







最近学习了Q-learning的几个小例子,研读了一下代码,再结合自己的理解简单写一下,方便之后回顾学习
Q-learning是强化学习里面最基础的算法,属于时间差分法,也是free-model(现实中大部分环境都是属于免模型情况)
这里只写一写之前不太理解的地方,详细的建议去看莫烦python老师的教程
首先对于q值的理解,Q-learning中q值是存储在q-table中的,q值表示的是(状态,动作)对的值,通俗说就是在当前状态下采取动作能带来的价值,而Q-learning的目的就是不断去更新q表,之前看到一句话说的很好,Q值是可以“一眼看穿未来”的,为什么这么说呢,看一下下面这个更新q表的公式


这里引用一下莫烦老师的图片,因为根据q值更新的公式可以看出,q现实的计算是奖励值加上gamma乘以下一状态的q估计的,所以我们重写一下Q(s1)的公式,展开来看,就是包含后面n个状态的奖励值,也就是未卜先知,一眼看穿未来。
而对于q表,伪代码里说随机设置任意值,而在代码中我们一般初始化为全0,然后逐步更新,这里我原本在跑例子(莫烦老师的寻找宝藏的小例子)的时候有些疑惑,因为我把每个时刻的q表都输出了看了下,发现q表的值是倒着更新的,最后想明白了,是因为只有在获得奖励的状态时更新q表才是有数值的,因为我们要用到下一状态的q值,这时候如果奖励值是0,下一状态的q值也是0的话,那么更新的q值还是0,只有在奖励值不为0时,我们更新的q值才不为0,这样带着更新,在下一个epside的时候,前一个状态就算奖励值是0,但是下一状态的q值不为0了,这时候就又有新的q值更新了。
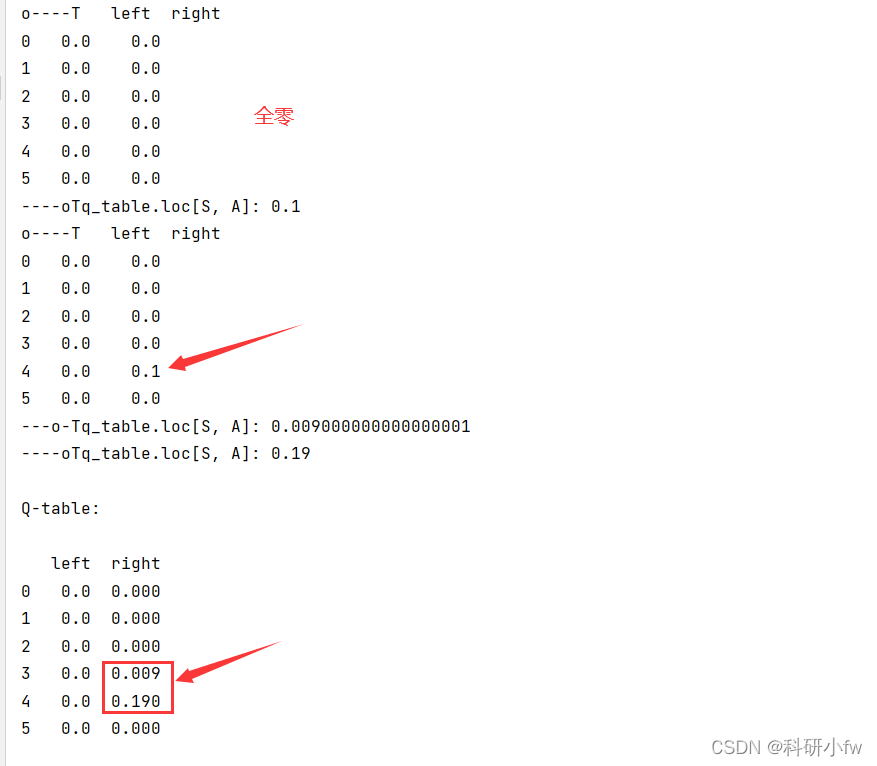
通过看代码,改代码觉得基本算是了解Q-learning了,所以还是要好好去搞懂原理,然后动手撸代码。
学无止境,任重道远。














 2411
2411
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









