







最近在研究多智能体深度强化学习方向方面的论文,想根据不同论文将自己的学习过程记录一下,最近看了MADDPG和COMA这两篇基于AC方法的文章,这篇主要记录下对于MADDPG论的理解。
MADDPG 针对合作竞争混合环境下的多智能体演员评论家算法
(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments)
首先这是一篇17年发表在NISP上的论文,是基于DDPG针对多智能体环境下的改进,而DDPG又是基于经典AC算法解决不容易收敛问题提出的。

对于MADDPG来说,同样是解决的传统强化学习不适用于多智能体的应用环境下,这里我们重点关注一下它的三个主要贡献点

1、首先第一点,集中式训练分布式执行,指的是在训练过程中由critic集中式共享全局信息,执行过程中actor分布式获取局部信息(当前智能体的观察信息),在这里,每个智能体维持一个单独的critic和actor,如下图

2、 其中因为critic需要共享全局信息,就要获取到其他智能体的策略信息,所以又引出了第二点贡献,提出估计其他智能体策略的方法

公式L表示的是代价函数,这里的
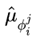
表示的就是智能体i对智能体j的策略估计,当代价函数取得最小值时,这时我们就可以认为Uij就是j的策略。
3、但是针对这种策略估计的方法来说可能会为了过度适应智能体的动作而制定出强有力的策略,也就是说可能会产生过拟合的情况,针对这一点,文章由提出了一个新方法,策略集合优化,也就是将一个策略划分成k个子策略集合的思想,每次从k个子策略中特定选取一个Pk进行执行

文章中也给出了不同的实验分析,对于实验环境,文章设计了不同的场景,包括有合作通信,捕食者-猎物,合作导航,物理欺骗。
 网上也有很多关于MADDPG实验复现的教程,大家可以尝试动手去复现,这里提醒大家一下,MADDPG对于实验的配置要求比较要个,像是python、gym、tensorflow的版本等等,大家多加注意。
网上也有很多关于MADDPG实验复现的教程,大家可以尝试动手去复现,这里提醒大家一下,MADDPG对于实验的配置要求比较要个,像是python、gym、tensorflow的版本等等,大家多加注意。

最后提一点,通过实验发现,当智能体数量增多(大于5个的时候),环境就会出现紊乱情况,智能体不能得到很好的收敛,也就是说MADDPG目前可能并不适用于大规模的多智能体深度强化学习场景下,这个也有人说是因为集中式学习分布式执行导致的,下一步我也准备继续进行学习了解下。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









