







梯度下降
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)常用来解决无约束优化问题,即解决以下问题:

- 其中 L L L为损失函数, θ \theta θ为参数
- 注意:
θ
\theta
θ并不只是一个参数,而是一组参数,假设当
θ
\theta
θ的个数为2时,此时有:
θ = [ θ 1 θ 2 ] \theta=\left[ \begin{matrix} \theta_1 \\ \theta_2 \\ \end{matrix} \right] θ=[θ1θ2]
得到如下的梯度下降过程:
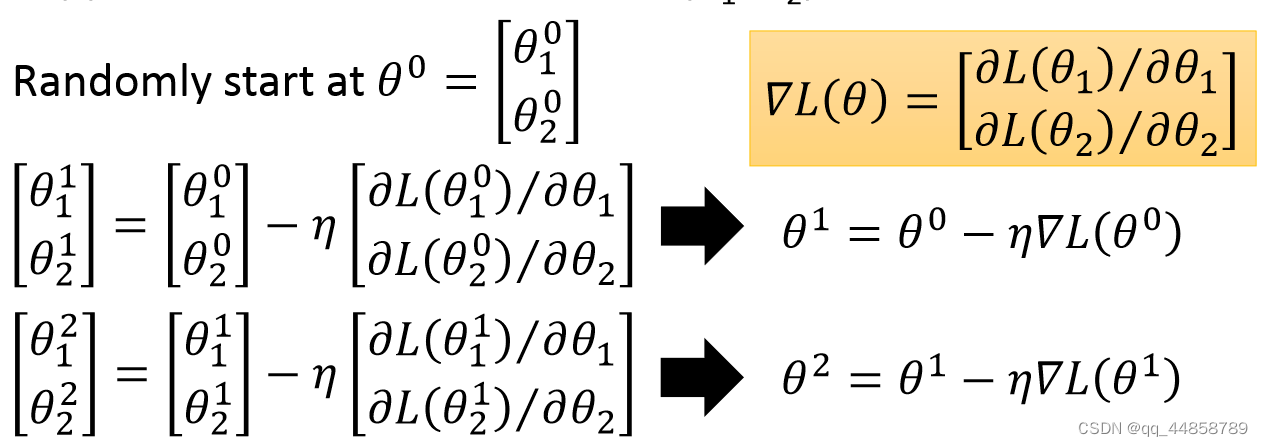 公式中的参数的含义如下:
公式中的参数的含义如下: - θ i \theta^i θi表示第i次迭代后的参数值
- η \eta η表示学习率
- ∂ L ( θ i ) ∂ θ i \frac{\partial L(\theta_i)}{\partial \theta_i} ∂θi∂L(θi) 表示对参数求偏导
- Δ L ( θ i ) \Delta L(\theta^i) ΔL(θi)表示梯度
一、学习率选择
根据上面的公式可以看出:学习率的选择一定程度上影响每次迭代后参数的取值,从而影响损失函数最后的取值。
- 学习率太大,一开始的迭代可能是正常下降的,但是之后可能会突然一直增大,又或者是保持不变,难以再下降;
- 学习率太小,则会导致迭代的速度太慢。
如下图所示:
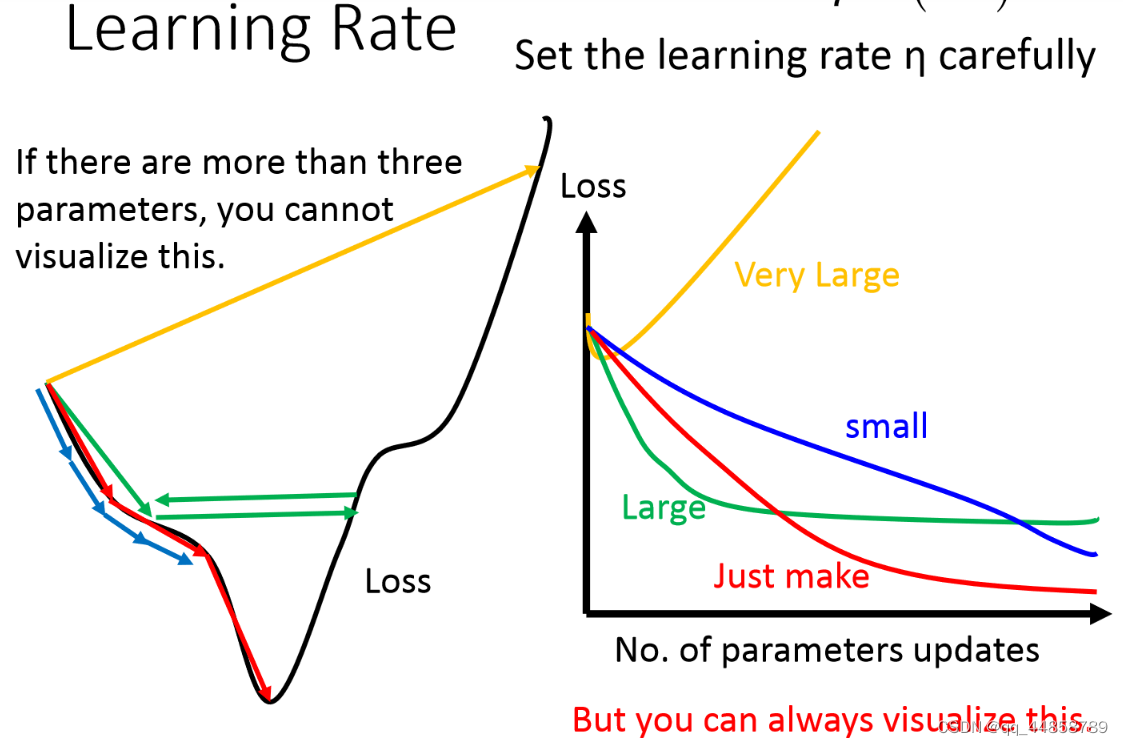 因此要观察学习率适不适合的一个方法就是:将参数改变对损失函数的影响进行可视化
因此要观察学习率适不适合的一个方法就是:将参数改变对损失函数的影响进行可视化
1.1 自适应学习率
一般情况下,学习率从一开始设置就不变了,这样一成不变的学习率会导致损失函数的取值不稳定,因此比较简单的方法就是随着迭代的进行不断通过某些因子来降低学习率,其思想就是:
- 刚开始的取值距离最低点较远,所以采用比较大的学习率
- 随着迭代次数的增加越来越靠近最低点,这时候可以降低学习率
例如可以采用 η t = η t + 1 \eta^t = \frac{\eta}{\sqrt{t+1}} ηt=t+1η(t为迭代次数)来更新学习率
注意:学习率不是 one-size-fits-all,不同的参数应该有不同的学习率
1.2 Adagrad算法
算法的主要思想是:令当前的学习率等于上一次迭代后得到的学习率除以当前迭代次数之前的所有微分之和的均方根
- 普通的学习率计算方法: w t + 1 = w t − η t g t w^t+1=w^t - \eta^tg^t wt+1=wt−ηtgt
- Adagrad算法:
w
t
+
1
=
w
t
−
η
t
σ
t
g
t
w^t+1=w^t - \frac{\eta^t}{\sigma^t}g^t
wt+1=wt−σtηtgt
σ
t
=
1
t
+
1
∑
i
=
0
t
(
g
i
)
2
{\sigma^t} = \sqrt{\frac{1}{t+1}\sum_{i=0}^t(g^i)^2}
σt=t+11i=0∑t(gi)2
化简: 利用 η t = η t + 1 \eta^t = \frac{\eta}{\sqrt{t+1}} ηt=t+1η来表示学习率,化简后有: w t + 1 = w t − η ∑ i = 0 t ( g i ) 2 g t w^t+1 = w^t - \frac{\eta}{\sqrt{\sum_{i=0}^t(g^i)^2}}g^t wt+1=wt−∑i=0t(gi)2ηgt
二、随机梯度下降
随机梯度下降的作用可以使训练的速度更快些
- 普通的梯度下降:
L = ∑ n ( y ^ n − ( b + ∑ w i x i n ) ) 2 L = \sum_n(\hat{y}_n - (b + \sum w_ix_i^n))^2 L=n∑(y^n−(b+∑wixin))2
θ i = θ i − 1 − η Δ L ( θ i − 1 ) \theta^i = \theta^i-1 - \eta\Delta L(\theta^i-1) θi=θi−1−ηΔL(θi−1)
注意:是所有训练例子的损失率的总和 - 更快的随机梯度下降:
L n = ( y ^ n − ( b + ∑ w i x i n ) ) 2 L^n = (\hat{y}_n - (b + \sum w_ix_i^n))^2 Ln=(y^n−(b+∑wixin))2
θ i = θ i − 1 − η Δ L n ( θ i − 1 ) \theta^i = \theta^i-1 - \eta\Delta L^n(\theta^i-1) θi=θi−1−ηΔLn(θi−1)
注意: 随机梯度并不是针对所有的数据进行处理,而是随机的选取一个例子 x n x^n xn,所以如果有20个例子,就一次分别更新这20例子的参数值
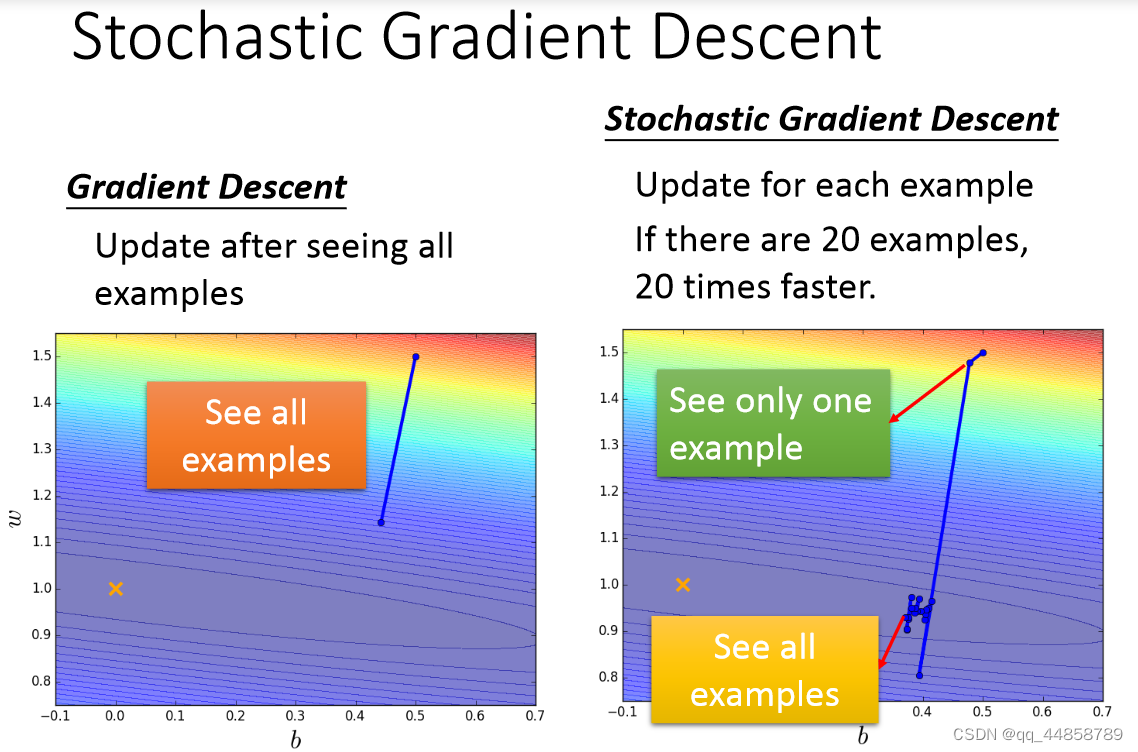
两种方法对比:
- 在Gradient Descent 中,每更新updata一次参数需要loss function计算所有样本的error的平方和 。而SGD是而是这个随机样本点的error平方。
- GD是训练一组数据更新一次参数,SGD是一个example就更新一次参数
结果对比图如下图所示:
三、 特征缩放
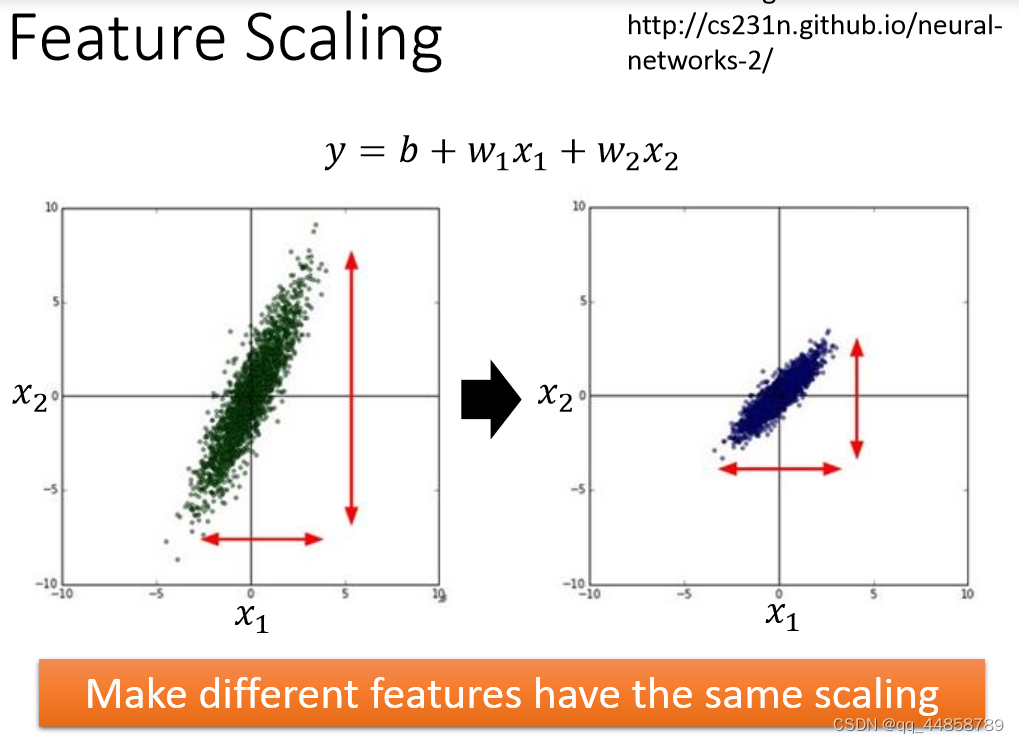
feature scaling的作用就是所有输入的特征数据的范围缩小到一样,避免数据范围相差太大导致范围小的特征丢失,如下图所示:
特征缩放的方法
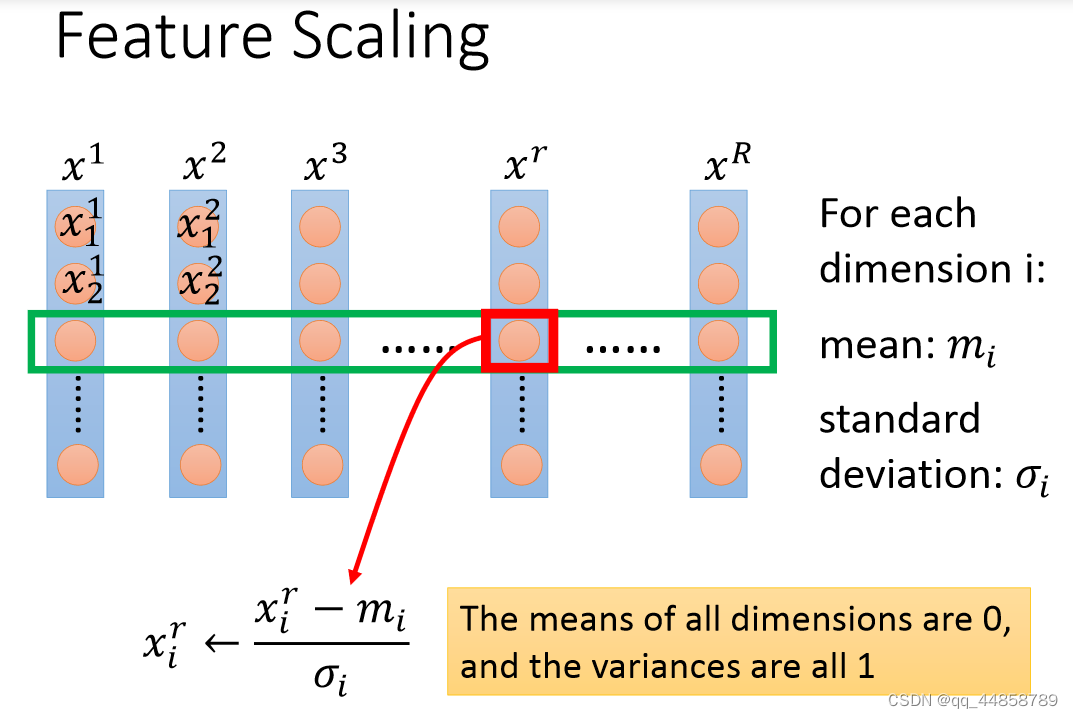 上述图片中每个维度对应一组特征,其特征缩放的方法就是:每组特征中的每个输入都要减去这组特征的平均值再除以标准差
上述图片中每个维度对应一组特征,其特征缩放的方法就是:每组特征中的每个输入都要减去这组特征的平均值再除以标准差
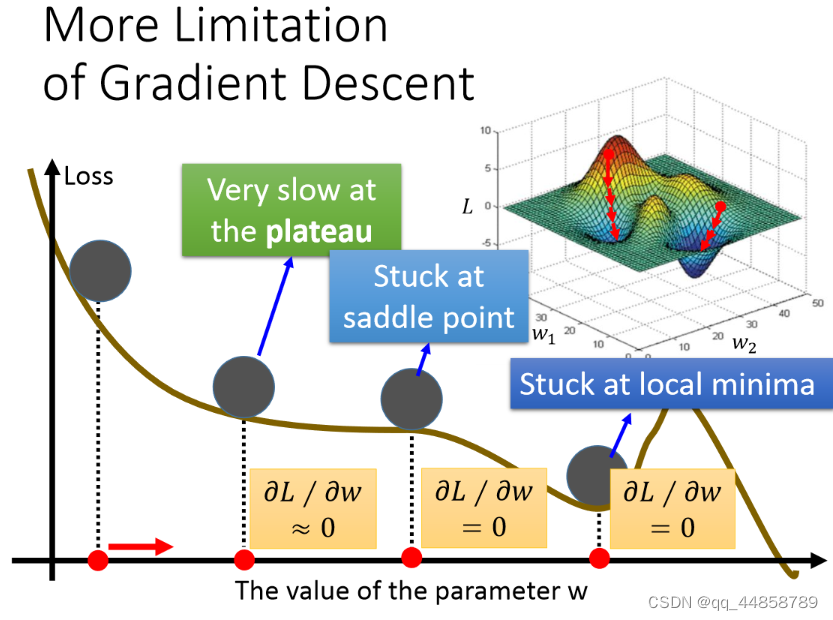
四、梯度下降的局限















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









