







本次以"李子柒"的微博账号为例,进行微博网页版(https://weibo.com/)相关接口分析与实战。
1. 个人主页基本信息接口分析
- 个人信息抓取示例
| 原网页 | 抓取数据示例 |
|---|---|
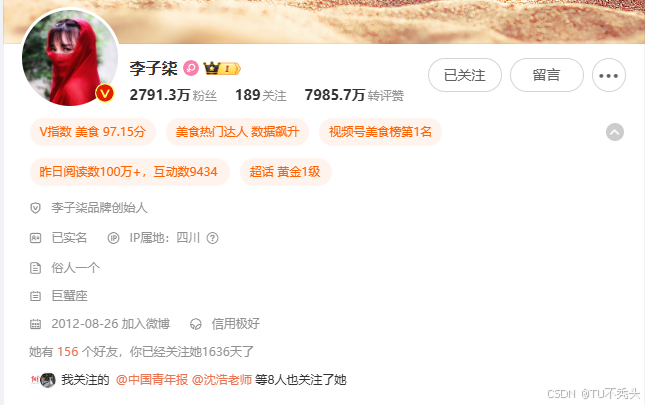 |  |
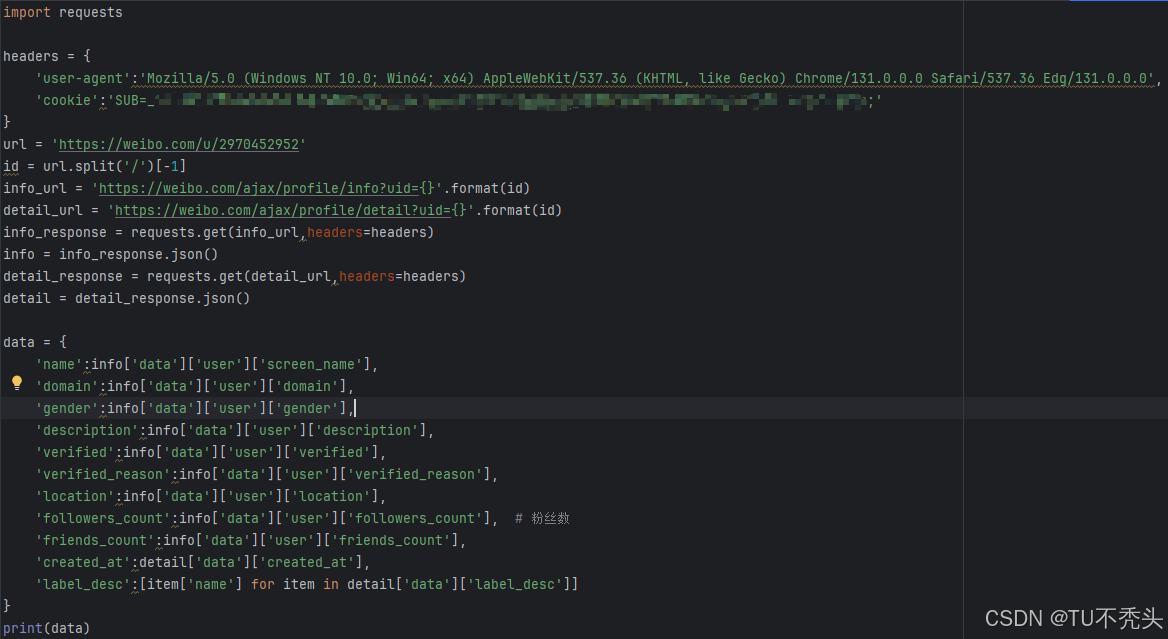
接口分析
网页地址:https://weibo.com/u/2970452952
接口1:https://weibo.com/ajax/profile/info?uid=2970452952
接口2:https://weibo.com/ajax/profile/detail?uid=2970452952

代码示例
在进行个人主页信息抓取的时候,headers需要登录的cookie,但只需要其中SUB=即可。
2. 个人主页微博列表接口分析
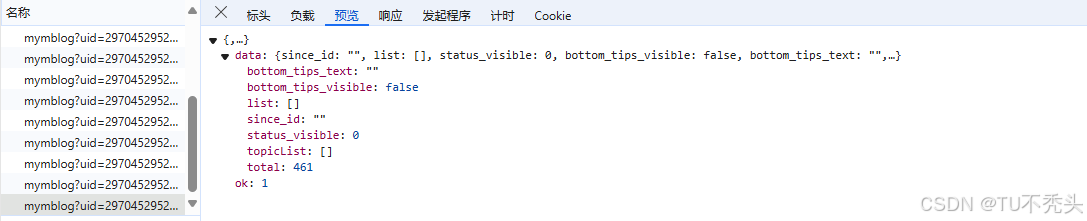
第一页:https://weibo.com/ajax/statuses/mymblog?uid=2970452952&page=1&feature=0
第二页:https://weibo.com/ajax/statuses/mymblog?uid=2970452952&page=2&feature=0&since_id=4542986702291664kp2
由接口返回数据分析,翻页涉及的参数since_id存在于上一页返回的结果
最后一页的since_id = "",因此,可以借助这个条件进行判断是否是最后一页
代码示例
import requests
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
'cookie':your_cookie
}
def parse_mblog(response):
data = response.json()['data']
mblog_list = data['list']
for mblog in mblog_list:
mblog_info = {
'mid': mblog['mid'],
'mblogid': mblog['mblogid'],
'text': mblog['text'], # 文本的HTML样式
'text_raw': mblog['text_raw'], # 文本
'created_at': mblog['created_at'], # 创建时间
'comments_count':mblog['comments_count'], # 评论数
'attitudes_count':mblog['attitudes_count'], # 点赞数
'reposts_count':mblog['reposts_count'], # 转发数
}
print(mblog_info)
def main():
url = 'https://weibo.com/ajax/statuses/mymblog?uid=2970452952&feature=0'
response = requests.get(url, headers=headers)
since_id = response.json()['data']['since_id']
while since_id != "":
parse_mblog(response)
next_url = url + '&since_id=' + since_id
response = requests.get(next_url, headers=headers)
since_id = response.json()['data']['since_id']
main()
3. 某条微博评论接口分析
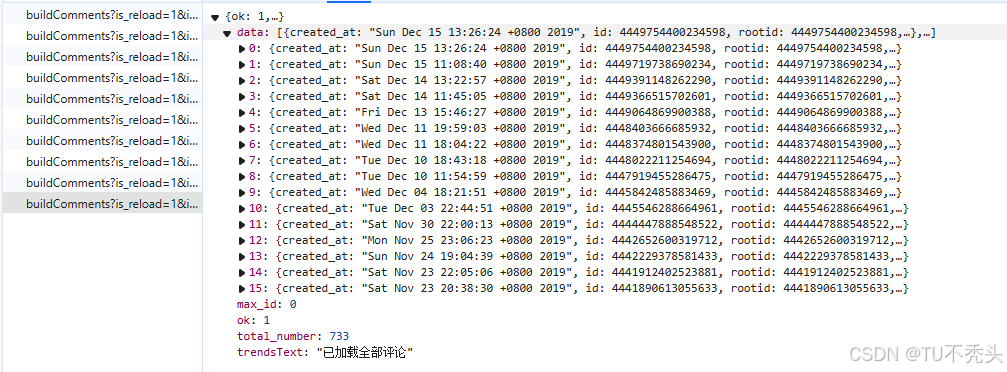
第一页:https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=3957247706865941&is_show_bulletin=0&is_mix=0&count=10&uid=2970452952&fetch_level=0&locale=zh-CN
第二页:https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=3957247706865941&is_show_bulletin=0&is_mix=0&max_id=4751637492798575&count=20&uid=2970452952&fetch_level=0&locale=zh-CN
由接口返回数据分析,翻页涉及的参数max_id存在于上一页返回的结果
- 需要注意的是,评论最后一页即
max_id = 0是data中依旧有部分评论数据,需要与微博列表区分开
代码示例
def parse_comment(response):
comment_list = response.json()['data']
for comment in comment_list:
data = {
'id': comment['id'],
'user_id': comment['user']['id'],
'user_name': comment['user']['screen_name'],
'rootid': comment['rootid'],
'text': comment['text'],
'text_raw': comment['text_raw'],
# 评论的类型,comment评论/comment_reply回复他人评论
'readtimetype':comment['readtimetype'],
'created_at': comment['created_at'],
}
# 如果是回复他人的评论,则会产生reply_comment字段,用于记录被评论的信息:评论文本信息、被评论人的用户信息等
if data['readtimetype'] == 'comment_reply':
data.update(
{
'reply_user_id': comment['reply_comment']['user']['id'],
'reply_user_name': comment['reply_comment']['user']['screen_name'],
}
)
print(data)
def main():
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=3957247706865941&is_show_bulletin=0&is_mix=0&count=10&uid=2970452952&fetch_level=0&locale=zh-CN'
response = requests.get(url,headers=headers)
max_id = response.json()['max_id']
parse_comment(response)
while max_id != 0:
print(max_id)
next_url = url + '&max_id=' + str(max_id)
response = requests.get(next_url,headers=headers)
parse_comment(response)
max_id = response.json()['max_id']
main()

















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









