







执行流程分析
基本流程
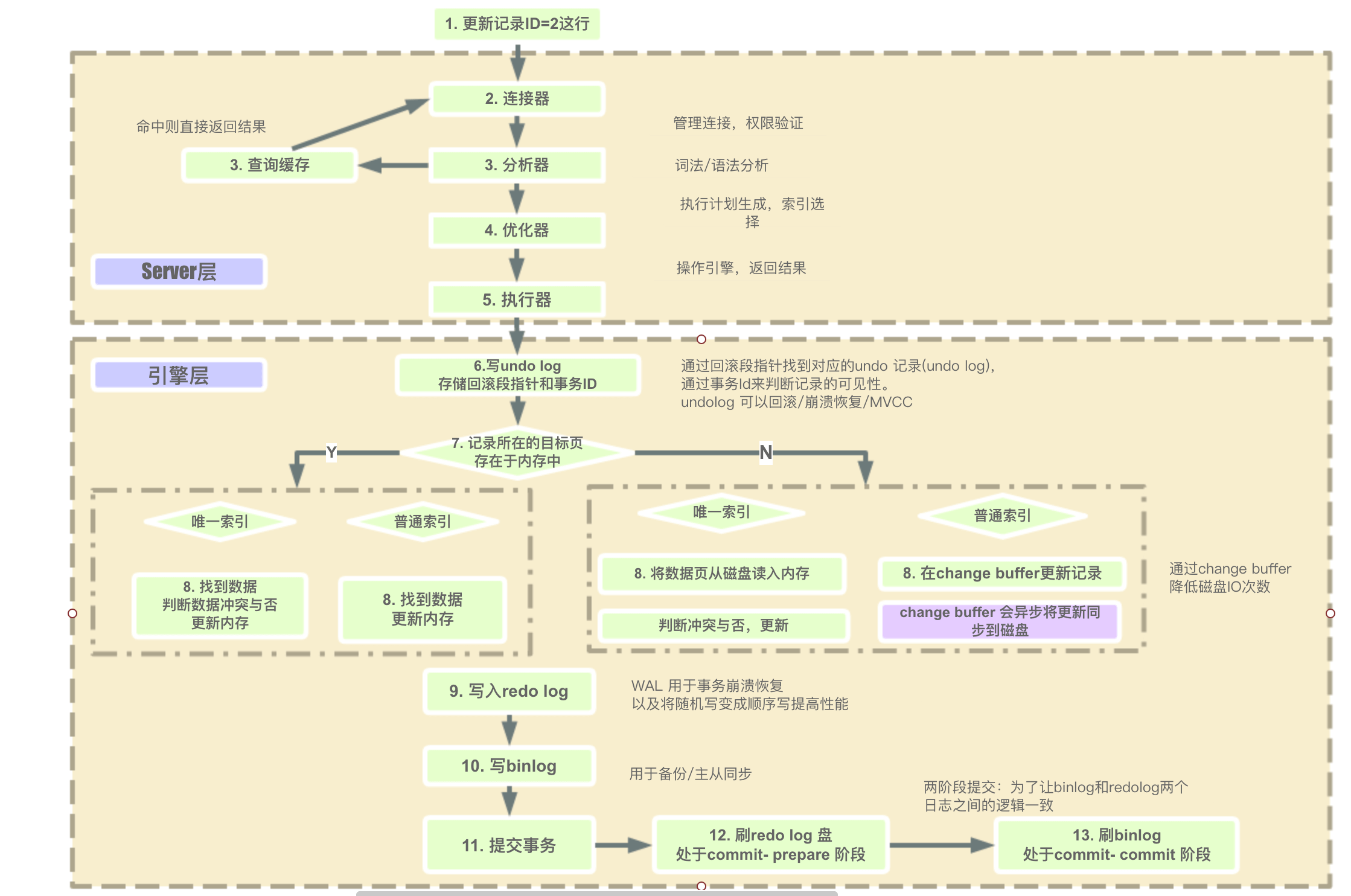
(1)连接,分析,优化,执行
客户端与MySQL Server建立连接,发送语句给MySQL Server,接收到后如果是查询语句会先去查询缓存中看,有的话就直接返回了,(新版本的MySQL已经废除了查询缓存,命中率太低了),如果是缓存没有或者是非查询语句,会进行语法分析并创建一个解析树,然后进行优化,(解析器知道语句是要执行什么,会评估使用各种索引的代价,然后去使用索引,以及调节表的连接顺序)然后调用innodb引擎的接口来执行语句。
(2)写undo log
innodb 引擎首先开启事务,获得一个事务ID(是一直递增的),根据执行的语句生成一个反向的语句,(如果是INSERT会生成一条DELETE语句,如果UPDATE语句就会生成一个UPDATE成旧数据的语句),用于提交失败后回滚,将这条反向语句写入undo log,得到回滚指针,并且更新这个数据行的回滚指针和事务id。(事务提交后,Undo log并不能立马被删除,而是放入待清理的链表,由purge 线程判断是否有其他事务在使用undo 段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间,简单的说就是看之前的事务是否提交成功,这个事务及之前的事务都提交成功了,这部分undo log才能删除)
(3)从索引中查找数据
根据索引去B+树中找到这一行数据(如果是普通索引,查到不符合条件的索引,会把所有数据查找出来,唯一性索引查到第一个数据就可以了)
(4)更新数据
判断数据页是否在内存中?
- 数据页在内存中。若为普通索引,直接更新内存中的数据页;若为唯一性索引,判断更新后是否会数据冲突(不能破坏索引的唯一性),不会的话就更新内存中的数据页。
- 数据页不在内存中。若为普通索引,将对数据页的更新操作记录到change buffer,在下一次查询时需要访问这个数据页时,再执行change buffer中的操作对数据页进行更新。(或者是在MySQL Server空闲时,会将change buffer中所有操作更新到磁盘,也就是俗称的‘刷页’。);若为唯一性索引,因为需要保证更新后的唯一性,所以不能延迟更新,必须把数据页从磁盘加载到内存,然后判断更新后是否会数据冲突,不会的话就更新数据页。
(5)写redo log(prepare状态)
将对数据页的更改写入到redo log,此时redo log中这条事务的状态为prepare状态。
(6)写bin log(同时将redo log设置为commit状态)
更新时,先改内存中的数据页,将更新操作写入redo log日志,此时redo log进入prepare状态,然后通知MySQL Server执行完了,随时可以提交,MySQL Server将更新的SQL写入bin log,然后调用innodb引擎接口将redo log设置为提交状态,更新完成。
WAL(Write-Ahead Log)
Write-ahead Log的思路:先在内存中提交事务,然后写日志(所谓的Write-ahead Log),然后后台任务把内存中的数据异步刷到磁盘。日志是顺序地在尾部Append,从而也就避免了一个事务发生多次磁盘随机 I/O 的问题。明明是先在内存中提交事务,后写的日志,为什么叫作Write-Ahead呢?这里的Ahead,其实是指相对于真正的数据刷到磁盘,因为是先写的日志,后把内存数据刷到磁盘,所以叫Write- Ahead Log。
具体到InnoDB中,Write-Ahead Log是Redo Log。在InnoDB中,不 光事务修改的数据库表数据是异步刷盘的,连Redo Log的写入本身也是异步的。
write和fsync区别
这里我们首先要明确两个概念和两个参数:
- write:刷盘。指的是MySQL从buffer pool中将内容写到系统的page cache中,并没有持久化到系统磁盘上。这个速度其实是很快的。
- fsync:同步持久化到磁盘。指的是从系统的cache中将数据持久化到系统磁盘上。这个速度可以认为比较慢,而且也是IOPS升高的真正原因。
innodb_flush_logs_at_trx_commit & sync_binlog
innodb_flush_logs_at_trx_commit(redo log):
- 0 :设置为 0 的时候,表示每次事务提交时不进行刷盘操作,每次提交事务都只把redo log留在redo log buffer中
- 1(默认值) :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值),每次提交事务都将redo log 持久化到磁盘上,也就是write+fsync
- 2 :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache ,也就是只write,不fsync
sync_binlog(binlog):
- 0(默认值):当事务提交之后,将binlog 从binlog cache中 write到磁盘上,不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让File system自行决定什么时候来做同步,或者cache满了之后才同步到磁盘,性能最佳;
- 1:当每进行1次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘,是最慢的,但是最安全;
- N:每次提交事务都将binlog write到磁盘上,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
参考:MySQL日志(redo log、binlog)刷盘策略 - Philosophy - 博客园 (cnblogs.com)
二阶段提交
正常情况下两阶段提交配合组提交的流程如下:
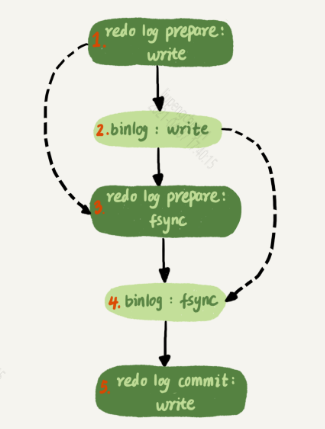
在双一模式下的流程,每个事务提交时都需要进行fsync刷盘,其执行过程才如上图所示。然而在配合两个参数sync_binlog和innodb_flush_log_at_trx_commit,上图会有所调整。
innodb_flush_log_at_trx_commit在非1的情况下,步骤三可以忽略:
- innodb_flush_log_at_trx_commit=0,redo log日志条目写入到redo log buffer中,MySQL即认为redo log已完成写入,即redo log prepare状态,可以进行下一步动作。
- innodb_flush_log_at_trx_commit=2,redo log日志条目写入到文件系统缓存page cache,MySQL即认为已完成redo log完成写入,即redo log prepare状态,可以进行下一步动作。此时的刷盘由MySQL的后台主线程和操作系统层进行完成。
sync_binlog在非1的情况下,步骤四可以进行忽略:
- sync_binlog=0,binlog只需要写入到binlog cache即可进行下一步,此刻MySQL会认为binlog已完成写入,redo log和binlog达成一致,redo log可以commit。
- sync_binlog=N(N>1),每个事务的binlog都写入到binlog cache,攒够N个事务之后,集中fsync刷盘(由后台主线程处理),此刻MySQL会认为binlog已完成写入,redo log和binlog达成一致,redo log可以commit。
那么两段提交过程中失败会发生什么结果呢?MySQL又是怎样处理的呢?
首先我们先放一下两段提交的图:
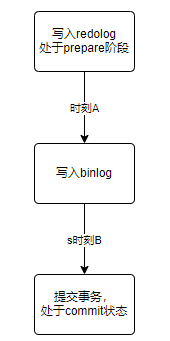
接下来,我们就一起分析一下在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象。
如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了崩溃(crash),由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库。
如果在图中在时刻 B,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?
我们先来看一下崩溃恢复时的判断规则:
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
- 如果是,则提交事务;
- 否则,回滚事务。
这里,时刻 B 发生 crash ,崩溃恢复过程中事务会被提交。
那么问题又来了,MySQL是如何判断binlog是不是完整的呢?
我们都知道binlog有三种格式statement、row、mix。其中mix是前两种方式的组合,一个事务的binlog是有完整的格式的,
- statement 格式的 binlog,最后会有 COMMIT;
- row 格式的 binlog,最后会有一个 XID event。
另外,在 MySQL 5.6 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现。所以,MySQL 还是有办法验证事务 binlog 的完整性的。
而且redolog和binlog有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:如果碰到既有 prepare、又有 commit 的 redo log,就直接提交; 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。这样在两段提交的前提下就能完全保证事务的特性了。















 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









