







更快的BiSeNet:用于实时语义分割的更快的双边分割网络
提出了一种基于BiSeNetV2的更快的双边分割网络(faster BiSeNet),它以更紧凑的结构促进了空间和语义分支的特征融合,以提高实时性能
尽管BiseNetV2在速度和准确性方面取得了显著进步,但在初始下采样阶段和聚合层仍存在一些冗余,这阻碍了空间和语义分支的信息交换。我们进行了更简洁的设计,以减少冗余网络架构并加强两个分支之间的相互关系。
轻量级设计通过以下方式增强了浅层和深层两个分支之间的相互连接:
1) 浅层特征共享:使用简单的线性运算将空间分支的浅层特征转换为语义分支所需的浅层;
2) 深度特征聚合:引入门控引导聚合层,以引导适当的空间信息,通过门控机制补充语义分支的缺失细节,避免使用不必要的卷积来选择聚合的特征;
3) 辅助边缘丢失:使空间分支的门控输出集中于重要的边界相关信息,这有助于将有价值的边缘信息融合到预测结果中。

实时性能的提高通常会导致准确性的显著下降。因此,如何在不牺牲高分辨率图像输入的太多准确性的情况下提高推理速度是一个具有挑战性的问题。为了解决这个问题,BiSeNet首先提出了一种采用双分支架构的双边分割网络,其中深分支用于捕获高级语义,而浅分支用于学习低级细节。两个分支输出的融合被用作最终的分割结果。深分支采用快速下采样策略以快速扩大感受野。
在深度分支中,对全分辨率输入的执行仅在少数层上使用,这节省了计算成本。浅分支遵循宽通道和浅层的设计,为最终分割结果提供足够的细节。双分支架构在速度和准确性之间取得了很好的平衡。
语义分割网络的两个分支分别为空间分支和语义分支;空间分支用于保留图像数据的浅层空间信息;语义分支用于提取图像数据的深层语义信息;
由于空间分支和语义分支之间存在相似的浅层特征,这里在浅层空间采用特征共享,使用余弦距离来测量特征之间的相似性。通过对相应空间特征的简单线性操作来生成浅语义特征,这使我们能够简化初始下采样阶段。
与我们的方法相比,Fast SCNN直接利用浅层语义特征作为空间分支的输出来实现浅层特征共享,这不能确保空间分支的输入包含足够的详细信息。
设计了一个门控引导聚集层(GGAL)来引导特征聚集。门控机制的添加可以控制适当的信息通过相关的门传播。由于语义分支提供了强语义,但缺少详细信息,因此设计门的原则是在语义输出缺少相应信息时,既发送两个分支的有用信息,又从空间分支接收补充细节。门控机制的设计可以有效地细化预测结果并最小化聚合层中的冗余。
辅助边缘损失优化了空间分支的选通输出,以确保输出包含丰富的空间细节,尤其是边缘信息。详细信息被聚集到最终预测中,该最终预测可以在对象边界周围锐化预测,并在不增加推理复杂性的情况下进一步提高小对象的准确性。
总结如下:
•我们提出了浅层特征共享,以促进信息交换并简化初始下采样阶段。
•我们引入了一种新的门控引导聚合层,该层控制适当的空间信息以补充缺失的细节并减少网络冗余。
•辅助边缘损失促进了边界相关信息的学习,并在不增加任何推理成本的情况下改进了聚合结果。
SEM X-Y表示语义分支下采样中第X阶段的第Y通道......余弦距离(余弦相似度)
用向量空间中两个向量夹角的余弦值 作为衡量两个个体间差异的大小的度量。
当两向量夹角余弦等于1时,这两向量完全重复;
当夹角的余弦值接近于1时,两向量相似;
夹角的余弦越小,两向量越不相关。

所有空间特征图和对应语义特征图之间的五个最小余弦距离在BISENETV2中具有相同分辨率。
根据余弦距离结果得出总结:
一个语义特征图可以至少找到5个相似的空间特征图,所以,可以通过对相应空间特征的简单线性操作来生成浅语义特征,这使我们能够简化初始下采样阶段。
ENet减少了下采样次数,以实现更紧凑的框架和更快的速度。SegNet构建了一个轻量级结构,结合了跳过连接和池索引策略,以加快网络推理。ICNet使用具有多分辨率分支的图像级联网络,以获得高分辨率输入图像的快速和良好精度。DFANet重用高级特征并组合不同阶段的输出以增强多尺度特征表示。
上述方法在实时推理速度上获得了良好的性能,但它们未能考虑低层次空间细节对语义分割任务的积极影响。
双边分割网络被引入,以利用低层次细节和高层次语义来实现高精度和高效率。这些方法采用与BiSeNetV2类似的结构。然而,在最初的下采样阶段,两个分支机构的划分不利于信息的相互作用因此,Faster BiSeNet结合了一个共享的浅层网络来编码细节,而语义仍然可以通过深层的低分辨率特征有效学习。直观地说,我们提出的方法实现了浅层特征共享,以便于信息交换并减少语义分支的初始下采样阶段。
a)BiSeNetV2 b)Faster BiSeNet ——蓝色:空间分支,绿色:语义分支
Sx表示空间和语义分支下采样的第x阶段。立方体中的数字表示特征图大小与原始输入分辨率的比率。
双边网络中,在语义分支上添加一系列辅助分割预测头可以促进最终预测结果的优化。空间分支可以假设为形状流。添加辅助边缘损失可以优化空间分支的门控输出,可以增强低层细节信息,并促进对边界和小对象的预测。
实时高性能语义分割方法由四个部分组成:特征共享层(FSL)、双路径编码器网络(TPEN)、门控引导聚合层(GGAL)和增强训练网络(BTN)

![]() ,
,![]() 分别表示逐元素乘法和逐元素加法。
分别表示逐元素乘法和逐元素加法。
![]() 和
和![]() 被视为空间分支和语义分支的S形输出。Up×4表示四次上采样操作,σ表示S形函数
被视为空间分支和语义分支的S形输出。Up×4表示四次上采样操作,σ表示S形函数
将输入图像发送到空间分支以在FSL中生成浅空间特征。然后通过简单的1×1卷积将特征转化为浅层语义特征。接下来,原始生成的空间特征被直接用作空间分支的输出,而转换后的浅层语义特征通过TPEN中的语义分支进一步生成高级语义。我们设计中的空间和语义分支的特征图对应于原始输入图像的1/8和1/32进行下采样。之后,GGAL有选择地聚合两个分支的特征表示以获得预测结果。
最后,通过简单的双线性插值将预测结果上采样到原始图像的大小。采用BTN来加强网络的训练。
与负责底层细节的空间分支需要宽通道和浅层不同,语义分支应该捕获高层语义。深度卷积和反向残差块可以帮助语义分支实现快速下采样,以扩大感受野并有效提高特征表示的水平。在语义分支中,我们利用集合和扩展层以及上下文嵌入块来提取高级语义

(a) 是上下文嵌入块。(b) (c)为集合和扩展层。符号:Conv表示普通卷积。C代表channel
DWConv表示深度卷积。BN表示批次归一化。ReLU激活函数。
Context Embedding(上下文嵌入块)使用剩余连接有效嵌入更好的空间信息和更好的语义信息。
将当前层的结果和上一层的结果相加,以保留前一层的计算结果。也可以按照比例系数进行加权、或可学习的权重等,可以衍生出一系列剩余连接的变体。
集合和扩展层综合利用了深度可分离卷积和倒置残差块
用更少的计算量和更少的参数,从相同shape的输入得到相同shape的输出,且计算过程中保证了空间信息的捕捉和跨channel信息的融合。
深度可分离就是逐个channel进行卷积,卷积之后不求和。然后再用一个1*1的常规卷积实现channel信息的融合。
倒置残差块是对低维卷积进行增维最后再进行降维。这种倒置的设计使得占用的存储空间更小,而且效果也会稍微变好一些。
3×3卷积收集局部特征表示。然后,3×3深度卷积分别学习每个信道中位置之间的空间相关性,并将当前信道扩展到更高的信道。最后,1×1逐点卷积学习线性组合通道,并将输出投影到低维空间。(c)图中步幅为2,我们首先调整特征图的空间大小。然后我们选择两个深度卷积和一个1×1。
与BiSeNetV2相比,我们避免了快捷方式中特征大小的调整,从而降低了模型参数和计算成本。
门控机制的使用可以有效地控制有用信息的增强和无用信息的抑制。然后我们利用空间分支的有价值的空间特征来补偿语义分支的缺失细节。
![]()
X表示两个分支的输出特征图
GGAL像素化地测量每个特征向量的有用性并避免冗余操作。

s表示卷积和池化的步幅。Apooling是平均池。上采样表示双线性插值。
进一步促进模型的训练,我们引入了由辅助分割和边缘预测头组成的Booster训练网络。该网络可以更好地改进训练阶段的特征表示。
优点:在推理阶段没有任何计算成本。

将辅助分割头插入到语义分支的不同位置,并在GGAL中的空间分支的门控输出处插入辅助边缘头
实验:
计算量(FLOPs)要看网络执行时间的长短,参数量(Params)要看占用显存的量
在辅助边缘监督中使用了二值交叉熵损失。我们采用标准交叉熵损失来监督分割预测。采用在线硬示例挖掘(OHEM)算法进行训练。
(1条消息) 交叉熵损失和二元交叉熵损失_飞机火车巴雷特的博客-CSDN博客_交叉熵损失
我们注意到分割精度(MIOU)、模型大小(PARAMS)、计算成本(GFLOPS)和实时性能(FPS)。

消融研究
对于TPEN,语义分支与空间分支互相带来改进。
对于FSL,促进了两个分支的信息交换,
对于GGAL,提高分割精度的同时减少了模型冗余
对于BTN,可以有效提高分割精度
正样本:所识别的目标物体。负样本: 一张图片中除目标物体的其他部分。

True和False表示是否预测正确(是否猜对)
Positive和Negative表示样本的类别是正类别还是负类别





通过最后两列的比较可以得出辅助边缘损失的增加,主要是对小型类别和细节精细的类别的改进。即添加辅助边缘监督可以锐化边界周围的预测并提高小对象的准确性。
语义分支主要为具有清晰语义的大型结构提供关键信息,而空间分支输出对于局部细节和边界更有用。清晰边缘的学习使网络关注边界周围的预测,提高了分割精度。

(a)输入RGB图像 (b)空间分支的门图(c):语义分支的门图(d):语义支路的预测分割输出(e):Faster BiSeNet的预测分割输出来(f):Faster BiSeNet的预测边缘输出(g):地面真实标签。
城市景观数据集上的测试:
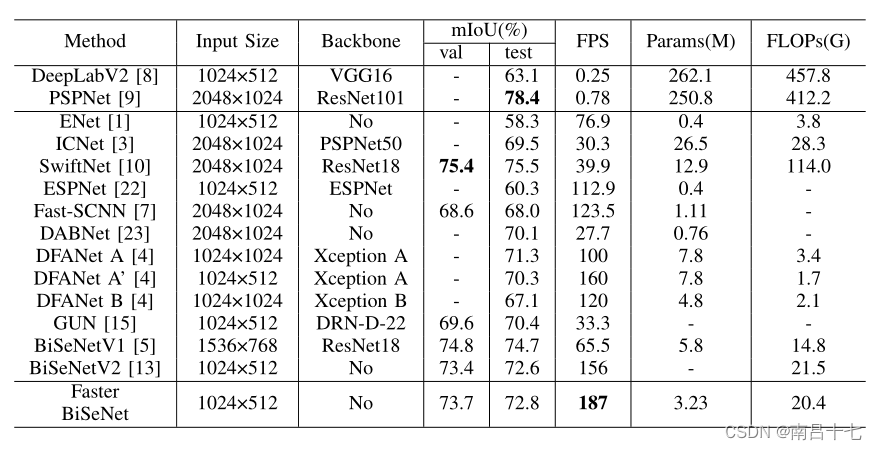
CAMVID数据集上的测试

采用了基于BiSeNetV2的紧凑架构,以增强浅空间和深空间中两个分支的信息融合。共享浅特征可提高运行时效率,添加门控机制有助于精细聚集特征表示,引入辅助边缘损失可进一步增强边界周围的预测。
Faster BiSeNet的亮点:增强低层次细节和高层次语义的融合和使用。充分利用低级细节有利于提高小型类和具有精细细节的类的准确性,这种改进通常是实时语义分割的需要,因为轻量级架构限制了网络提取更丰富特征的能力。
比BiSeNetV2在推理速度和分割精度之间实现了更好的权衡。















 2047
2047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









