







 本文详述如何使用MindStudio搭建环境,获取并转换PaddlePaddle的en_PP-OCRv3_rec模型,进行数据预处理、模型转换、推理及精度验证的全过程。
本文详述如何使用MindStudio搭建环境,获取并转换PaddlePaddle的en_PP-OCRv3_rec模型,进行数据预处理、模型转换、推理及精度验证的全过程。
本文主要介绍通过MindStudio全流程开发工具链,将PaddlePaddle模型转成om模型,并在昇腾环境上进行推理的流程。
一、MindStudio环境搭建
通过MindStudio官网介绍可以学习了解MindStudio的功能,以及按照MindStudio用户手册进行安装和使用。
官网链接:
用户手册:
1.1 MindStudio软件下载
在官网首页中点击“立即下载”,如下图。
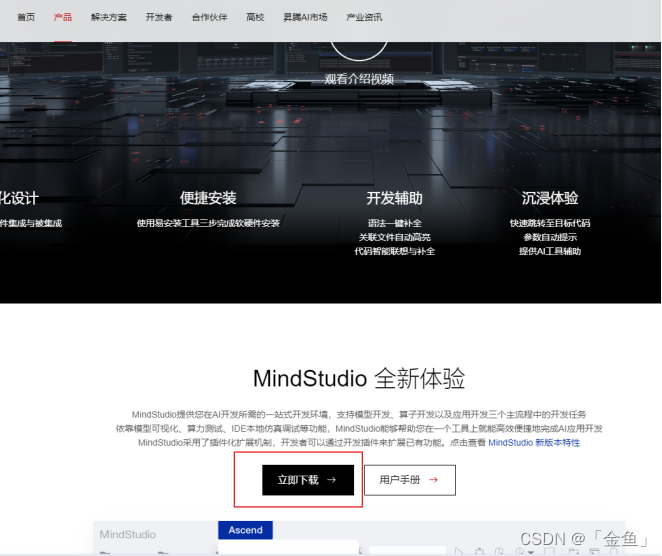
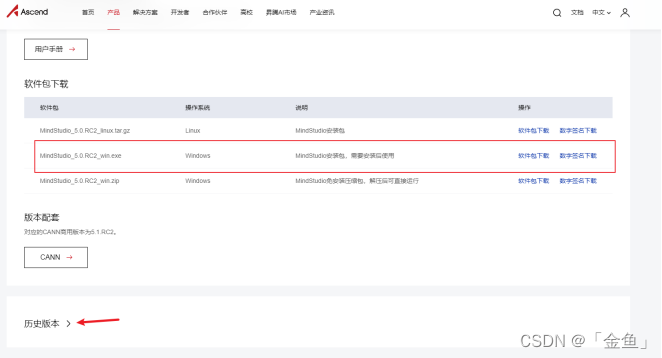
然后我们进入版本选择界面,可以根据自己的操作系统、安装方式选择不同的软件包,我们这里选择的是MindStudio_5.0.RC2_win.exe,进行下载安装。
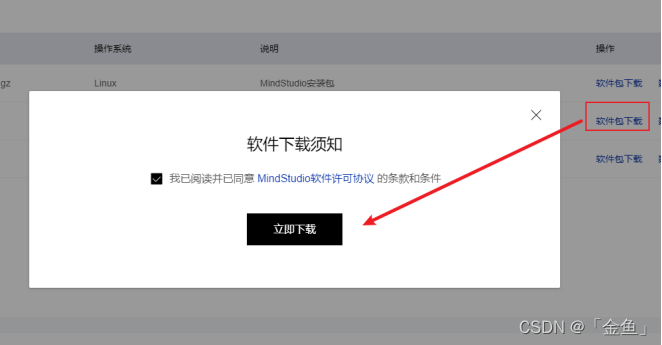
点击对应的“软件包下载”,弹出软件下载需知对话框,勾选“我已阅读并已同意 MindStudio软件许可协议 的条款和条件”,然后点击“立即下载”进入下载流程。
1.2 MindStudio软件安装
双击打开下载好的MindStudio_5.0.RC2_win.exe软件包,进入安装流程:

欢迎界面,点击“Next”
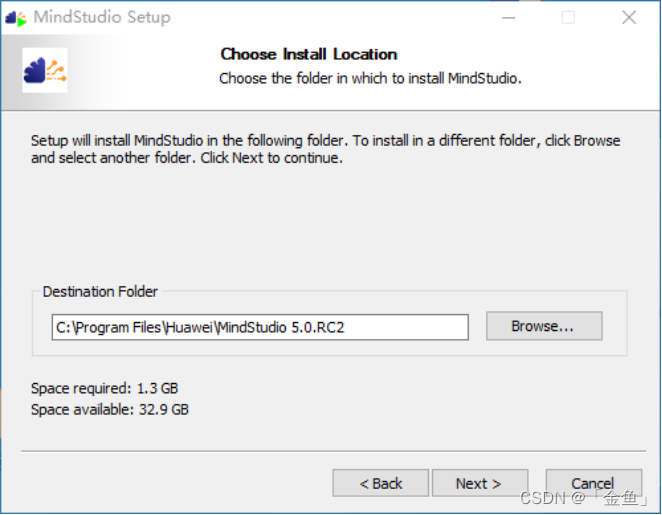
选择安装路径,我们使用的是默认安装路径,然后点击“Next”。
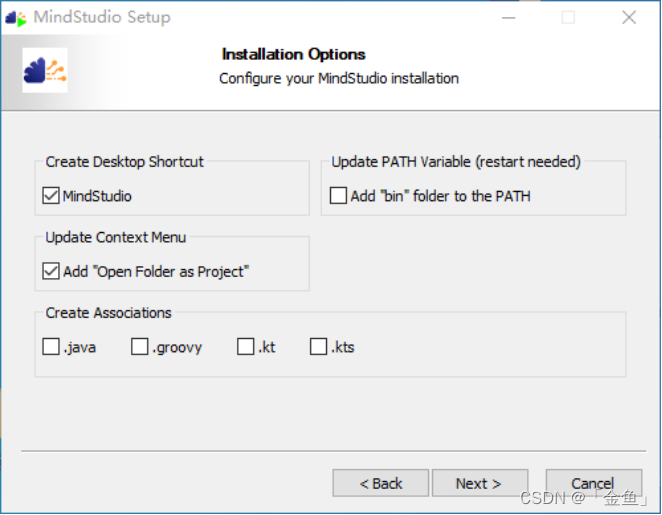
安装配置,我们只勾选了创建桌面快捷方式,和以工程方式打开文件夹添加到右键菜单中。然后点击“Next”。
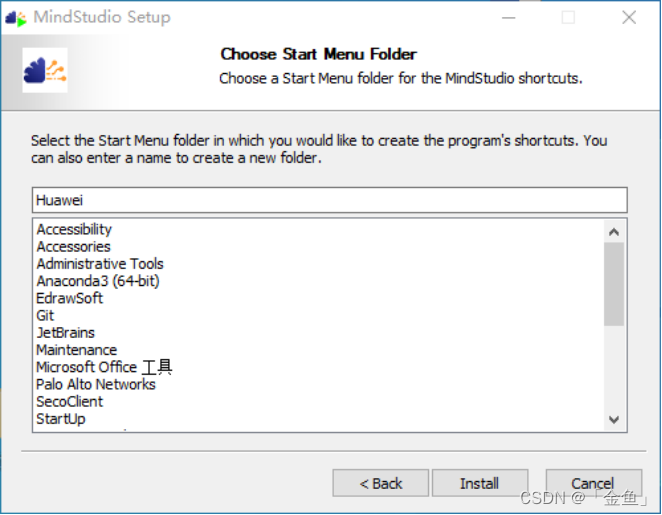
启动菜单文件夹我们使用默认配置,点击“Install”,程序进入自动安装步骤。
安装完成后点击“Finsh”完成安装。
1.3 MindStudio环境搭建
通过桌面快捷方式启动MindStudio。
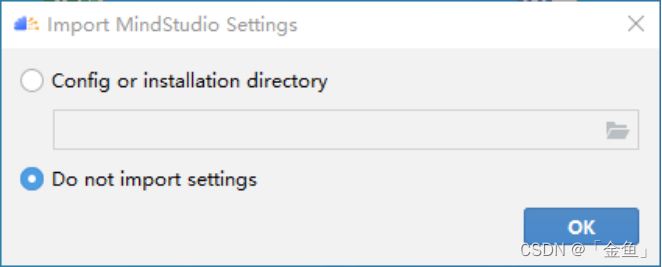
选择不导入配置,点击“OK”
Projects标签用于工程打开、创建等。
Customize标签用于IDE配置,包括界面、字体大小等。
Plugins标签用于管理插件的安装、删除等。
Learn MindStudio标签可以通过点击“Help”进入官方社区获取帮助。
在Projects标签下点击“New Project”创建一个新的工程。
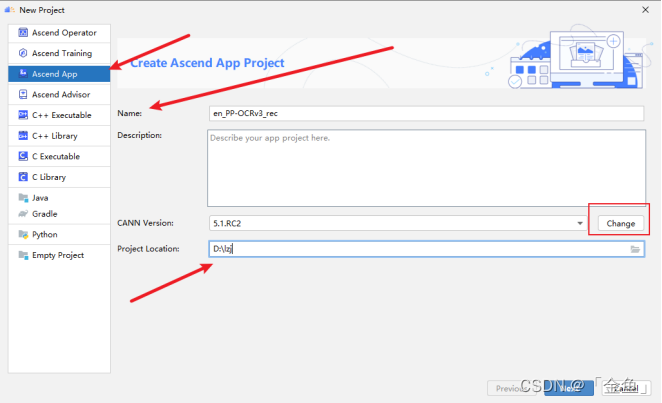
选择Ascend App,输入工程名、和工程目录,点击“Change”选择或者添加CANN版本。
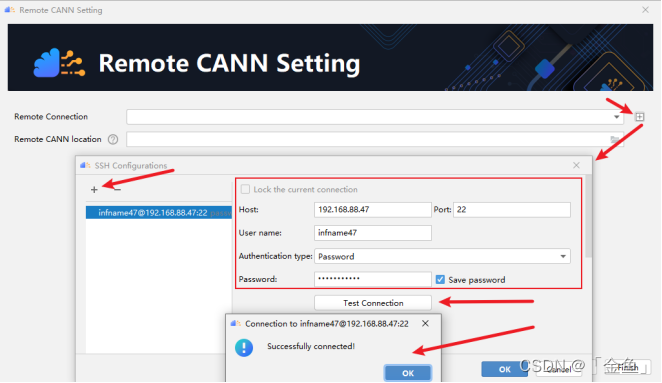
点击Remote CANN Setting对话框中的加号,弹出SSH Configurations对话框,然后点击其中的加号,填写红框中的服务器信息,点击“Test Connection”弹出连接成功对话框。
依次点击“OK”完成Remote Connection配置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









