








任务形式
本文任务:事件抽取。给定一段文本,事件抽取模型需要针对特定的事件类型抽取触发词(event triggers),以及该事件中所包含的各类论元角色(argument role)。
如下图例子所示:
- 输入文本:The man returned to Los Angeles from Mexico following his capture Tuesday by bounty hunters. (这名男子周二被赏金猎人抓获后,从墨西哥返回洛杉矶。)
- 事件1:Transport。该事件由“returned”触发,该事件相关的角色包括Artifact “the man”、Destination “Los Angeles”、Origin “Mexico”。
- 事件2:Arrest-Jail。该事件由“capture”触发,该事件相关的角色包括Person “the man”、Time “Tuesday”、Agent “bounty hunters”。

简介
主要内容:
本文以序列生成的形式来进行事件抽取任务。
尽管当前有将事件抽取任务转换为序列生成任务的趋势,这些基于生成的方法面临2个挑战:
- 使用的prompt不一定最优(suboptimal prompt)
过去的研究使用手工设计的prompt来表示各个事件类型,无法对其进行训练调整,十分影响模型的表现。 - 使用静态的事件类型信息(static event type information)
现有的基于生成的事件抽取模型在运行时,只考虑当前抽取的事件类型,忽略了与其他可能事件类型之间的联系。
本文将事件抽取任务看作基于模板的条件生成任务(template-based conditional generation),使用融合了上下文及特定事件类型信息的动态前缀,以解决上述2个问题。
该方法不仅在几个事件抽取数据集上取得了SOTA的表现,也可以方便高效地拓展到新类型事件的抽取中。
Related Work:
- 基于手工prompt的抽取模型示例
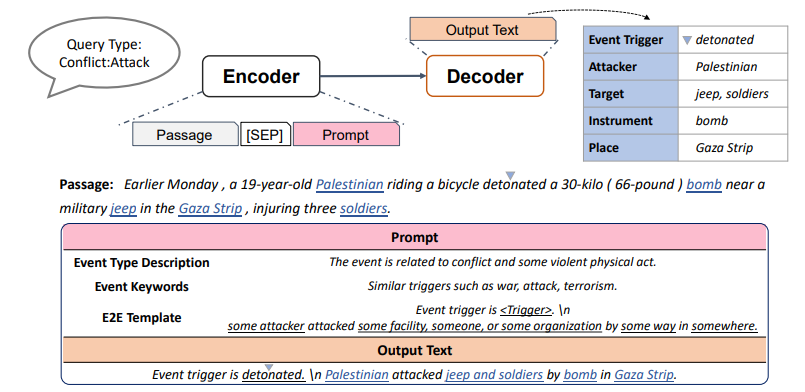
下图来自论文Document-Level Event Argument Extraction by Conditional Generation,其prompt定义了输出的形式,并帮助模型解码。

下图来自论文DEGREE: A Data-Efficient Generation-Based Event Extraction Model,其prompt包括事件类型的定义、一些关键词、decoder的输出形式。将prompt拼接到输入passage的后面送入encoder,可以给模型提供提示信息,以及帮助模型进行更好的解码。
Generative Template-based Method
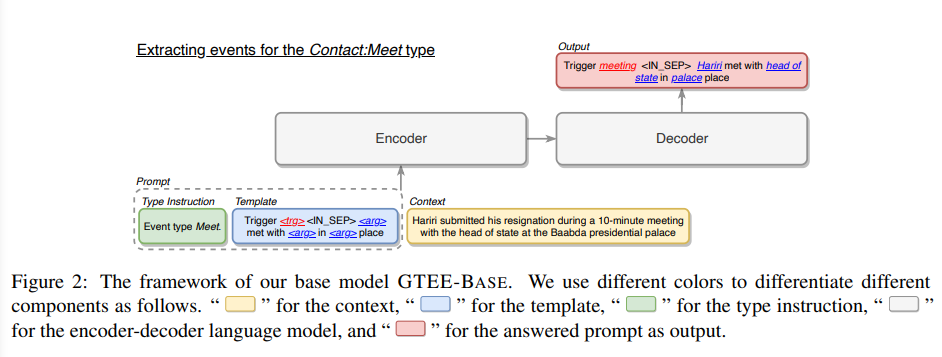
本文使用的基模型GTEE-Base如Figure 2所示,该模型拼接事件类型对应的手工prompt
P
e
i
P_{e_{i}}
Pei和上下文
C
C
C作为输入,并根据其中所含的事件构建句子从Decoder输出。
GTEE-Base使用静态prompt,其prompt包括Type Instruction和Template两部分,分别以文本的形式描述了待抽取的事件类型、以模板的形式指定了Decoder对于事件的输出格式。
当一个事件中有多个argument充当同一角色的时候,需要对argument进行排序以构建Ground Truth的目标句子;同理,当一个句子包含多个事件的时候,需要对事件按照trigger进行排序。

Irrelevant Event Types
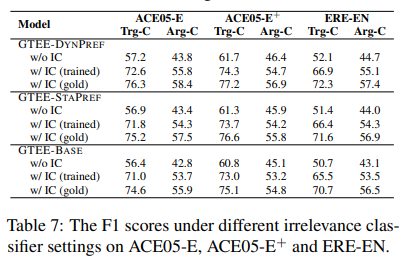
在ACE 2005数据集和ERE数据集中,分别有80.28%和71.02%的句子不包含任何事件类型,然而,作者发现,GTEE-Base模型倾向于对这种句子也进行事件的生成。因此,作者利用BERT+MLP,训练了一个不相关分类器 IC,辅助判断当前句子是否含相关事件,再利用生成模型进行生成。
Dynamic Prefix-Tuning
本文提出基于task-specific前缀及context-specific前缀的动态prefix-tuning模型——GTEE-DynPref。
Type-Specific STATIC PREFIX
受prefix-tuning的启发,作者在引入GTEE-DynPref之前,首先介绍了基于固定的、连续可调前缀的StaPref方法。该方法针对每种事件类型,在Encoder端和Decoder端分别拼接一对长度为
L
L
L的可调向量
s
p
,
s
p
′
{sp, sp'}
sp,sp′作为prompt。
这种方法所学到的prompt只与某一种特定的事件有关,忽略了不同事件类型之间的交互。


Context-Specific DYNAMIC PREFIX
为了捕捉不同事件类型之间的关联,本文提出GTEE-DynPref方法,在构建prompt时候考虑上下文特定的信息,以及所有的事件类型。
使用
d
p
c
dp_{c}
dpc来表示Context-specific Dynamic Prefix,该前缀的长度也为
L
L
L。
前缀
d
p
c
dp_{c}
dpc的每个位置
d
p
c
t
dp^t_{c}
dpct的值由各个事件类型
e
i
e_{i}
ei的prompt对应位置上的向量
s
p
e
i
t
sp^t_{e_{i}}
speit与上下文进行交互所得到。具体地说,作者首先通过BERT编码得到上下文的表示Context Vector,然后经过多头注意力机制加权各个事件类型所对应的prompt在位置
t
t
t上的表示,作为最终使用的prompt在该位置上的表示。
这样所得到的prompt含有各个类及上下文的信息,可以更好地帮助解码的进行。


用BART-large+BERT-large运算成本略大。。。
拿上下文自己prompt自己吗。。。
或许这里的prompt就相当于把上下文中某些部分强调了一下,经过这种强调后所得到的中间结果帮助更容易地得到最终结果。。。
训练过程
注意到本文所使用的方法需要用到BART-Large + BERT-Large,显存要求比较高,因此留意了一下训练过程。
LM的参数记作
ϕ
\phi
ϕ,其余引入的参数,如prompt embedding以及用于不相关分类的BERT模型的参数记作
θ
\theta
θ,从作者的先导实验来看,他们需要不同的训练参数。因此,作者采用了3步的训练方法:
- 使用GTEE-Base训练 ϕ \phi ϕ
- 固定 ϕ \phi ϕ,mask其他所有的事件类型对应的prefix,单独用各个事件训练 θ \theta θ
- 去掉mask,固定 ϕ \phi ϕ, 训练 θ \theta θ,捕捉各个事件之间的联系
实验效果
在基于生成的模型中达到了最优,但不及基于分类的模型。

基于生成的模型具有更好的迁移学习能力。

从消融实验可以看出,动态prefix效果好于手工prompt,而增加动态prefix之间的交互之后,模型效果可以得到进一步的提升。

作者还验证了IC的有效性。
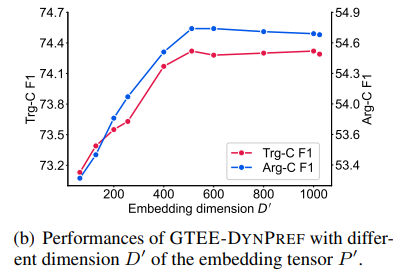
最后是一些参数实验,可以看到prefix需要一定长度和维度。
















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









