






目录
2)随机梯度下降 Stochastic Gradient Descent
一、误差从哪里来?如何改善模型
训练中的误差主要来自 bias 和 variance。
bias 相当于射箭的时候射出的箭离中心的距离,主要是在所有的f*中找平均值;
variance相当于射出的箭的离散程度,分布的越集中,variance越小。
具体看下面这张图:红色区域表示中心区域,即目标,蓝色点表示射出的箭。
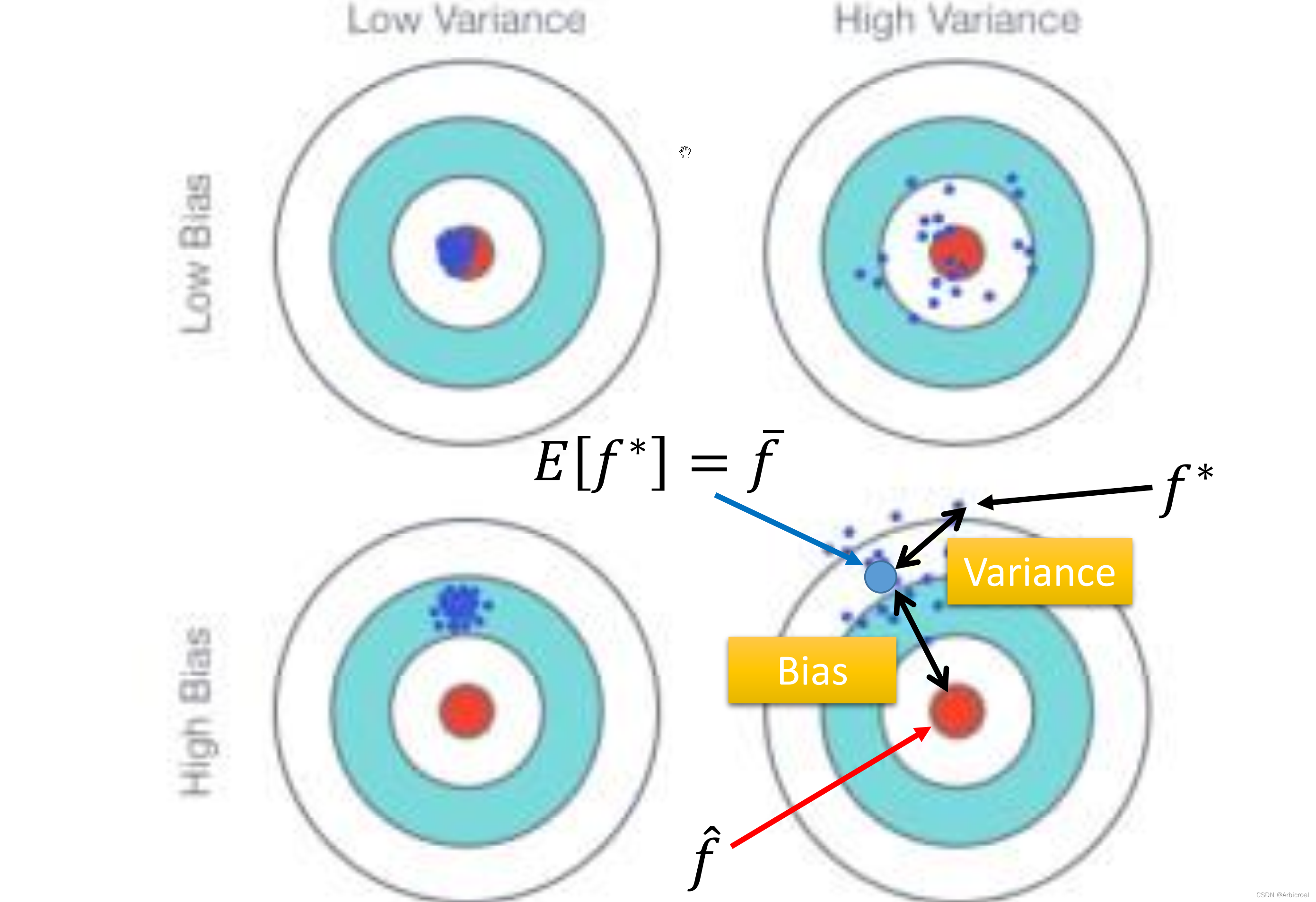
small bias:离
很近,离靶心很近;
large bias:离
很远,离靶心很远;
small variance:f*分布的很集中;
large variance:f*分布的比较分散。
1、减少误差error
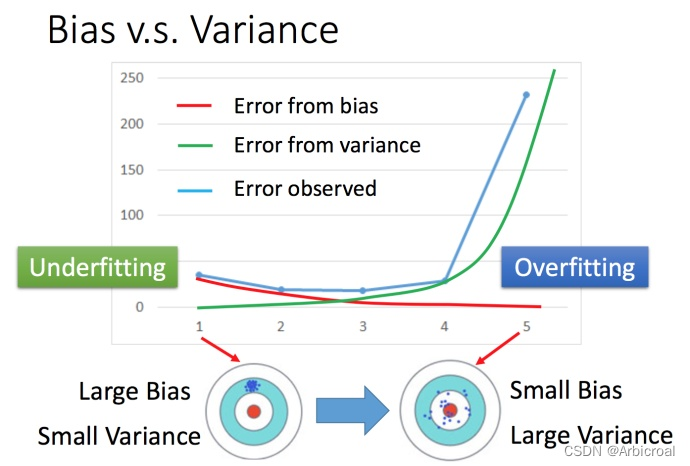
1)方差bias
当error依靠bias过多就是欠拟合,出现欠拟合的时候就要通过以下两种方法进行修改:
1.添加更多的特征features
出现欠拟合可能是因为数据不够多,这时候就要扩大样本量,或者对样本做旋转等操作来使样本数量变大;
2.需要把模型设计的更复杂
此时应该重新设计模型。因为之前的函数集里面可能根本没有包含f*。可以:
将更多的函数加进去,比如考虑高度重量,或者HP值等等。 或者考虑更多次幂、更复杂的模型。 如果此时强行再收集更多的data去训练,这是没有什么帮助的,因为设计的函数集本身就不好,再找更多的训练集也不会更好。
2)偏差variance
当error依靠variance过多就是过拟合,出现过拟合的时候就要通过以下两种方法进行修改:
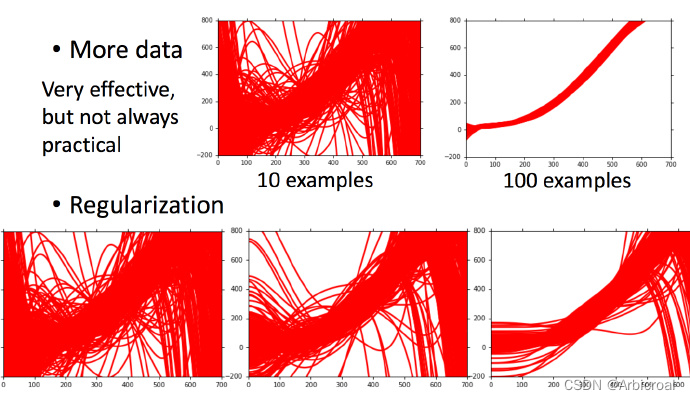
1. 更多的数据 more data
可以对数据进行不同角度的处理,如旋转不同的角度,翻转等,当有10个样本和100个样本的曲线是不一样的;
2. 正则化 Regression
使用正则化可以使曲线变得更平滑,没有加如正则化线是杂乱无章的,加入正则化之后会变得更加平滑。
2、模型的选择
1)交叉验证
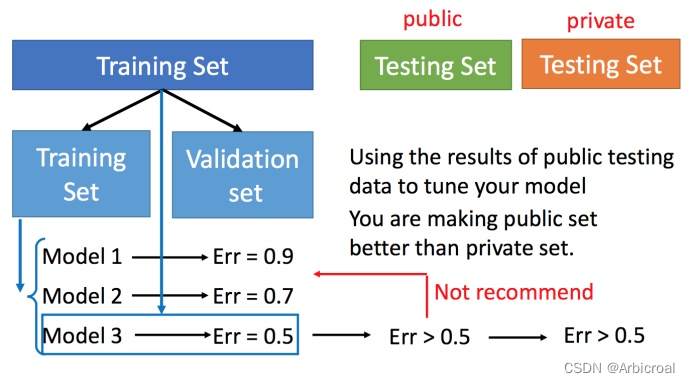
在要选择模型的时候,可以将样本分为训练集Training Set、验证集Validation set、测试集Testing set。
Testing set又有公开的public和不公开的private。可以先在Training Set上训练不同的model,再在验证集Validation set上验证Error,通过Error来确定使用哪个model更好?由图可知,model3的结果更好,所以再用全部的训练集训练model3,然后再用public的测试集进行测试,此时一般得到的错误都是大一些的。不过此时会比较想再回去调一下参数,调整模型,让在public的测试集上更好,但不太推荐这样。
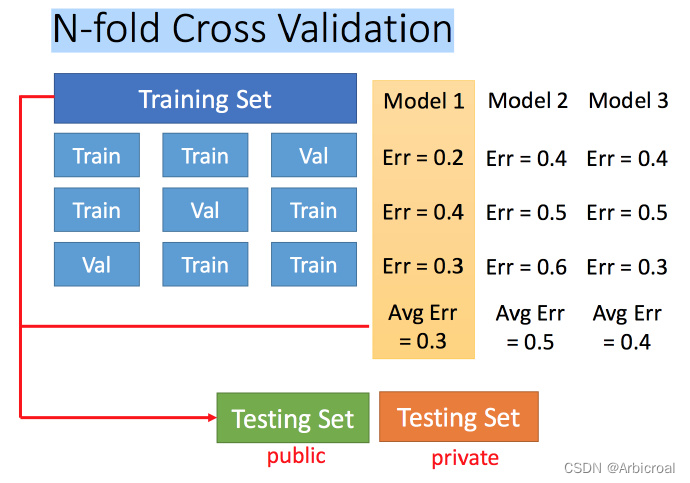
2)K-折交叉验证
K-折交叉验证是将Training set分成N份,比如下图的3份。3份中再分2份训练集Training Set和验证集Validation set,每个model分别训练和验证,再对每个model求平均误差,根据平均误差确定model,下图三份中训练结果Average错误中模型1最好,再用全部训练集训练model1。
二、梯度下降 Gradient descent
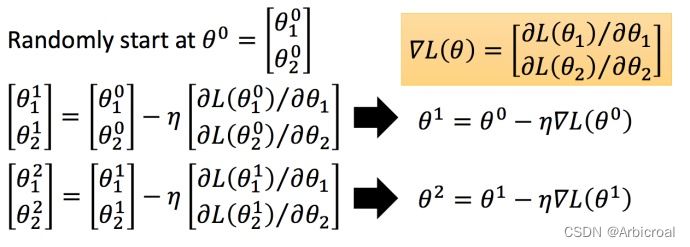
1、什么是梯度下降?
随机选择一个初始点,有两个特征,朝最陡的下坡方向走一步,在梯度下降一步后,或许在哪里停下,因为它正试图沿着最快下降的方向往下走,这是梯度下降的一次迭代,两次迭代或许会到达那里,或者三次等,希望收敛到全局最优解,或接近全局最优解。下图就是更新公式,每走一步都会更新。为Learning rates学习率。
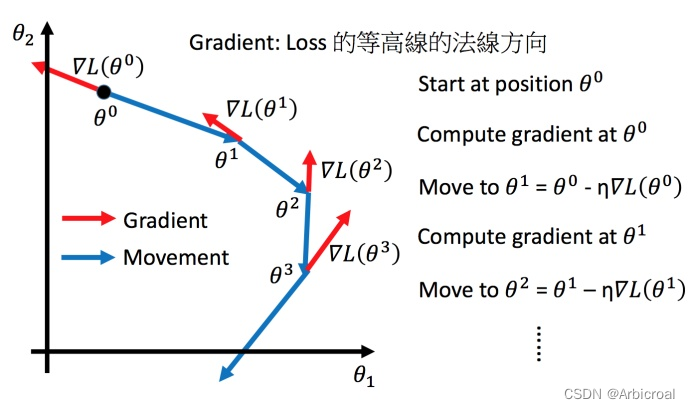
2、使用梯度下降的局限性
当模型中参数过多(超过3个)时,使用梯度下降不能可视化Loss。
下图是将梯度下降法的计算过程进行可视化。
3、Tips
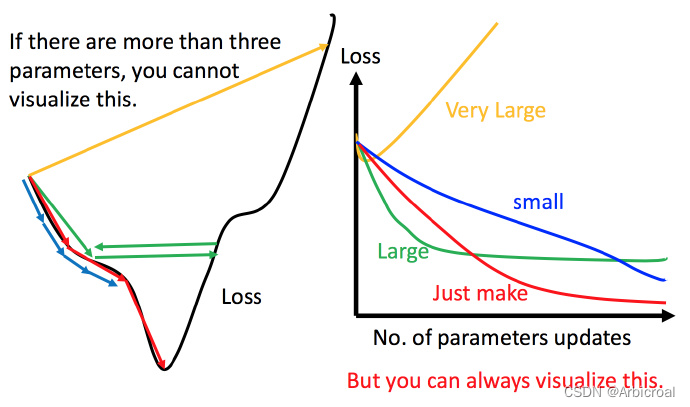
1)调整学习率
下图左边黑色为损失函数的曲线,假设从左边最高点开始,如果学习率调整的刚刚好,比如红色的线,就能顺利找到最低点。如果学习率调整的太小,比如蓝色的线,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。如果 学习率调整的有点大,比如绿色的线,就会在上面震荡,走不下去,永远无法到达最低点。还有可能非常大,比如黄色的线,直接就飞出去了,更新参数的时候只会发现损失函数越更新越大。
虽然这样的可视化可以很直观观察,但可视化也只是能在参数是一维或者二维的时候进行,更高维的情况已经无法可视化了。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
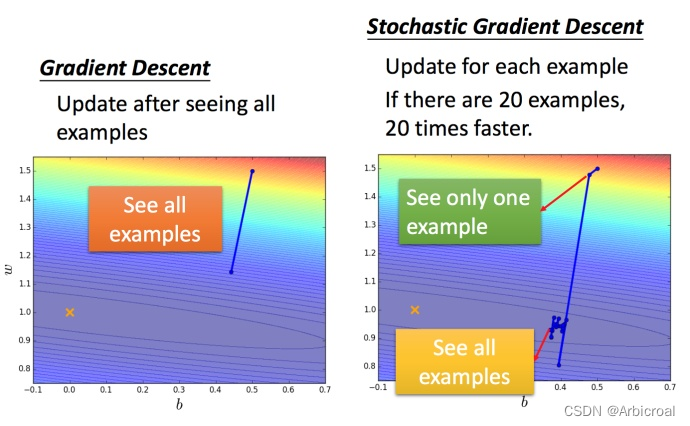
2)随机梯度下降 Stochastic Gradient Descent
随机梯度下降会比梯度下降速度更快,虽然梯度下降一定朝着正确的方向进行,但是使用的是全部的样本,速度很慢,随机梯度下降是从样本中随机挑选一个样本,更新速度非常快。下图就是使用梯度下降和随机梯度下降的对比,当梯度下降更新1次,随机梯度下降可能就更新了20次。
3)特征缩放 Feature scaling
1>原因
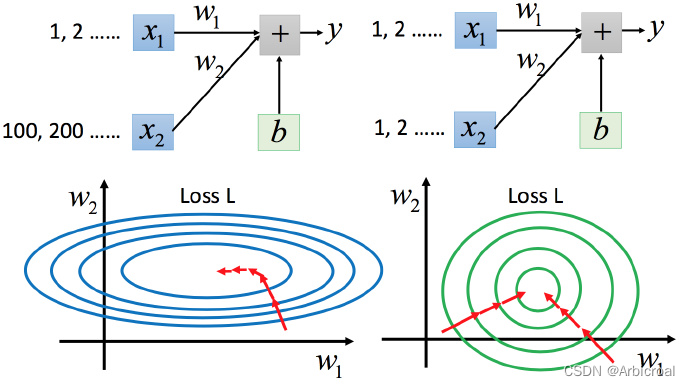
当有多个特征的时候,不同的 w 会对 y 产生的变化影响不一样,对损失函数的影响也不一样。
比如下图左边是 的scale比
要小很多,所以当
和
做同样的变化时,
对 y 的变化影响是比较小的,
对 y的变化影响是比较大的。
坐标系中是两个参数的error surface(现在考虑左边蓝色),因为 对 y的变化影响比较小,所以
对损失函数的影响比较小,
对损失函数有比较小的微分,所以
方向上是比较平滑的。同理
对 y 的影响比较大,所以
对损失函数的影响比较大,所以在
方向有比较尖的峡谷。
上图右边是两个参数scaling比较接近,右边的绿色图就比较接近圆形。
对于左边的情况,上面讲过这种狭长的情形不过不用Adagrad的话是比较难处理的,两个方向上需要不同的学习率,同一组学习率会搞不定它。而右边情形更新参数就会变得比较容易。左边的梯度下降并不是向着最低点方向走的,而是顺着等高线切线法线方向走的。但绿色就可以向着圆心(最低点)走,这样做参数更新也是比较有效率。
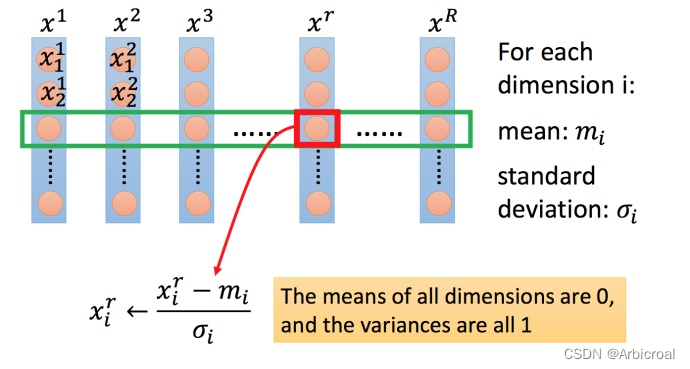
2>方法
对每一维的 i(绿色框),都计算平均数 ,记为,再计算标准差,记作
,
然后用第 r 个例子中的第 i 个输入,减去平均数 , 再除以标准差
;得到的结果是所有维数都是0,方差都是1。















 2676
2676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









