







 本文介绍了深度学习分类任务中的基础概念,如正样本和负样本,并重点探讨了困难样本挖掘的重要性,特别是在目标检测中的作用。通过离线和在线两种方法解释了如何挖掘难分正样本和负样本,特别是在线难例挖掘(OHEM)策略在Fast R-CNN中的应用,以提高模型训练效果。此外,文章还提到了在mmdetection框架中实现困难样本挖掘的策略。
本文介绍了深度学习分类任务中的基础概念,如正样本和负样本,并重点探讨了困难样本挖掘的重要性,特别是在目标检测中的作用。通过离线和在线两种方法解释了如何挖掘难分正样本和负样本,特别是在线难例挖掘(OHEM)策略在Fast R-CNN中的应用,以提高模型训练效果。此外,文章还提到了在mmdetection框架中实现困难样本挖掘的策略。
分类中的一些基础概念:
- 正样本:包含我们想要识别类别的样本,例如,我们在做猫狗分类,那么在训练的时候,包括猫或者狗的图片就是正样本
- 负样本:在上面的例子中,不包含猫或者狗的其他所有的图片都是负样本
- 难分正样本(hard positives):易错分成负样本的正样本,对应在训练过程中损失最高的正样本,loss比较大(label与prediction相差较大)。
- 难分负样本(hard negatives):易错分成正样本的负样本,对应在训练过程中损失最高的负样本**
- 易分正样本(easy positive):容易正确分类的正样本,该类的概率最高。对应在训练过程中损失最低的正样本
- 易分负样本(easy negatives):容易正确分类的负样本,该类的概率最高。对应在练过程中损失最低的负样本。
**举例补充:**如果roi里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫easy negative;如果roi里有二分之一个物体,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是had negative。
为什么要进行困难样本挖掘?
在区域提议(Region Proposal) 的目标检测算法中,负样本的数量会远高于正样本的数量,其中大部分都是对网络训练作用相对较小的易分负样本(easy negatives)。根据Focal Loss论文的统计,一般包含少量信息的“easy examples”(基本都是负例),与包含有用信息的“hard examples”(正例+难负例)之比为100000:100!这导致这些简单例的损失函数值将是难例损失函数的40倍!

由于正样本数量一般较少,所有对于困难样本挖掘(hard example mining)一般是指难负例挖掘(Hard Negative Mining)。
为了让模型正常训练,我们必须要通过某种方法抑制大量的简单负例,挖掘所有难例的信息,这就是难例挖掘的初衷。即在训练时,尽量多挖掘些难负例(hard negative)加入负样本集参与模型的训练,这样会比easy negative组成的负样本集效果更好。
关于hard negative mining,比较生动的例子是高中时期你准备的错题集。错题集不会是每次所有的题目你都往上放。放上去的都是你最没有掌握的那些知识点(错的最厉害的),而这一部分是对你学习最有帮助的。
方法:离线和在线
离线:
在样本训练过程中,会将训练结果与GroundTruth计算IOU。通常会设定一个阈值(0.5),结果超过阈值认为是正样本,低于一定阈值的则认为是负样本,然后扔进网络中训练。
但是,随着训练的进行,这样的策略也许会出现一个问题,那就是正样本的数量会远远小于负样本,这样会导致数据的分布不平衡,使得网络的训练结果不是很好。
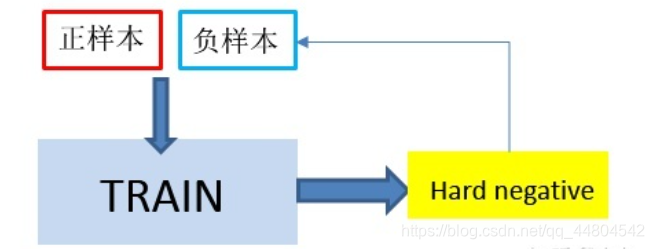
当然有些论文作者针对这种导致不平衡的数据,提出了一种对称的模型。就是类似上图,将Hard Posiotive也重新赋给正样本。
在线:
CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)将难分样本挖掘(hard example mining)机制嵌入到SGD算法中,使得Fast R-CNN在训练的过程中根据region proposal的损失自动选取合适的Region Proposal作为正负例训练。
上面的论文就是讲的在线的方法:Online Hard Example Mining,简称OHEM
实验结果表明使用OHEM(Online Hard Example Mining)机制可以使得Fast R-CNN算法在VOC2007和VOC2012上mAP提高 4%左右。
即:训练的时候选择hard n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8080
8080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









