






Numpy数据分析04——数据类型和文件操作
一、numpy数据类型
数据类型:
| 名称 | 描述 | 名称 | 描述 |
|---|---|---|---|
| bool_ | 布尔数据类型(True或者False) | float_ | float64类型的简写 |
| int_ | 默认的整数类型(类似于C语言中的long,int32或者int64) | float16/32/64 | 半精度浮点数:1个符号位,5个指数位,10个尾数位;单精度浮点数:1个符号位,8个指数位,23个尾数位;双精度浮点数:1个符号位,11个指数位,52个尾数位 |
| intc | 和C语言的int类型一样,一般是int32或int64 | complex | 复数类型,与complex128类型相同 |
| intp | 用于索引的整数类型(类似于C的ssize_t,通常为int32或int64) | complex64/128 | 复数,表示双32位浮点数(实数部分和虚数部分);复数,表示双64位浮点数(实数部分和虚数部分) |
| int8/16/32/64 | 代表与1字节相同的8位整数;代表与2字节相同的16位整数;代表与4字节相同的32位整数;代表与8字节相同的64位整数 | str_ | 表示字符串类型 |
| uint8/16/32/64 | 代表1字节(8位)无符号整数;代表与2字节相同的16位整数;代表与4字节相同的32位整数;代表与8字节相同的32位整数 | string_ | 表示字节串类型,也就是bytes类型 |
# 将数组中的类型存储为浮点型
a = np.array([1,2,3,4],dtype=np.float64)
a

# 将数组中的类型存储为布尔类型
a = np.array([0,1,2,3,4],dtype=np.bool_)
print(a)
b = np.array([1,2,3,4],dtype=np.float_)
print(b)

# str和string的区别
str1 = np.array([1,2,3,4,5,6],dtype=np.str_) # Unicode类型
string1 = np.array([1,2,3,4,5,6],dtype=np.string_) # 数据是byte类型
str2 = np.array(['我们',2,3,4,5,6],dtype=np.str_)
print(str1,str1.dtype)
print(string1,string1.dtype)
print(str2,str2.dtype)
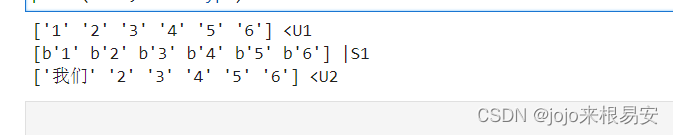
在内存中统一使用Unicode编码,记录到硬盘或者编辑文本的时候都转换成了utf-8。UTF-8将Unicode编码后的字符串保存到硬盘的一种压缩编码方式。
二、numpy结构化数据类型
定义结构化数据
使用数据类型标识码:
| 字符 | 对应类型 |
|---|---|
| b | 代表布尔类型 |
| i | 带符号整型 |
| u | 无符号整型 |
| f | 浮点型 |
| c | 复数浮点型 |
| m | 时间间隔(timedelta) |
| M | datetime(日期时间) |
| O | Python对象 |
| S,a | 字节串(S)与字符串(a) |
| U | Unicode |
| V | 原始数据(void) |
还可以将两个字符作为参数传递给数据类型的构造函数。此时,第一个字符表示数据类型,第二个字符表示该类型在内存中占用的字节数(2、4、8分别代表精度为16、32、64位的浮点数)
# 首先创建结构化数据类型
# 自己创建一个数据类型名为dt,数据的列名是age,数据类型是i1,即带符号整型,占用1个字节
dt = np.dtype([('age','i1')])
print(dt)
# 将数据类型应用于ndarray对象
students = np.array([(18),(19)],dtype=dt)
print(students,students.dtype,students.ndim)
print(students['age'])
运行结果:

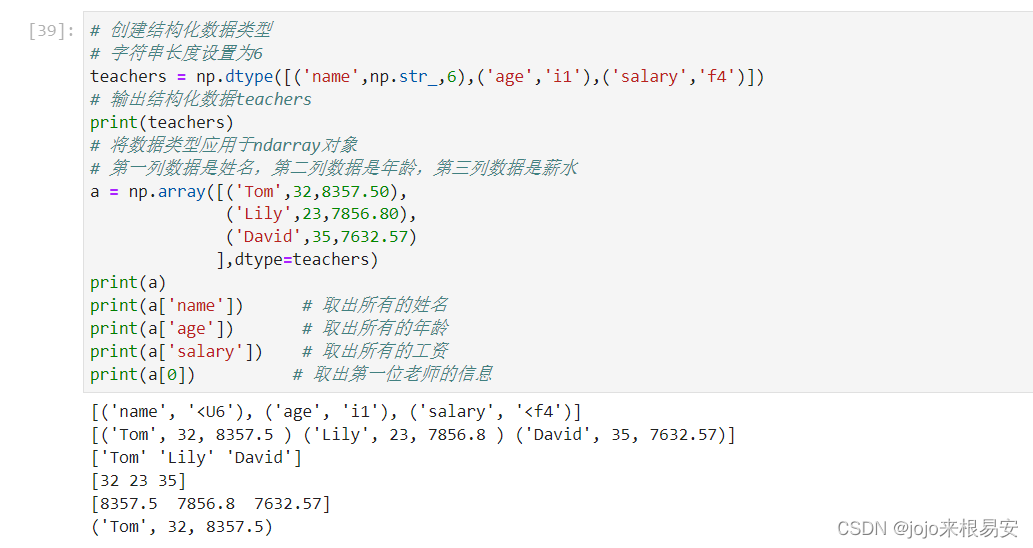
以下示例描述一位老师的姓名、年龄、工资的特征,该结构化数据包含以下字段
- str字段:name
- int字段:age
- float字段:salary
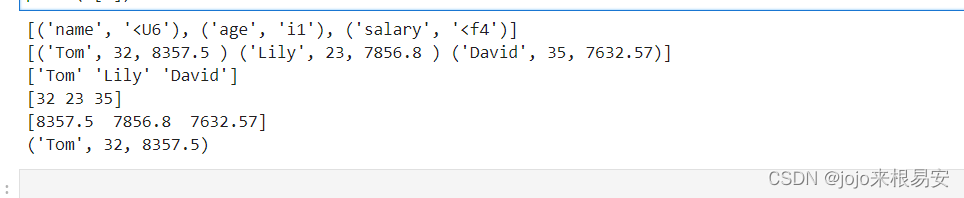
# 创建结构化数据类型
# 字符串长度设置为6
teachers = np.dtype([('name',np.str_,6),('age','i1'),('salary','f4')])
# 输出结构化数据teachers
print(teachers)
# 将数据类型应用于ndarray对象
# 第一列数据是姓名,第二列数据是年龄,第三列数据是薪水
a = np.array([('Tom',32,8357.50),
('Lily',23,7856.80),
('David',35,7632.57)
],dtype=teachers)
print(a)
print(a['name']) # 取出所有的姓名
print(a['age']) # 取出所有的年龄
print(a['salary']) # 取出所有的工资
print(a[0]) # 取出第一位老师的信息
运行结果:
三、数据类型长度
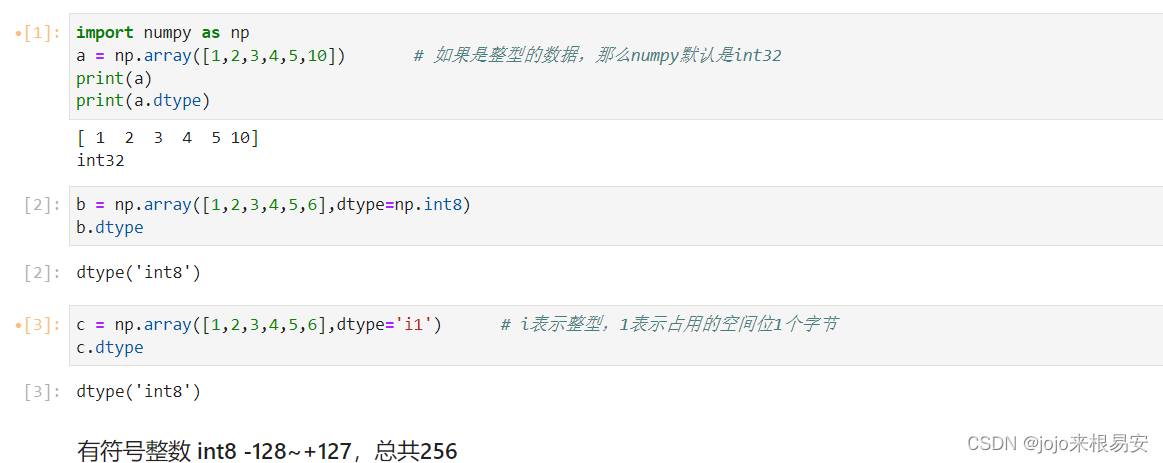
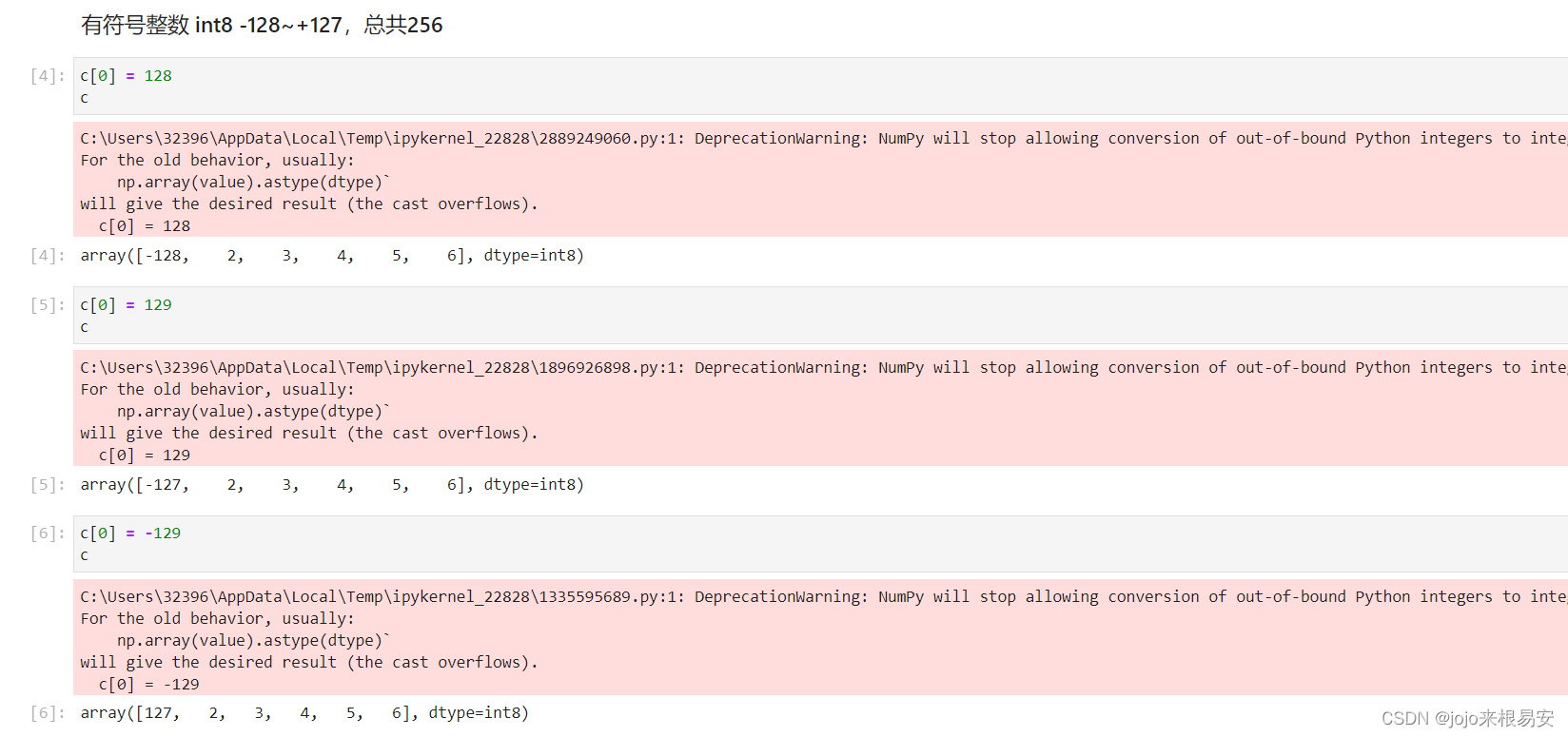
整数类型长度的选择:
字符串类型长度的选择:
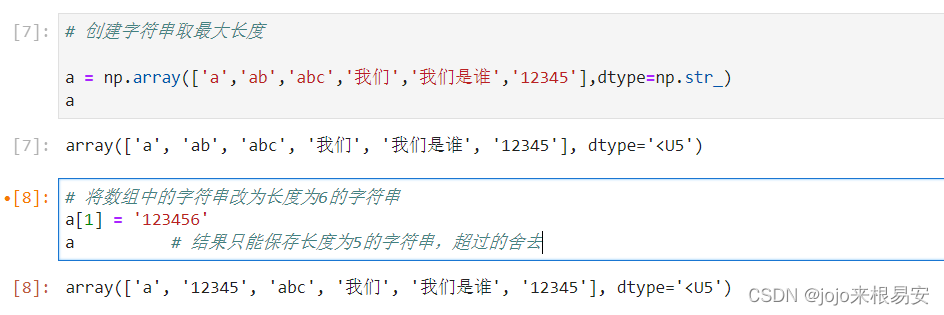
-
创建字符串数组时,会取最大长度

-
当修改内部元素时,也最多只能保存长度为5的字符串,超过的舍去
-
创建字符串数组时设置最大长度(定长)
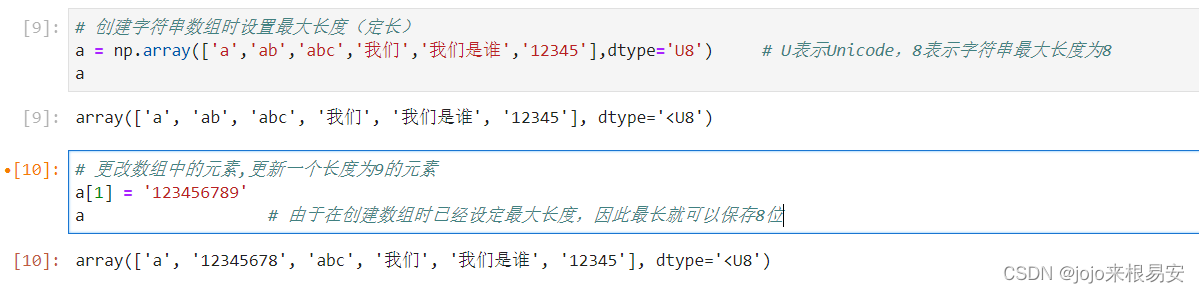
-
使其接受可变长度的字符,修改str为object数据类型即可

定长不灵活但效率高,可变长度灵活但效率低。
四、numpy类型和类型标识码
当创建结构化数据类型时,如果使用的时numpy数据类型,如np.str_,则需要3个参数,第一个就是该列数据的名称,第二个时numpy数据类型,第三个是占用的空间,如(‘name’,np.str_,2)。如果使用的是类型标识码,则只需要2个参数,将标识码和占用字节空间写在一起,如(‘age’,‘i1’)。
五、numpy文件操作
loadtxt读取txt文本、csv文件。
loadtxt(fname,dtype=<type 'float'>,comments='#',delimiter=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0,encoding='bytes')
参数:
- fname:指定文件名称或字符串。支持压缩文件,包括gz、bz格式。
- dtype:数据类型,默认float。
- comments:字符串或字符串组成的列表。表示注释字符集开始的标志,默认为#。
- delimiter:字符串、分隔符。
- converters:字典。将特定列的数据转换为字典中对应的函数的浮点型数据。例如将空值转换为0,默认为空。
- skiprows:跳过特定行数据。例如跳过前1行(可能是标题或注释,从第一行开始数),如果要跳过前3行,则skiprows=3。默认为0
- usecols:元组。用来指定要读取数据的列,第一列为0.例如(1,3,5),默认为空。
- unpack:布尔型。指定是否转置数组,如果为真则转置,默认为False。
- ndmin:整数型。指定返回的数组至少包含特定维度的数组,值域为0、1、2,默认为0。
- encoding:编码,确认文件时gbk格式还是utf-8格式。
5.1 读取普通文件
data1.txt中的数据:

# 读取普通文件,可以不用设置分隔符(空格、制表符)
import numpy as np
data = np.loadtxt('./data1.txt')
print(data,data.shape)
运行结果:

注释掉data1中的第二行数据后(在这一行数据前增加一个#),运行结果是:

5.2 读取CSV文件
CSV文件默认使用逗号作为分隔符
csv_test.csv文件:
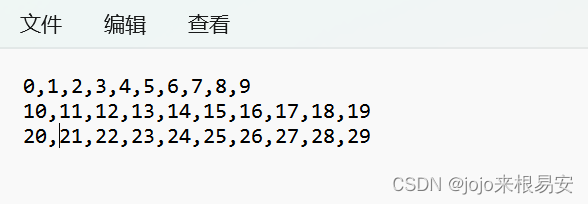

读取文件:
#读取CSV文件,需要设置分隔符,csv默认使用逗号进行分隔
data = np.loadtxt('./csv_test.csv',dtype=np.int32,delimiter=',')
print(data,data.shape)
运行结果:

如果不加上delimiter(分隔符)参数,就会报错,因为我们在读取文件时设置的数据类型是dtype=np.int32,而不设置delimiter则会将csv文件中的每一行都读取为一个字符串,无法将字符串类型转换为int32类型。
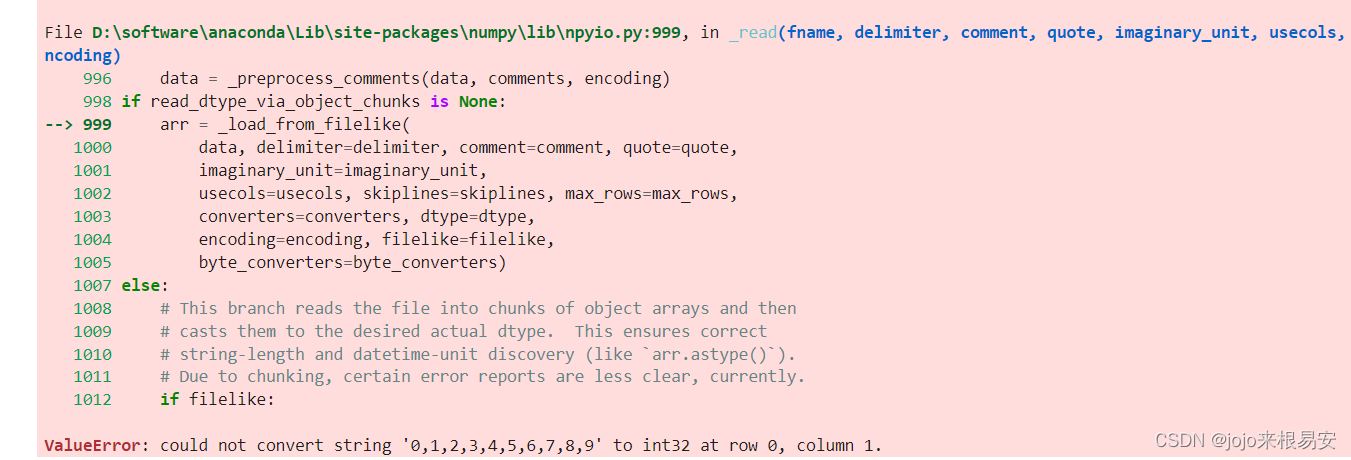
5.3 数据读取——不同列标识不同信息
对于不同列数据类型不相同的情况,我们可以自定义数据结构,也可以在读取数据时令dtype=object,object可以接收任意类型的数据。
文件has_title.txt (使用空格作为分隔符):

(1) 读取数据
- 由于不同列数据的类型和含义不同,所以在读取数据时的dtype就不能使用单一类型,这时我们可以自行定义数据结构。
- 使用skiprows参数可以在读取数据时跳过指定的行数(从第一行开始数),如果要跳过前两行,则令skiprows=2。
# 1.以上数据由于不同列数据标识的含义和类型不同,因此需要自定义数据类型
user_info = np.dtype([('name','U10'),('age','i1'),('gender','U1'),('height','i2')])
print(user_info)
# 2.使用自定义的数据类型 读取数据
# 该文件的第一行是每一列的列名,在读取文件时不需要读取,用skiprows跳过第一行
data = np.loadtxt('has_title.txt',dtype=user_info,skiprows=1,encoding='utf-8')
print(data)
运行结果:

(2)读取列数据
在读取数据时只取某一列数据或者其中几列数据——使用usecols参数
- 如果只读取一列数据,则直接令usecols等于该列的索引值;
- 如果要读取多列数据,则需要将列的索引值封装到元组中。注意,如果这些列的数据类型不相同,还是需要自定义数据结构。如果类型相同,如,都是int类型,那么直接令dtype=int。
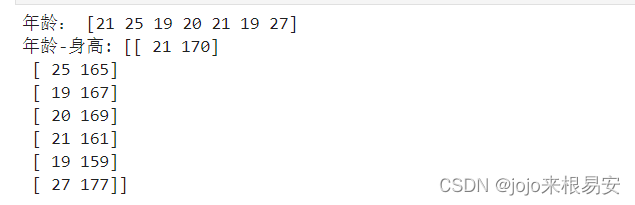
# 在读取数据时只取某一列数据或者其中几列数据——使用usecols参数
ages = np.loadtxt('has_title.txt',dtype=int,skiprows=1,usecols=1,encoding='utf-8') # 读取第二列数据
age_height = np.loadtxt('has_title.txt',dtype=int,skiprows=1,usecols=(1,3),encoding='utf-8') # 读取第二列和第四列数据,年龄和身高的数据类型都可以是int类型
print('年龄:',ages)
print('年龄-身高:',age_height)
运行结果:
读取的列的数据类型不同时,自定义数据结构:
# 读取指定的列 usecols = (0,1,3)表示只读取第2列和第4列
user_info = np.dtype([('name','U10'),('age','i1'),('height','i2')])
print(user_info)
# 使用自定义的数据类型 读取数据
data = np.loadtxt('has_title.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(0,1,3),encoding='utf-8')
print(data)
运行结果:

计算用户的平均年龄:
'''
计算平均年龄
'''
# 获取年龄的数组
ages = data['age']
ages_mean = ages.mean()
print('用户的年龄:',ages)
print('用户的平均年龄是:',ages_mean)
运行结果:

(3)通过布尔索引取值——计算女性用户的平均身高:
# 计算女生的平均身高
# 生成一个数组,如果是男性则为False,女性则为True
isfemale = data['gender']=='女'
print(isfemale)
print('用户的身高:',data['height'])
# 通过布尔索引来取数组的值
female_height = data['height'][isfemale]
print('女性用户的身高:',female_height)
# 计算平均值
print('女性用户的平均身高:')
female_height.mean()
运行结果:

(4) 数据中存在空值进行处理
需要借助converters参数,传递一个字典,key为列索引,value为对列中数据的处理。
比如:
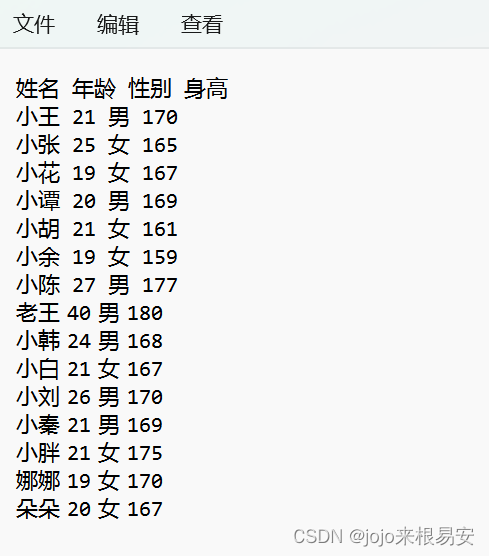
csv中学生信息中存在空的年龄信息:
姓名 年龄 性别 身高
小王 21 男 170
……
小谭 男 169
……
小陈 27 男 177
文件:has_empty_data.csv
定义一个函数对异常进行处理:
# 处理空数据,需要创建一个函数,接收列的参数,并加以处理
def parse_age(age):
try:
return int(age) # 将字符串转换为整型
except:
return 0 # 出现异常(空值)则转换为0
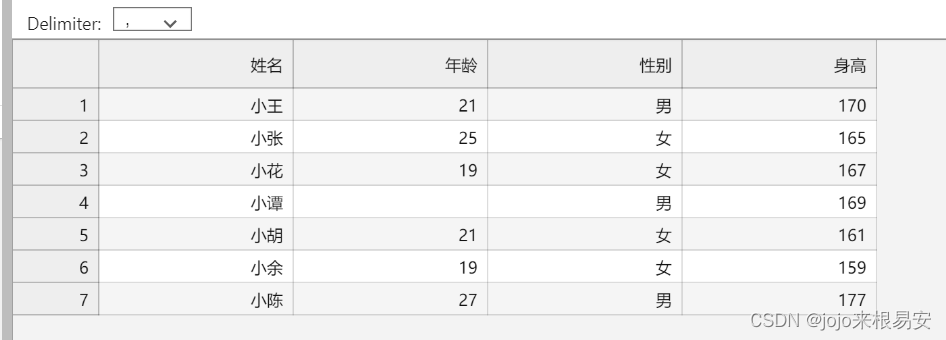
读取有缺失数据的列的数据:
# 1.以上数据由于不同列数据标识的含义和类型不同,因此需要自定义数据类型
user_info = np.dtype([('name','U10'),('age','i1'),('gender','U1'),('height','i2')])
print(user_info)
# 2.使用自定义的数据类型 读取数据
# 该文件的第一行是每一列的列名,在读取文件时不需要读取,用skiprows跳过第一行
# 读取第2列数据,该列有缺失值,需要使用converters参数对缺失值进行处理,否则会报错
# converters的值是一个字典,每一对键值对中的键表示要处理的列的索引,对应的value表示对列进行处理的函数
data = np.loadtxt('has_empty_data.csv',delimiter=',',skiprows=1,usecols=1,encoding='utf-8',converters={1:parse_age})
print(data)
运行结果:
可以看到,该列中的缺失值已经被函数处理为0。
















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









