







 本文介绍如何使用HuggingFace库中的Tokenizer进行中文文本的编码与解码操作。通过三步快速上手:访问HuggingFace网站选择预训练模型、安装所需库并加载模型、对中文句子进行编码及解码。
本文介绍如何使用HuggingFace库中的Tokenizer进行中文文本的编码与解码操作。通过三步快速上手:访问HuggingFace网站选择预训练模型、安装所需库并加载模型、对中文句子进行编码及解码。
方法
step1
进入huggingface网站
在搜索栏中搜索chinese【根据自己的需求来,如果数据集是中文这的搜索】
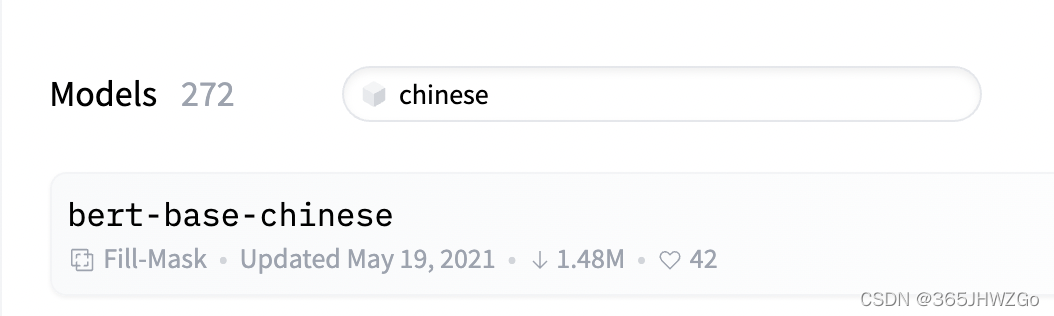
step2
打开第一个bert-base-chinese
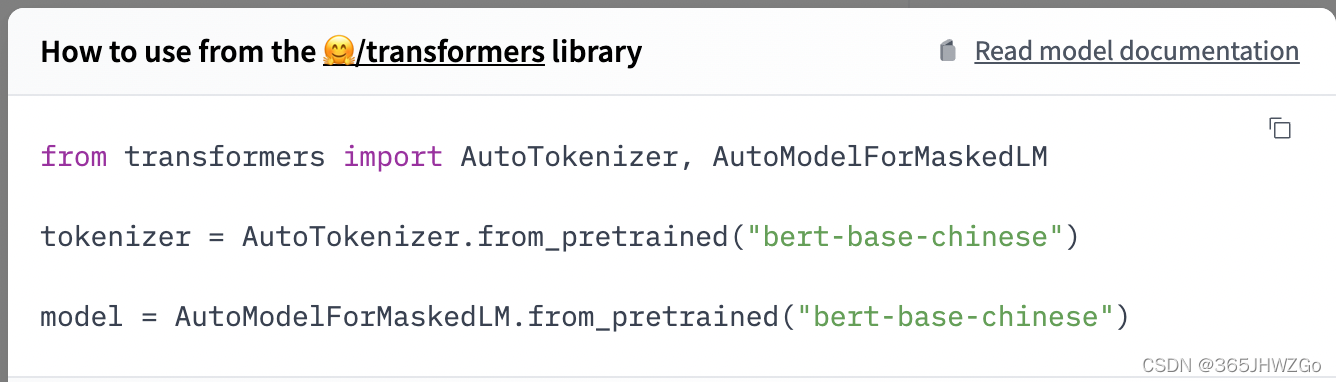
复制下面这段话到vscode里
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
step3
'''
Description: 快速入门
Autor: 365JHWZGo
Date: 2022-01-21 11:54:58
LastEditors: 365JHWZGo
LastEditTime: 2022-01-21 12:13:41
'''
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
# encode
word_embeding = tokenizer('我是中国人,我骄傲!')
print(word_embeding)
'''
{
'input_ids': [101, 2769, 3221, 704, 1744, 782, 8024, 2769, 7734, 1000, 8013, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
'''
# decode
decode_word = tokenizer.decode(word_embeding['input_ids'])
print(decode_word)
# [CLS] 我 是 中 国 人 , 我 骄 傲 ! [SEP]


















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











