1-config
make
make install
- 解决pcre问题
unzip -o pcre-8.10.zip
cd pcre-8.10
./configure --prefix=/usr/local/pcre
make
make install
至此,Apache可以正常安装
./configure --prefix=/usr/local/apache2 --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util/ --with-pcre=/usr/local/pcre
make
make install
安装完之后,可以使用命令启动 Apache 服务,然后在浏览器访问虚拟机地址即可访问Apache。
如果访问不了,就请查看Linux防火墙状态。关闭防火墙或开放80端口之后,就可以访问。
# 使用绝对路径的方法启动 Apache
/usr/local/apache2/bin/apachectl start
访问成功之后显示:
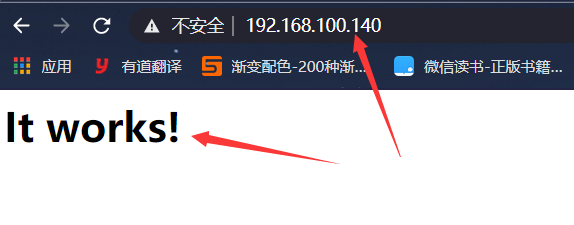
# 查看防火墙状态
systemctl status firewalld
# 查看80端口状态
firewall-cmd --query-port=80/tcp
# 开放80端口
firewall-cmd --permanent --add-port=80/tcp
# 重新载入防火墙
firewall-cmd --reload
(3)源码包的卸载
-
不需要卸载命令,直接删除安装目录即可。
-
不会遗留任何垃圾文件。
rm -rf /usr/local/apache2
【系列文章】
1. Git&GitHub(基础)
2. Git&GitHub(进阶)
3. 详解Linux(基础篇)
4. java多线程
5. JavaScript 总结
6. SpringMVC(一)
7. SpringMVC(二)
……
















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









