







BERT在作文自动评分中的应用:多尺度作文表征的联合学习
1. Introduction
针对预训练语言模型在AES领域效果不好的问题进行分析:
首先,预先训练的模型通常是在句子层面上进行训练,但没有学习到足够的文章知识;
其次,AES训练数据通常非常有限,无法直接微调预先训练的模型,以便学习更好地表示论文。
2.Contribution
- 提出了一种新的作文评分方法,与BERT一起学习多尺度的作文表征,与传统的使用预先训练的语言模型相比,显著改善了结果。
- 该方法在长文本任务中表现出明显的优势,在ASAP任务中获得了几乎所有深度学习模型中最先进的结果。
- 受教师评分心理过程的启发,我们引入了两个新的损失函数,并使用RDrop从域外文章中进行迁移学习,进一步提高了作文评分的性能。
3.Multi-scale Essay Representation 多尺度作文表征
从三个尺度上得到了文章的多尺度表征:token-scale, segment-scale ,document-scale
- token-scale:对所有序列输出使用最大池化的操作获得token-scale文章表示。
- segment-scale:片段特征,通过LSTM获得。
- document-scale:文档尺度表示由BERT模型的[CLS]输出获得。由于[CLS]输出聚合了整个序列表示,它试图从最全局的粒度中提取文章信息。
4.Models

其中左半图利用一个BERT模型来提取文档和词汇级特征,并通过最大池化和一层Dense layer预测作文对应这两个尺度的分数;右半图利用一个BERT模型提取多尺度片段特征,也通过一层Dense layer预测各片段尺度的分数。通过将文档特性分数,词汇特征分数和片段特征分数相加得到最终的文章预测分数。
5.Data sets
实验数据使用的是ASAP数据集,以及CRP数据集,该数据集提供了来自几个时间段的2834个摘录和阅读轻松分数,范围从-3.68到1.72。摘录的平均长度为175个,字幕长度为252个。
ASAP数据集地址:
https://www.kaggle.com/c/asap-aes
6.Result
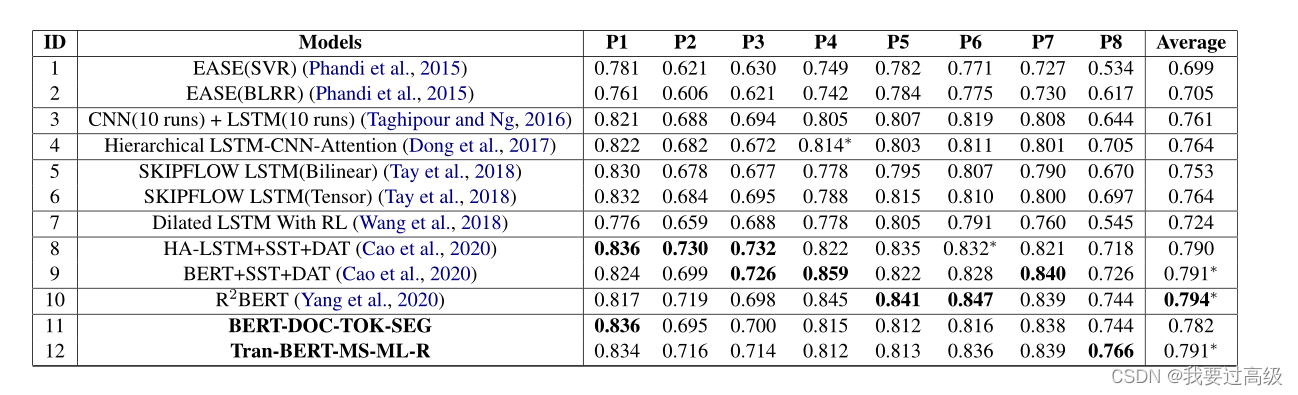
该方法在ASAP数据上 QWK 0.791。提出的多尺度特征表征方法在只使用回归损失函数,且无辅助任务优化的情况下效果超过了基于深度学习的方法如LSTM。
Wang Y , Wang C , Li R , et al. On the Use of BERT for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation[J]. arXiv e-prints, 2022.
论文下载地址https://arxiv.org/abs/2205.03835















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









