







文献阅读:Unified Contrastive Learning in Image-Text-Label Space
Abstract
视觉识别目前使用两种类型的方法:基于图像-标签的监督学习,基于图像-文本的对比学习。
由于数据源和学习目标不同,两种学习各有优势,图像-标签的预训练方式能生成更具有判别力的表征,图像-文本的方式具有零样本识别能力。但是,前者依赖人工标注数据,后者的判别能力相比于干净label训练的方法较弱。
在这项工作中,通过将两个数据源合并到一个共同的图像-文本-标签空间,提出了一种新的学习范式,称为统一对比学习(UniCL),它具有单一的学习目标,可以促使两种数据类型的协同作用。

Image-Label以离散label为目标,将相同概念的图像视为一组,完全忽视文本信息;
而Image-Text以图文对匹配为目标,每一对图文可以视作一个单独的label;
为此,提出了一个统一的对比学习方法,UniCL。它将图像和文本作为输入,用从标签中得到的软化目标计算损失。通过UniCL,将图像-标签和图像-文本数据结合在一起。
Method
定义一个数据格式S={(𝑥_𝑛,𝑡_𝑛,𝑦_𝑛 )}(𝑛=1)^𝑁,其中x∈X是图像,t∈T是其相应的语言描述,y∈Y是一个标签。
这个表示是广泛存在的图像数据的一般格式,包括常用的图像-文本和图像-标签数据。
一方面,对于图像-文本对{(𝑥_𝑛,𝑡_𝑛 )}(𝑛=1)^𝑁具有一对一的映射,每对都具有一个独一无二的标签,所以可以为图像-文本对找到一个𝑦_𝑛进而
S= {(𝑥_𝑛,𝑡_𝑛,𝑦_𝑛≡𝑛)}(𝑛=1)^𝑁;
另一方面,即使图片具有简单的分类标签,但这些标签也是由具体的任务中的概念得出。因此,S= {(𝑥_𝑛,𝑡_𝑛≡C[𝑦_𝑛],𝑦_𝑛 )}(𝑛=1)^𝑁,其中C为以𝑦_𝑛为索引的概念名称集合。

基于这个定义,可以将图像-标签对表示为有标签的图像-文本对,而将图像-文本对表示为有唯一标签的图像-文本。
对于图像-标签数据,为每个标签关联一个文本概念,图像和文本概念根据注释的标签(蓝色瓦片)进行匹配。
对于图像-文本数据,每一对都有唯一的标签索引,因此只在对角线条目(绿色瓷砖)上进行匹配。
在右边,简单地将它们合并为图像-文本-标签三联体,红色瓦片意味着正数对,而空白瓦片是负数对。
对于每个图像x,由θ参数化的图像编码器模型𝑓_𝜃首先将x表示为视觉特征向量:
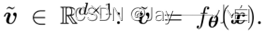
对于每个语言描述t∈ T,我们使用由φ参数化的文本编码器𝑓_𝜑 (𝑡)对其进行编码,以获得其特征向量:
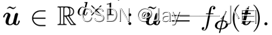
对于批次B中的第i个图像𝑥_i 和第j个语言描述𝑡_𝑗 ,将其特征向量归一化为hyper-sphere,通过:
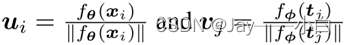
它们的相似性计算为:
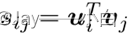
因此,图像和语言之间的双向学习目标:

图像与文本的对比损失,将一批匹配的图像与给定的文本对齐:

k表示当前batch内,和样本i的label相同的图像,j表示batch内所有其他样本。也就是说,对于每个文本,损失函数的分子是和该文本匹配的图像,分母是batch内所有图像。
文本与图像的对比性损失,使匹配的文本与给定的图像保持一致:

k表示当前batch内,和样本j的label相同的图像,i表示batch内所有其他样本。也就是说,对于每个图像,损失函数的分子是和该图像匹配的文本,分母是batch内所有文本。
Method——Connections to Cross-Entropy
当满足以下条件时,(3)中的文本-图像对比项作为一个特例恢复了交叉熵。
(i) 文本编码器𝑓_𝜑被表示为一个偏置为b的简单的线性嵌入层W
(ii)这个batchsize B足够大,所以当随机抽样用于训练时,所有的类嵌入向量都被用于对比学习。
(iii) τ = 1,并且排除L2规范化,因此,𝑢 ̃= 𝑢, 𝑣 ̃ = 𝑣。等式(3)变成:
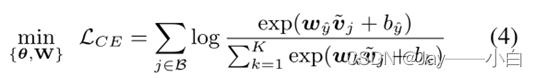
𝐿_(𝐵_𝑖 𝐶)相比交叉熵更具一般性, 𝐿_(𝐵_𝑖 𝐶)让具有相似文本描述的图像表示形成类簇,不具有相似文本描述的图像被拉远。
Method——Connections to SupCo
UniCL和SupCon的一个共同属性是,这两种方法都利用了标签引导的对比学习。这两种方法都利用具有相同标签的样本作为正数贡献给分母。
SupCon是在图像-标签环境下提出的,其中每个图像都有两个不同的视图。UniCL和SupCon在两个方面有所不同:
在SupCon中,对比学习中的一对都来自同一模态:图像和图像对;在UniCL中,一对是不同的模态:图像和文本对。
在SupCon中,只有一个共享的图像编码。在UniCL中,两个不同的编码器用于不同的模态,如下面图所示。
Method——Connections to CLIP
对于图像-文本对,在一个批次中,图像和其配对的文本之间只有一对一的映射。换句话说,对于公式(2)和公式(3)来说,P(i)={i}和P(j)={j}。那么, 𝐿_(𝐵_𝑖 𝐶)就变成了:

和CLIP的主要差别在于,利用label信息将一部分非对角线上的元素视为正样本。这意味着,当只采用图像-文本数据时, 𝐿_(𝐵_𝑖 𝐶)降低到CLIP训练目标。
Method——Discussions & Properties

Method——Model Training and Adaptation

所有图像-文本对都有一个初始标签索引y = 0,而所有图像-标签对都有一个初始标签索引y∈ [1, …, K]。
TargetM函数确保批次中的每个唯一语言描述都具有唯一的标签索引。
在训练中,τ是一个初始化为1的可训练变量。训练后,学习的视觉编码器和文本编码器{𝑓_𝜃 , 𝑓_𝜑 (𝑡)}可以联合用于开放词汇图像识别,即识别训练中看到的类别或注释类别以外的新类别。
Experiments
对UniCL进行研究,以回答两个研究问题。
Q1 学习目标–与CE和SupCon相比,UniCL在图像分类上的表现如何?
Q2 预训练数据–在图像-文本-标签联合数据上应用UniCL的独特优势是什么?

前4行是图像分类数据,文本描述来源于标签。
后3行是图像-文本数据集,使用Spacy抽取名词短语,统计出现次数大于5次的名词实体。
评估:标准图像分类、零样本图像分类、线性分类、目标检测

相比使用交叉熵损失和有监督对比学习,文中提出的UniCL在多个模型和数据集上取得较好的效果。尤其是在小数据集上训练时,UniCL比交叉熵训练效果提升更明显

文中也对比了文本Encoder是否引入的效果,如果将Transformer替换成线性层,效果有所下降,表明文本Encoder的引入能够有助于提升图像分类效果。同时,如果去掉𝐿_i2t 的loss只保留𝐿_t2i的loss,会导致效果大幅下降。

UniCL对批次大小的变化具有鲁棒性

对于上面3行和下面3行,下面3行引入额外Image-Text数据的图像分类效果要显著优于只使用图像分类数据的效果。

引入Image-Label对Image-Text效果有一定提升作用。

在ImageNet-1K上训练的模型很难从其它21K概念中概括出概念。相比之下,添加GCC-15M图像文本对可以显著提高其理解能力

合并了一半的ImageNet-21K和YFCC-14M数据集,以便训练实例总数保持不变,并训练一个UniCL模型,这种数据统一提高了几乎所有指标的性能

使用CLIP(左)和UniCL(右)两种方法训练的图像embedding的t-sne图。可以看到,使用CLIP训练的模型,不同类别的图像表示混在一起;而使用UniCL训练的模型,不同类别的图像表示能够比较好的得到区分。















 3899
3899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









