







Cache考点 计算机组织与结构
- cache行大小等于主存块的大小(指的是数据字大小),而实际上cache的每一行还包括了标记和控制位
- 局部性原理: 被访问的字附近的数据很可能会在不久的将来被访问到
映射机制
直接映射
cache行号= 主存块号 mod cache的行数
每一主存块对应唯一一行
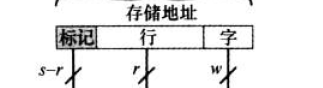
主存的地址可以看成由三个域组成:
- 最低的 w位表示块中的唯一字或字节
- 剩余的s位标识了主存2s个块中的一个
- cache会把这s位转换成两部分:
- 一个r位的行域,标识2r个cache行中的一个
- 一个s-r位的标记域 (最高位部分)映射到相同块号的两块不会有相同的标记域(从0000000······0向高地址遍历着想一想为什么)
综上
- cache会把这s位转换成两部分:
- 地址长度= s+w
- 可寻址的单元数=2(s+w)
- 块大小=行大小=2w
- 主存的块数=2s
- cache的行数=2r
- cache的容量=2r+w
- 标记长度=s-r
优点: 简单、花费少
缺点: 抖动现象 ,如果一个程序恰好需要重复访问两个映射到同一行而又来自不同的块的字呢? 这两个块将会不断地进出cache,被反复搬过来搬过去, cache命中率降低
全相联映射
要克服抖动现象这个缺点,全相联相联映射允许每一个主存块装入cache中的任意行
主存可看作由两部分组成:
- 标记域: 标识唯一一个主存块
- 字域
(地址中没有对应行号的字段,所以在全相联映射里,cache的行号不由地址格式决定)

那是怎么确定块 是否在cache中的呢?
答: 同时对每一行中的标记进行检查看是否匹配
综上:
- 地址长度=s+w
- 可寻址的单元数=2s+w
- 块大小=2w
- 主存的块数=2s
- cache的行数=unknown(因为不由主存地址决定,单从主存地址里面看不出来)
- 标记长度=s
优点:新的块进cache时,替换很灵活,使用它可以让cache命中率最大
缺点: 需要复杂的电路并行检查所有的cache行标记
组相联映射
融合了直接映射和全相联映射的优点,避开的两者的缺点
在组相联映射里面,cache分为v个组,每个组有k行
- cache的行数=组数*每一组的行数
- cache的组号=主存块号 mod cache组数
注意是用主存块号去取模而不是 原地址 去取模
(这样一来,映射到同一组的两个块(而不是地址),就不可能具有相同的标记数)
每一组里面有k行,就叫k路组相联映射
组相联映射里面:
在哪一组可以确定
但是在组里面的哪一行不能确定(随机)
主存地址可以看作三个字段:标记 , 组, 字
每个地址组字段长度为d,标识唯一一个组(*如果组号有13位,那么某一个地址对应的组号就是 该地址 mod 213, 因为总共就213个组)
字域w位
标记字段和组字段共长s位,用以标识主存中2s个块中的某一块
cache每一组有多少行和内存没有必然联系(每一组有多少行就是几路组相联映射
但是有多少组可以从主存地址里面的**”组“**部分看出来
综上:
- 地址长度=s+wh
- 可寻址单元数=2s+w
- 块大小=2w
- 主存的块数=2s
- cache中每组的行数=k
- 组数=v=2d
- cache中的行数=kv
- cache储存容量=k*2d
- 标记长度=s-d

替换算法
- 对于直接映射: 任意一个块都对应唯一一个行,没有选择的可能,不需要替换策略,直接换就可以了
- 对于全相联映射和组相联映射: 需要替换策略
LRU(最近最少使用)
- 替换掉那些在cache中最长时间没有被访问过的块
- 对于2路组相联映射最好实现
- 每一行用一个USE位,如果用这一行,这一行的USE位被设为1,组内另一行的USE位设置为0. 要替换时,替换掉USE位为0的那一行
- 对于全相联映射,用一个单独的索引表,当某一行被访问,把这一行移动到表头。 替换的时候替换掉表尾的那一行
- 对于2路组相联映射最好实现
- 会给出最佳命中率
FIFO(先进先出)
- 替换掉那些在cache中停留最长时间的块
- 采用时间片轮转法或环形缓冲技术
LFU(最近最少使用)
- 替换掉那些使用次数最少的块
- 用每一行相关的计数器来实现
任意选取
- 性能只是稍逊一点,但是容易实现
写策略
如果主存里面的内容被修改,那么对应cache中的内容就失效了
如果cache里面的内容被修改,那么主存里面的内容就要被更新
具体方式:
写直达
最简单的技术:
- 写操作同时对主存和cache执行
缺点: 产生大量的存储通信量
写回法
减少主存的写入:
- 当cache 被更新 时,设置cache的脏位使用位为1
- 当替换一个块时,如果发现这个块的脏位为1,要把这个块写回主存
缺点: 电路设计更复杂
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









