







文章目录
Proximal Policy Optimization
Proximal Policy Optimization,简称PPO,即近端策略优化,是对Policy Graident,即策略梯度的一种改进算法。PPO的核心精神在于,通过一种被称之为Importance Sampling的方法,将Policy Gradient中On-policy的训练过程转化为Off-policy,即从在线学习转化为离线学习,某种意义上与基于值迭代算法中的Experience Replay有异曲同工之处。通过这个改进,训练速度与效果在实验上相较于Policy Gradient具有明显提升。
On-policy v.s. Off-policy

on policy:和环境交互的agent和要学习的agent是一个agent。举个例子:阿光自己下棋,并且学习如何下棋。自己在探索,自己在学习。
off policy:和环境交互的agent和要学习的agent不是一个agent。举个例子:阿光看佐为下棋,阿光在学习。就是说agent用别人的数据在进行学习。就像皇帝仅仅是在朝听政,各个大臣来向皇帝汇报情况。

平时我们自己使用的policy gradient都是on policy。就是使用一个 θ \theta θ 来求得一大堆的数据,之后更新这个 θ \theta θ为 θ 1 \theta^1 θ1 ,但是得到 θ 1 \theta^1 θ1 之后之前的 θ \theta θ 就是错的,所以要用 θ 1 \theta^1 θ1 来重新获得一大堆数据,所以整个过程就是比较墨迹的。所以我们思考如何能不需要一直用 θ \theta θ 来获取数据,于是就有了off policy的情况!
我们的目标是使用固定的 θ ′ \theta' θ′来获取数据,之后一直使用这些数据来更新 θ \theta θ 。无论以后 θ \theta θ 如何改变,一直都使用这些数据。
Importance Sampling
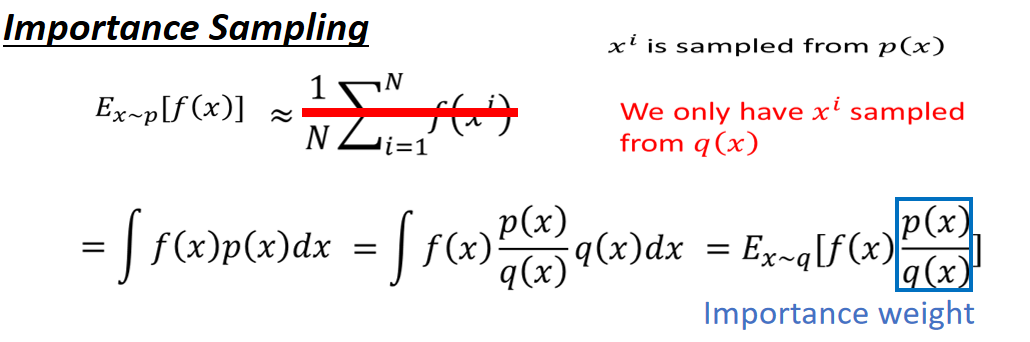
在前面提到,PPO的一个核心改进是将Policy Gradient中On-policy的训练过程转化为Off-policy,即从在线学习转化为离线学习,这个转化过程被称之为Importance Sampling,是一种数学手段。
x服从p分布,我们计算
f
(
x
)
f(x)
f(x) 的期望:
E
x
∼
p
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
E_{x\sim p}[f(x)] = \int f(x)p(x)dx
Ex∼p[f(x)]=∫f(x)p(x)dx
但是p分布是很难计算(采样)的。于是我们引入一个比较容易计算(采样)的q分布,于是在分子分母同时乘以
q
(
x
)
q(x)
q(x),于是就变成了服从q分布的x来求期望:
E
x
∼
p
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
=
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
=
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
E_{x\sim p}[f(x)] = \int f(x)p(x)dx = \int f(x)\frac{p(x)}{q(x)}q(x)dx = E_{x\sim q}[f(x)\frac{p(x)}{q(x)}]
Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]

我们研究了使用重要性采样实现on policy 到off policy的转换,我们知道期望值几乎是差不多的,但是我们不知道使用off policy以后方差的变化会是怎样。
于是就计算了方差的公式
由方差公式:
V
a
r
[
X
]
=
E
[
X
2
]
−
(
E
[
X
]
)
2
Var[X] = E[X^2]-(E[X])^2
Var[X]=E[X2]−(E[X])2
可以得到:
V
a
r
x
∼
p
[
f
(
x
)
]
=
E
x
∼
p
[
f
(
x
)
2
]
−
(
E
x
∼
p
[
f
(
x
)
]
)
2
Var_{x\sim p}[f(x)] = E_{x\sim p}[f(x)^2]-(E_{x\sim p}[f(x)])^2
Varx∼p[f(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2
V
a
r
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
=
E
x
∼
q
[
(
f
(
x
)
p
(
x
)
q
(
x
)
)
2
]
−
(
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
)
2
\begin{aligned} Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}] & = E_{x\sim q}\left[\left(f(x)\frac{p(x)}{q(x)}\right)^2 \right] -\left(E_{x\sim q}\left[f(x)\frac{p(x)}{q(x)}\right]\right)^2 \\ \end{aligned}
Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2
由下面两个式子:
E
x
∼
q
[
(
f
(
x
)
p
(
x
)
q
(
x
)
)
2
]
=
E
x
∼
q
[
f
(
x
)
2
p
(
x
)
2
q
(
x
)
2
]
=
∑
q
f
(
x
)
2
p
(
x
)
q
(
x
)
p
(
x
)
=
E
x
∼
p
f
(
x
)
2
p
(
x
)
q
(
x
)
E_{x\sim q}\left[\left(f(x)\frac{p(x)}{q(x)}\right)^2 \right] = E_{x\sim q}\left[f(x)^2\frac{p(x)^2}{q(x)^2} \right] = \sum_q f(x)^2\frac{p(x)}{q(x)}p(x) =E_{x\sim p}f(x)^2\frac{p(x)}{q(x)}
Ex∼q[(f(x)q(x)p(x))2]=Ex∼q[f(x)2q(x)2p(x)2]=q∑f(x)2q(x)p(x)p(x)=Ex∼pf(x)2q(x)p(x)
E x ∼ p [ f ( x ) ] = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] E_{x\sim p}[f(x)] = E_{x\sim q}\left[f(x)\frac{p(x)}{q(x)}\right]\ Ex∼p[f(x)]=Ex∼q[f(x)q(x)p(x)]
又可以将
V
a
r
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]
Varx∼q[f(x)q(x)p(x)]进一步化简:
V
a
r
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
=
E
x
∼
q
[
(
f
(
x
)
p
(
x
)
q
(
x
)
)
2
]
−
(
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
)
2
=
E
x
∼
p
[
f
(
x
)
2
p
(
x
)
q
(
x
)
]
−
(
E
x
∼
p
[
f
(
x
)
]
)
2
\begin{aligned} Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}] & = E_{x\sim q}\left[\left(f(x)\frac{p(x)}{q(x)}\right)^2 \right] -\left(E_{x\sim q}\left[f(x)\frac{p(x)}{q(x)}\right]\right)^2 \\ & = E_{x\sim p}\left[f(x)^2\frac{p(x)}{q(x)}\right]- (E_{x\sim p}[f(x)])^2 \end{aligned}
Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2
对比两个方差,最后发现第二项对于方差的影响是很小的,但是第一项对于方差的影响还是有的。
于是我们晓得,当使用重要性采样的时候,要保证只有 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x) 的区别不大,才会使得方差的区别很小。(如果从分布p到分布q的话,就要乘以 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x))
因此,我们要做的就是保证 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x) 的区别不大,并且尽量sample完全!如果这两点没有保证,会发生什么情况呢?我们看下面这个例子:
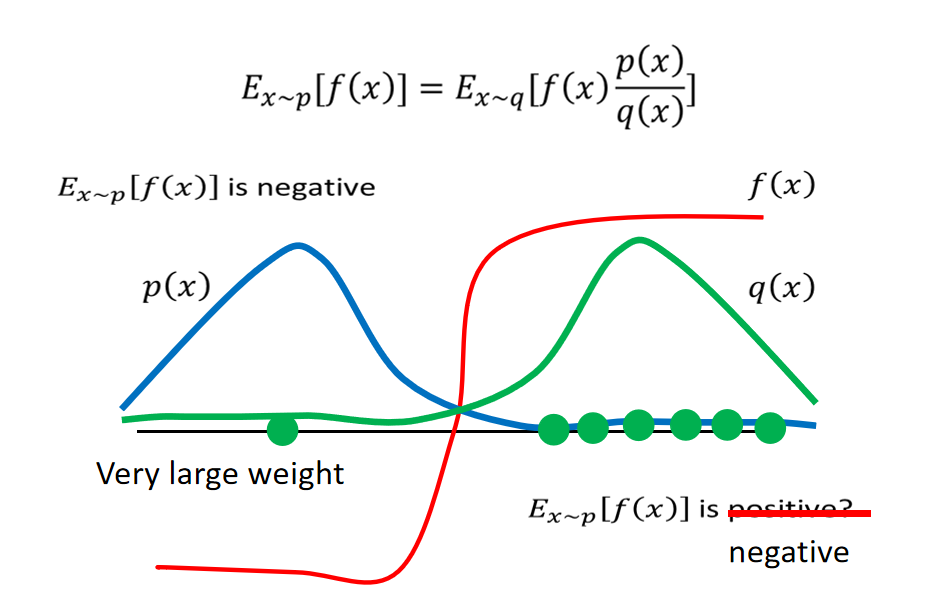
我们使用一个直观一点的方式去理解这个问题,我们之前计算p分布下的期望,之后我们计算q分布下的期望。假设sample不是很完全的情况下,计算p的时候大部分都是在y轴左侧,f(x)一般都是负数。但是计算q的时候,大部分都是在y轴的右侧,f(x)一般都是正值,而且 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)都是正数,所以如果sample不完全的时候,很可能计算的结果都是相反的。因此我们要尽可能的sample多的数据,如果我们此时sample到的一个点在左边,那么通过 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)就可以得到一个较大的权重,乘以此时的f(x)可能就可以中和多数sample在右边的正数,最终的结果可能就是负数。
其实这也是p(x)和q(x)不一致所导致的问题,所以我们要尽量p(x)需要和q(x)保持一致。
On-policy -> Off-policy

我们之前使用on policy的时候是使用 θ \theta θ来产生数据,之后计算梯度,更新 θ \theta θ,之后使用更新后的 θ \theta θ再产生数据,更新梯度……
但是off policy的方法,我们使用一个固定的 θ ′ \theta' θ′来产生数据,并用这些数据来更新 θ \theta θ,并且之后一直使用这些数据来更新 θ \theta θ 。因此我们只需要使用一次 θ ′ \theta' θ′来产生数据即可,无论以后 θ \theta θ 如何改变,一直都使用这些数据而无需继续sample。
从On-policy->Off-policy,我们的梯度公式发生了改变,也就是说我们要Maximize的对象也发生了改变:

这个便是我们计算梯度的过程,第一个等式是我们计算on policy的:
=
E
(
s
t
,
a
t
)
∼
π
θ
[
A
θ
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
= E_{(s_t,a_t)\sim \pi_\theta}[A^{\theta}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)]
=E(st,at)∼πθ[Aθ(st,at)▽logpθ(atn∣stn)]
我们通过重要性采样来变成off policy:
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
P
θ
(
s
t
,
a
t
)
P
θ
′
(
s
t
,
a
t
)
A
θ
′
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
= E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{P_{\theta}(s_t,a_t)}{P_{\theta'}(s_t,a_t)}A^{\theta'}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)]
=E(st,at)∼πθ′[Pθ′(st,at)Pθ(st,at)Aθ′(st,at)▽logpθ(atn∣stn)]
注意此处
A
θ
A^{\theta}
Aθ 变成
A
θ
′
A^{\theta'}
Aθ′,因为这一项表示的意思是在某一个state采取某一个action会得到reward减去一个baseline。之前我们是通过
θ
\theta
θ与环境做互动得到reward,而现在是通过
θ
′
\theta'
θ′与环境做互动得到reward。
之后我们把条件概率的值展开:
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
p
θ
′
(
s
t
)
p
θ
′
(
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
= E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}\frac{p_{\theta'}(s_t)}{p_{\theta'}(s_t)}A^{\theta'}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)]
=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ′(st)Aθ′(st,at)▽logpθ(atn∣stn)]
但是条件概率的第二项我们不知道该怎么计算,同时我们也是无法计算的,因为出现游戏中出现哪个s的概率我们是不晓得的,因此我们就假设它不存在好了:
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
= E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)]
=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)▽logpθ(atn∣stn)]
接下来我们来看一下我们原始式子,也就是我们要Maximize的原始对象是什么!
在看这个之前,我们先来看一下我们之前用原始式子:
R
θ
‾
=
∑
τ
R
(
τ
)
P
(
τ
∣
θ
)
\overline{R_{\theta}} =\sum_{\tau}R(\tau)P(\tau|\theta)
Rθ=τ∑R(τ)P(τ∣θ)
的推倒梯度的过程(更加详细的请看上一篇文章):
根据公式:
▽
l
o
g
f
(
x
)
=
d
l
o
g
(
f
(
x
)
)
d
x
=
1
f
(
x
)
d
f
(
x
)
d
x
=
▽
f
(
x
)
f
(
x
)
▽logf(x) = \frac{dlog(f(x))}{dx} = \frac{1}{f(x)} \frac{df(x)}{dx} = \frac{▽f(x)}{f(x)}
▽logf(x)=dxdlog(f(x))=f(x)1dxdf(x)=f(x)▽f(x)
可以推到得到:
▽
R
θ
‾
=
∑
t
R
(
τ
)
▽
P
(
τ
∣
θ
)
=
∑
τ
R
(
τ
)
P
(
τ
∣
θ
)
▽
P
(
τ
∣
θ
)
P
(
τ
∣
θ
)
=
∑
τ
R
(
τ
)
P
(
τ
∣
θ
)
▽
l
o
g
P
(
τ
∣
θ
)
\begin{aligned} \bigtriangledown\overline{R_{\theta}} = & \sum_tR(\tau)\bigtriangledown P(\tau|\theta) \\ =& \sum_{\tau}R(\tau)P(\tau|\theta)\frac{\bigtriangledown P(\tau|\theta)}{P(\tau|\theta)}\\ = & \sum_{\tau}R(\tau)P(\tau|\theta)\bigtriangledown logP(\tau|\theta) \end{aligned}
▽Rθ===t∑R(τ)▽P(τ∣θ)τ∑R(τ)P(τ∣θ)P(τ∣θ)▽P(τ∣θ)τ∑R(τ)P(τ∣θ)▽logP(τ∣θ)
因此根据式子:
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
= E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)]
=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)▽logpθ(atn∣stn)]
可以很简单的就知道了我们要Maximize的原始目标就是前面两项:
J
θ
′
(
θ
)
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
J^{\theta'}(\theta) = E_{(s_t,a_t)\sim \pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\right]
Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
我们也可以进行逆推得到的哦~:
G
r
i
d
e
n
t
f
o
r
u
p
d
a
t
e
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
p
θ
(
a
t
n
∣
s
t
n
)
p
θ
(
a
t
n
∣
s
t
n
)
]
=
∑
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
p
θ
(
a
t
n
∣
s
t
n
)
p
θ
(
a
t
n
∣
s
t
n
)
p
θ
(
a
t
n
∣
s
t
n
)
]
=
∑
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
▽
p
θ
(
a
t
n
∣
s
t
n
)
]
=
▽
∑
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
p
θ
(
a
t
n
∣
s
t
n
)
]
=
▽
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
\begin{aligned} Grident \ for \ update &= E_{(s_t,a_t)\sim \pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\bigtriangledown log p_{\theta}(a_t^n|s_t^n)\right] \\ &= E_{(s_t,a_t)\sim \pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\frac{\bigtriangledown p_{\theta}(a_t^n|s_t^n)}{p_{\theta}(a_t^n|s_t^n)}\right] \\ &= \sum_{\pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\frac{\bigtriangledown p_{\theta}(a_t^n|s_t^n)}{p_{\theta}(a_t^n|s_t^n)}p_{\theta}(a_t^n|s_t^n)\right] \\ &= \sum_{\pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\bigtriangledown p_{\theta}(a_t^n|s_t^n)\right]\\ &= \bigtriangledown\sum_{\pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t) p_{\theta}(a_t^n|s_t^n)\right]\\ &= \bigtriangledown E_{(s_t,a_t)\sim \pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\right]\\ \end{aligned}
Grident for update=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)▽logpθ(atn∣stn)]=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)pθ(atn∣stn)▽pθ(atn∣stn)]=πθ′∑[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)pθ(atn∣stn)▽pθ(atn∣stn)pθ(atn∣stn)]=πθ′∑[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)▽pθ(atn∣stn)]=▽πθ′∑[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)pθ(atn∣stn)]=▽E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
因此去掉梯度后,我们的原始式子就是:
J
θ
′
(
θ
)
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
J^{\theta'}(\theta) = E_{(s_t,a_t)\sim \pi_{\theta'}}\left[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)\right]
Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
Add Constraint
PPO/TRPO

我们为了使 θ \theta θ和 θ ′ \theta' θ′不要相隔太远的话,我们引入了两个新的方法,一种是PPO / TRPO,PPO是TRPO的改进版,在编程方面,前者是更加轻松的。
PPO是引入一个 K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′):
- 如果 θ , θ ′ \theta,\theta' θ,θ′ 相差太大, K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′)的值就非常大,我们增加这一部分惩罚;
- 如果 θ , θ ′ \theta,\theta' θ,θ′相差小, K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′)的值就非常小,我们就减小这一部分的惩罚
我们最终要Maximize J P P O θ ′ J^{\theta'}_{PPO} JPPOθ′,就尽可能的使 K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′)小!这里的 β \beta β是一个自定义的值,我们可以根据 K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′)的大小进行调整,下面的算法处会介绍!
这里要注意的是我们的Constraint K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′) 并不是针对参数 θ \theta θ和 θ ′ \theta' θ′ 的而是针对这两个参数下行为的!也就是说我们的目的并不是使这两个参数不要相差太多,而是说,输入同样的state,输出的action的概率分布不能差太远。得到action的概率分布的相似程度,我们可以用KL散度来计算。
从TRPO的式子我们也可以看出来,它其实也使用KL散度: K L ( θ , θ ′ ) KL(\theta,\theta') KL(θ,θ′)。但它的不同之处在于并不是将它加入到我们要Maximize的目标中,而是额外增加了一个限制: K L ( θ , θ ′ ) < β KL(\theta,\theta')<\beta KL(θ,θ′)<β。这样会使得计算更加麻烦!
PPO algorithm

ppo的主要流程:
-
先找一个 θ 0 \theta^0 θ0 去初试化 θ \theta θ
-
在每一个迭代中:
-
找到一个 θ k \theta^k θk 用来收集数据,数据是一堆 ( s t , a t ) (s_t,a_t) (st,at)的pair,并且计算每个pair的advantage A θ k ( s t , a t ) A^{\theta^k}(s_t,a_t) Aθk(st,at)
-
找到 θ \theta θ 来 optimizing J p p o ( θ ) J_{ppo}(\theta) Jppo(θ)。
-
在使用的过程中,可以动态的更新β:
- 当 K L KL KL的值过大的时候,意味着 θ , θ k \theta,\theta^k θ,θk之间差别很大,这时候意味着第二项的权重太小,不足以限制,于是就加大了β;
- 反之,如果 K L KL KL的值过小,就意味着 θ , θ k \theta,\theta^k θ,θk之间差别很小,意味着第二项已经起到了作用,所以就减小β
PPO2
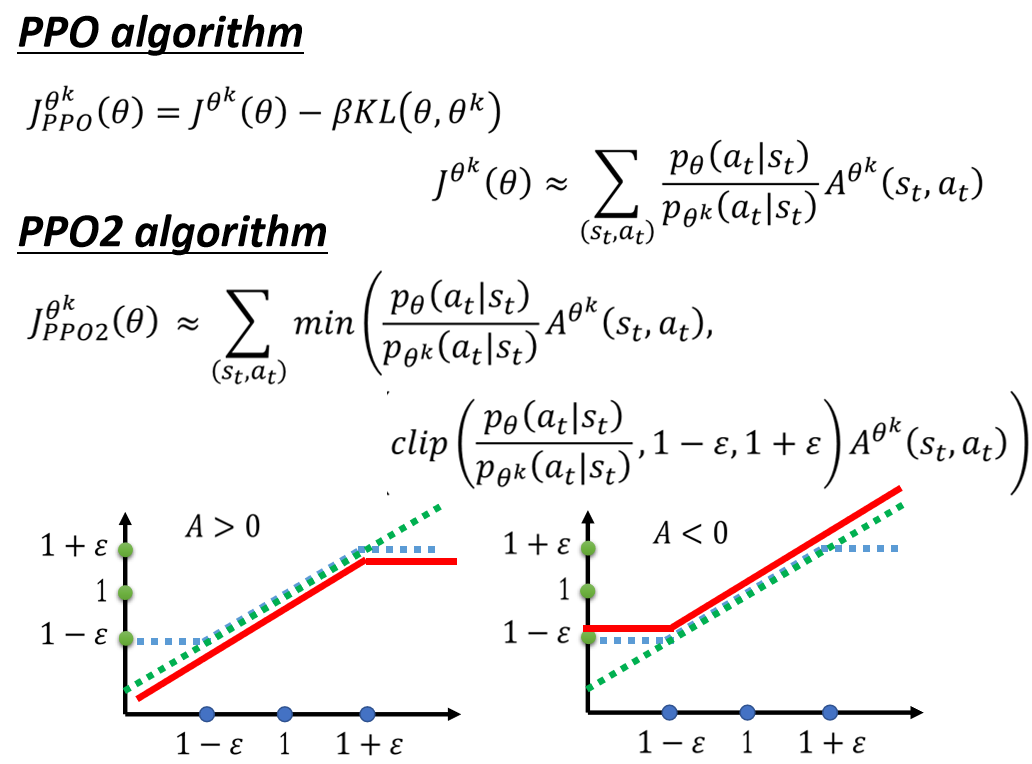
还有一种PPO2算法,其作用也是为了减少 θ , θ k \theta,\theta^k θ,θk 之间差别。
看起来很复杂,我们可以直接看下面的两幅图中,横坐标都是 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}(a_t|s_t)}{p_{\theta^k(a_t|s_t)}} pθk(at∣st)pθ(at∣st):
-
当A>0时候,奖励是正的,更新的幅度越大越好,但是因为加入惩罚,所以更新的幅度在横坐标大于 1 + ϵ 1+\epsilon 1+ϵ时候,就会乘以同一个幅度 1 + ϵ 1+\epsilon 1+ϵ,所以是一条横线。这样就使得不会无限制增大而导致 θ , θ k \theta,\theta^k θ,θk的差别越来越大。我们允许 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}(a_t|s_t)}{p_{\theta^k(a_t|s_t)}} pθk(at∣st)pθ(at∣st)最大就是 1 + ϵ 1+\epsilon 1+ϵ 时,因此达到这个值是我们就会停止!
假设我们允许无限增大,就会导致当前state采取的action的概率 p θ ( a t ∣ s t ) p_{\theta}(a_t|s_t) pθ(at∣st)越来越大,本来我们的 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}(a_t|s_t)}{p_{\theta^k(a_t|s_t)}} pθk(at∣st)pθ(at∣st)就已经大于 1 + ϵ 1+\epsilon 1+ϵ了,再增加 p θ ( a t ∣ s t ) p_{\theta}(a_t|s_t) pθ(at∣st)的概率,就会导致 θ , θ k \theta,\theta^k θ,θk的差别越来越大!
-
同理,当A<0时候,奖励是负数,更新的幅度是越小越好,但是因为加入了惩罚,所以更新的幅度小于 1 − ϵ 1-\epsilon 1−ϵ时,就会乘以同一个幅度 1 − ϵ 1-\epsilon 1−ϵ,所以是一条横线。这样就使得不会无限制减小而导致 θ , θ k \theta,\theta^k θ,θk的差别越来越大。我们允许 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}(a_t|s_t)}{p_{\theta^k(a_t|s_t)}} pθk(at∣st)pθ(at∣st)最小就是 1 − ϵ 1-\epsilon 1−ϵ 时,因此达到这个值是我们就会停止!
假设我们允许无限减小,就会导致当前state采取的action的概率 p θ ( a t ∣ s t ) p_{\theta}(a_t|s_t) pθ(at∣st)越来越小,本来我们的 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_{\theta}(a_t|s_t)}{p_{\theta^k(a_t|s_t)}} pθk(at∣st)pθ(at∣st)就已经小 1 − ϵ 1-\epsilon 1−ϵ了,再减小 p θ ( a t ∣ s t ) p_{\theta}(a_t|s_t) pθ(at∣st)的概率,就会导致 θ , θ k \theta,\theta^k θ,θk的差别越来越大!
其中clip的式子就是图中蓝色的线,一直是取蓝色和绿色线的最小值。使得无论是A是偏大还是偏小,都不要使得θ,θk之间差别过大
Experimental Results(实验结果)
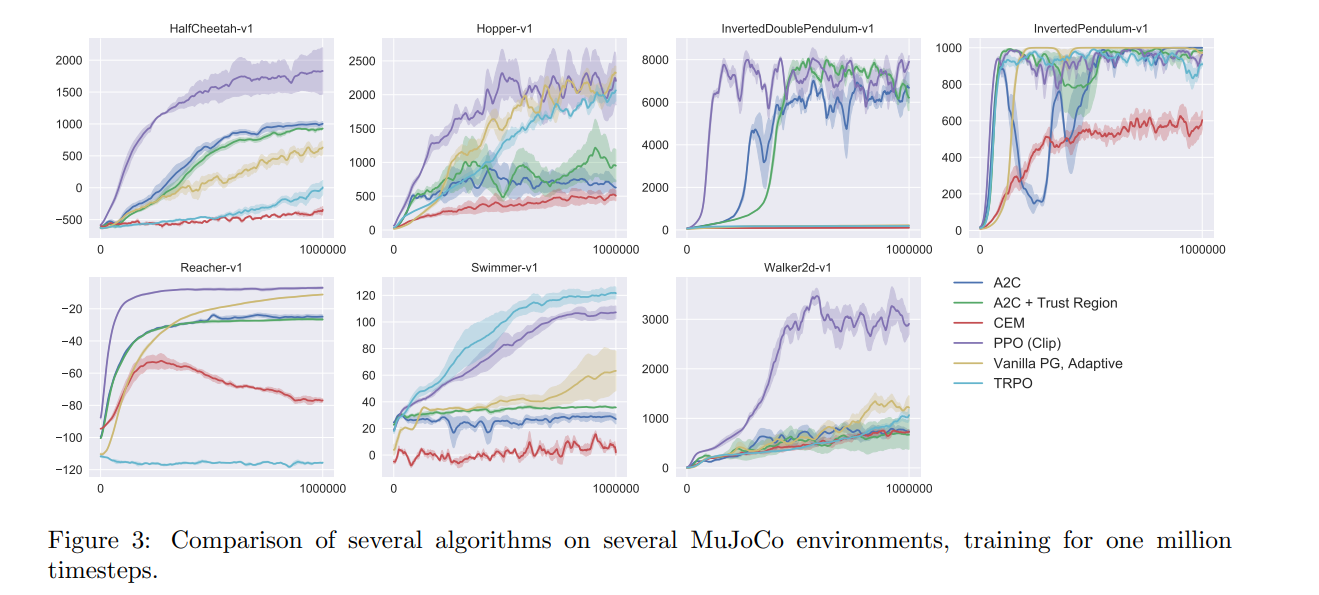
紫色的线代表的是PPO2方法,也就是PPO(Clip)。发现在这几个task中,PPO2方法不是最好的就是第二好的!效果还是很不错的!















 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









