






误差从哪里来
Average Error随着模型复杂增加呈指数上升趋势。更复杂的模型并不能给测试集带来更好的效果,而这些Error的主要有两个来源,分别是 bias和 variance
Error = Bias + Variance
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
误差的期望值可以分解为三个部分:样本噪音、模型预测值的方差、预测值相对真实值的偏差
误差的期望值 = 噪音的方差 + 模型预测值的方差 + 预测值相对真实值的偏差的平方
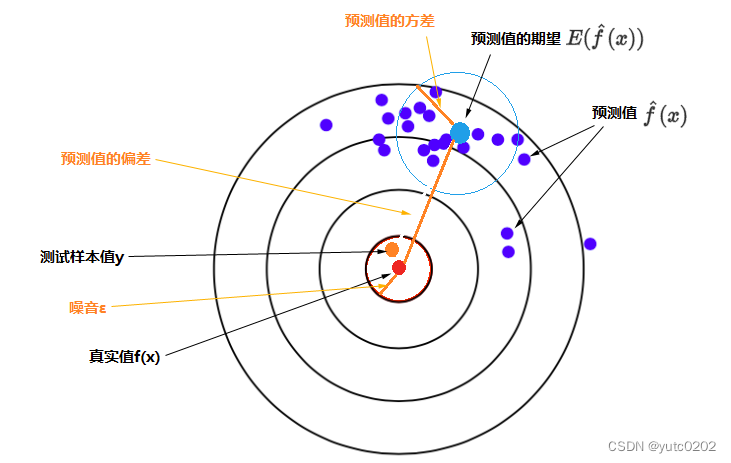
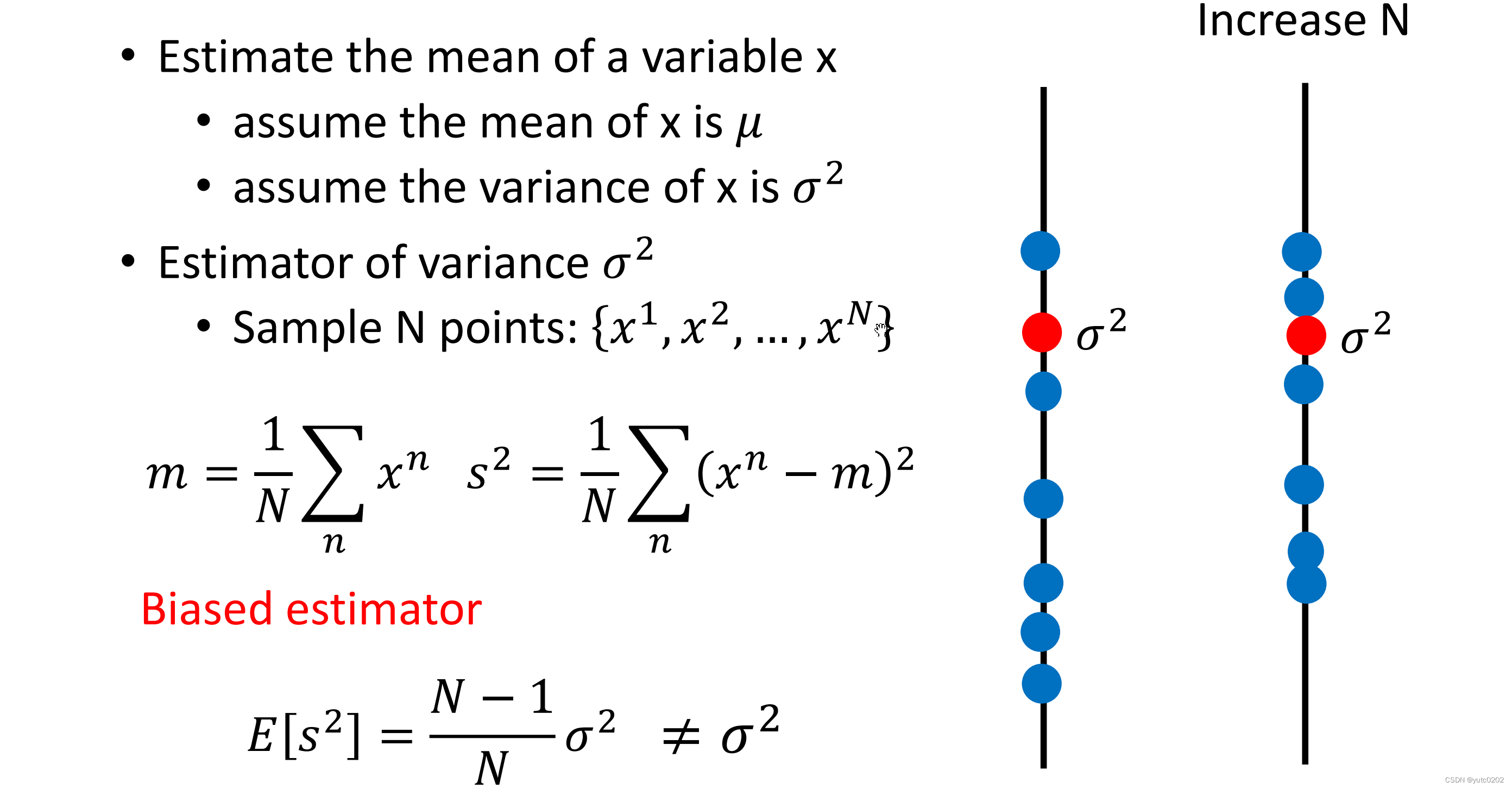
估测变量x的方差
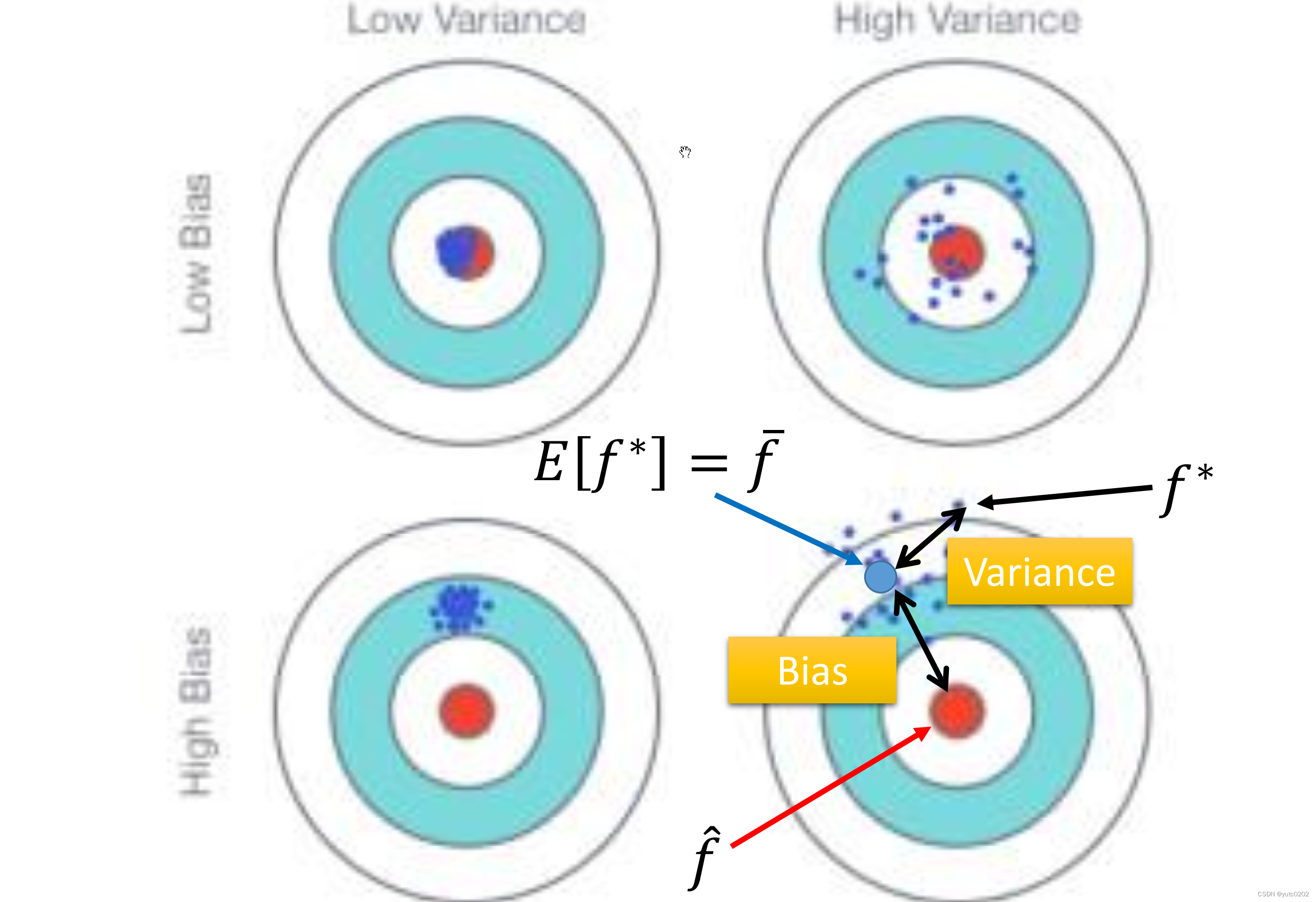
用同一个model,在不同的训练集中找到的 f* 就是不一样的
这就像在靶心上射击,进行了很多组(一组多次)。现在需要知道它的散布是怎样的,将100个宇宙中的model画出来
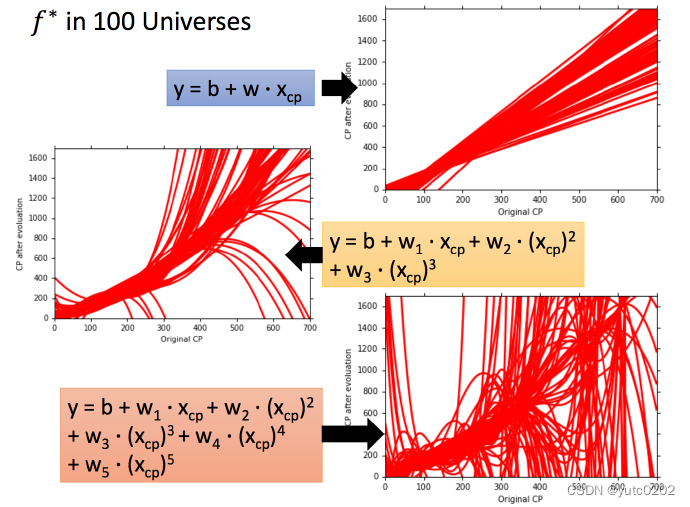
模型判断
偏差大-欠拟合:
如果模型没有很好的训练集,就是偏差过大,也就是欠拟合
方差大-过拟合:
如果模型没有很好的训练集,即再训练集上得到很小的错误,但在测试集上得到大的错误,这意味着模型可能是方差比较大,就是过拟合。
对于欠拟合和过拟合,是用不同的方式来处理的
模型选择
偏差和方差之间就需要一个权衡
想选择的模型,可以平衡偏差和方差产生的错误,使得总错误最小
交叉验证
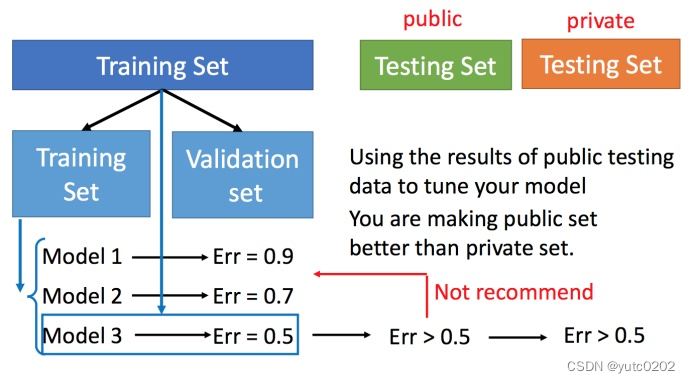
N-折交叉验证
将训练集分成N份,比如分成3份。
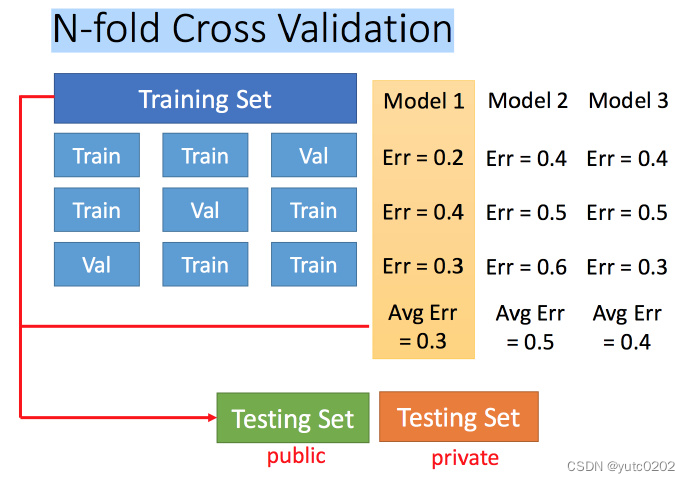
比如在三份中训练结果Average错误是模型1最好,再用全部训练集训练模型1。
什么是梯度下降法?
Review: 梯度下降法
在回归问题的第三步中,需要解决下面的最优化问题:
θ ∗ = a r g θ m i n L ( θ ) θ^∗= arg_θ minL(θ) θ∗=argθminL(θ)
-
LL:lossfunction(损失函数)
-
θ :parameters(参数)
这里的parameters是复数,即θ 指代一堆参数, w 和 b 。
我们要找一组参数θ ,让损失函数越小越好,这个问题可以用梯度下降法解决:
假设θ 有里面有两个参数
θ
1
θ_1
θ1,
θ
2
θ_2
θ2
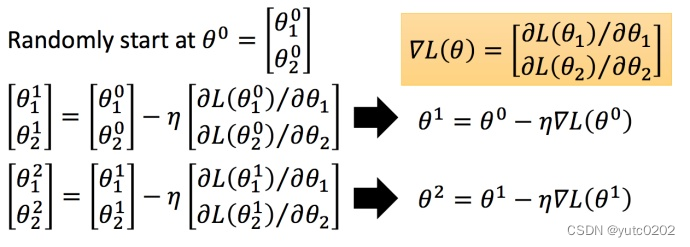
η 叫做Learning rates(学习速率)
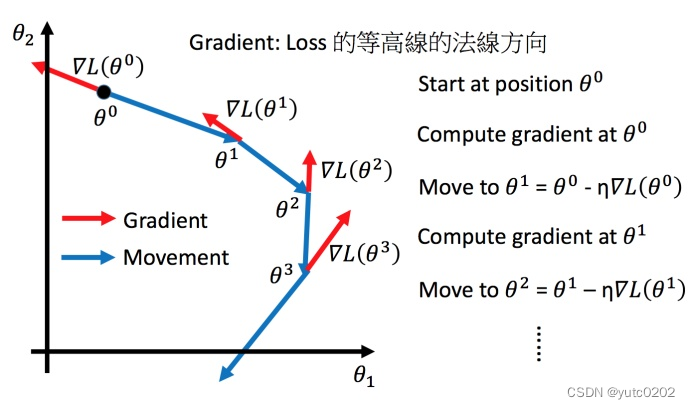
Tip1:调整学习速率
小心翼翼地调整学习率
自适应学习率
举一个简单的思想:随着次数的增加,通过一些因子来减少学习率
- 通常刚开始,初始点会距离最低点比较远,所以使用大一点的学习率
- update好几次参数之后呢,比较靠近最低点了,此时减少学习率
-
η
t
=
η
t
t
+
1
\eta^t =\frac{\eta^t}{\sqrt{t+1}}
ηt=t+1ηt ,t 是次数。随着次数的增加,
η
t
\eta^t
ηt减小
- 学习率不能是一个值通用所有特征,不同的参数需要不同的学习率
Adagrad 算法
Adagrad 是什么?
每个参数的学习率都把它除上之前微分的均方根。解释:
普通的梯度下降为:
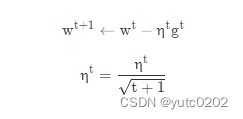
w 是一个参数
Adagrad 可以做的更好:
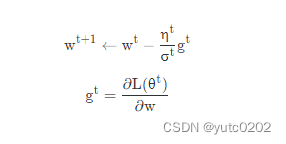
σ
t
σ^t
σt:之前参数的所有微分的均方根,对于每个参数都是不一样的。
Adagrad举例
下图是一个参数的更新过程
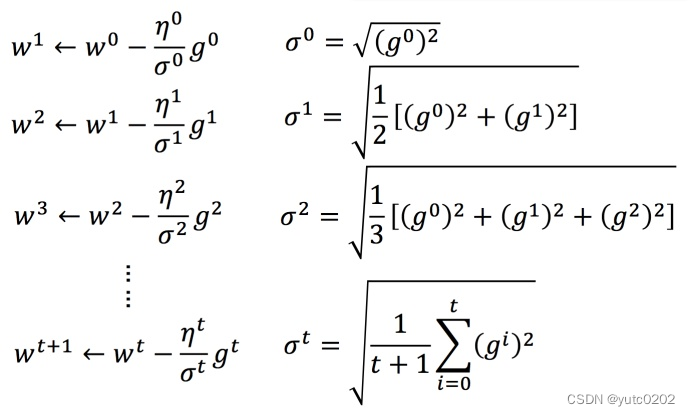
梯度下降的限制
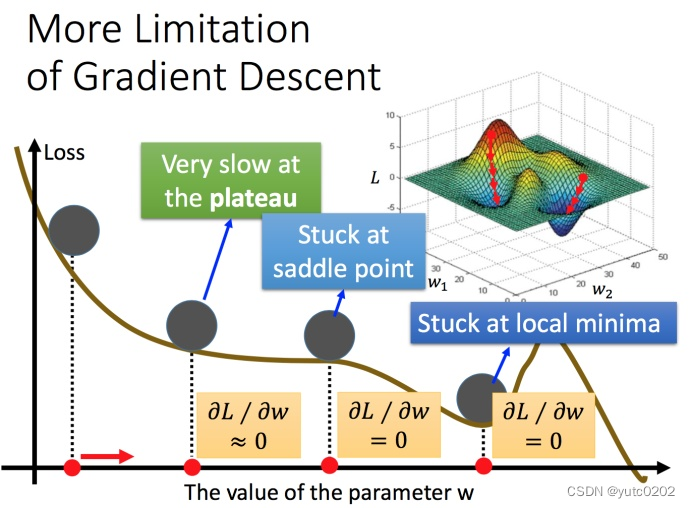
容易陷入局部极值
还有可能卡在不是极值,但微分值是0的地方
还有可能实际中只是当微分值小于某一个数值就停下来了,但这里只是比较平缓,并不是极值点















 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









