








patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat,更节省参数和计算量。加入位置编码信息之后,维度依然是197x768,一维位置编码,其实就是初始化了一个可学习的随机变量,加到了原本的输入上
positional encoding
1-D 位置编码:例如3x3共9个patch,patch编码为1到9
2-D 位置编码:patch编码为11,12,13,21,22,23,31,32,33,即同时考虑X和Y轴的信息,每个轴的编码维度是D/2
实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,甚至不使用位置编码,模型的性能损失也没有特别大。原因可能是ViT是作用在image patch上的,而不是image pixel,对网络来说这些patch之间的相对位置信息很容易理解,所以使用什么方式的位置编码影响都不大

1D
1-D绝对位置编码,例如将图片切分后序列长度为9,宽度为768,则初始输入维度为9 x 768,经过Linear Projection之后序列维度依然为9 x 768,加上特殊字符后整个序列维度是10 x 768,此时在送入到Transformer Encoder之前需要sum上1-D位置编码,位置编码的维度也是10 x 768,这里的1-D绝对位置编码是可以学习的

2D
2-D绝对位置编码考虑到了patches的二维位置信息,即认为每个图像块有横纵两个维度的坐标信息,第一个维度对应一组368-D的位置编码(蓝色),第二个维度对应另一组368-D的位置编码(红色),两个维度的位置编码concat之后维度依然是768,这里的位置编码同样是可以学习的

相对位置编码考虑了不同patch之间的相对位置,其本质是微调Attention矩阵,使它有能力分辨不同位置的patch,相对位置编码把patches本身当作query,把patches之间的绝对位置信息( pq−pk )当作keys,把其余patches本身当作values,做了一次额外的attention(如下图),从而得到一个attention矩阵,然后将这个副attention矩阵加到主attention矩阵中,两个矩阵的维度大小是相同的(都是 sequence_length x sequence_length)所以可以执行sum操作,最后再执行softmax得到最终的attention矩阵
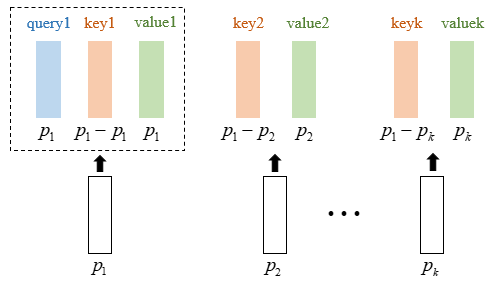














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









