






目录
目录
1.SaliencyED:Saliency as Evidence: Event Detection with Trigger Saliency Attribution
2.fewshotED:Few-shot Event Detection: An Empirical Study and a Unified View
4.PA-CRF:Few-Shot Event Detection with Prototypical Amortized Conditional Random Field
6.partialED:Learning with Partial Annotations for Event Detection
7.Event_ APEX:The Art of Prompting: Event Detection based on Type Specific Prompts
8.MetaEvent:Zero- and Few-Shot Event Detection via Prompt-Based Meta Learning
9.(Reasoning_In_EE) OntoED: Low-resource Event Detection with Ontology Embedding
10.fsl-proact:Learning Prototype Representations Across Few-Shot Tasks for Event Detection
1. PAIE:Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction
2.gen-arg:Document-Level Event Argument Extraction by Conditional Generation
3.TSAR:A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction
4.TARA:An AMR-based Link Prediction Approach for Document-level Event Argument Extraction
5.Document-Level Event Argument Extraction via Optimal Transport
6.GRIT: Generative Role-filler Transformers for Document-level Event Entity Extraction
1.CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction
2.DEGREE: A Data-Efficient Generation-Based Event Extraction Model
3.eeqa:Event Extraction by Answering (Almost) Natural Questions
事件检测ED
1.SaliencyED:Saliency as Evidence: Event Detection with Trigger Saliency Attribution
论文来源:ACL2022
论文链接:2022.acl-long.313.pdf (aclanthology.org)
代码链接:https://github.com/ jianliu-ml/SaliencyED
摘要:事件检测(ED)是事件提取的关键子任务之一,旨在识别文本中某些类型的事件触发器。尽管在ED方面取得了重大进展,但现有方法通常采用“一种模型适用于所有类型”的方法,无法区分不同类型的事件,并且经常导致性能严重偏差。了解导致性能偏差的原因对于ED模型的鲁棒性至关重要,但迄今为止对此问题的研究还很少。本研究深入探讨了这个问题,并提出了一个新概念,称为触发显著性属性,可以明确量化事件背后的模式。在此基础上,我们开发了一种新的训练机制,可以区分基于触发器和上下文相关的类型,并在两个基准上实现了有希望的性能。最后,通过突出触发器相关和上下文相关类型之间的许多不同特征,我们的研究可能会促进更多对此问题的研究。
实验:ACE 2005、MAVEN

2.fewshotED:Few-shot Event Detection: An Empirical Study and a Unified View
论文来源:ACL2023
论文链接:arxiv.org/pdf/2305.01901.pdf
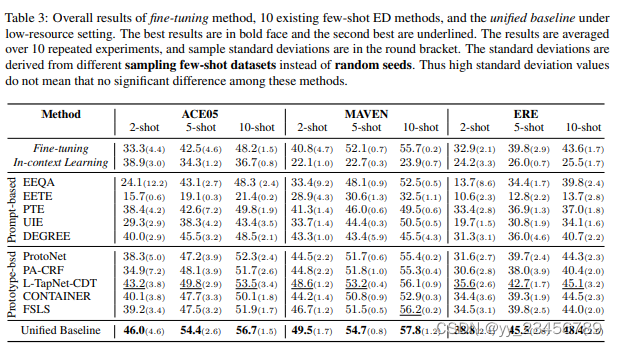
摘要:少数事件检测(Few-shot event detection,ED)的研究已经得到了广泛的关注。然而,由于不同的动机、任务和实验设置等因素的存在,这些研究之间存在明显的差异,这对于理解模型的发展并取得进一步的进展造成了困难。本文对ED模型进行了全面的实证研究,提供了一个统一的视图,并提出了更好的统一基线。为了公平评估,我们在三个数据集上比较了12种代表性方法,大致分为基于提示的方法和基于原型的方法。实验一致表明,在总体性能方面,包括ChatGPT在内的基于提示的方法仍然显著落后于基于原型的方法。为了深入研究它们的卓越性能,我们从几个维度分解了它们的设计要素,并在原型方法的基础上构建了一个统一的框架。在这种统一的视角下,每个原型方法都可以被视为这些设计要素的不同模块的组合。我们进一步结合了所有有益的模块,并提出了一种简单而有效的基线方法,该方法的性能比现有方法高出很多(例如,在低资源设置下,F1得分提高了2.7%)。
实验:ACE05 MAVEN ERE
3.causalFSED:Honey or Poison? Solving the Trigger Curse in Few-shot Event Detection via Causal Intervention
论文来源:ACL2021
代码链接:https://github.com/chen700564/causalFSED
摘要:事件检测长期受到触发诅咒的困扰:过度拟合触发器会损害泛化能力,而欠拟合则会损害检测性能。在少样本情况下,这个问题更加严重。在这篇论文中,我们从因果角度来看待少样本事件检测(FSED)中的触发诅咒问题,并识别和解决了这个问题。通过将FSED建模为结构化因果模型(SCM),我们发现触发器是上下文和结果的混淆变量,这使得先前的FSED方法更容易过拟合触发器。为了解决这个问题,我们提出在训练过程中通过后门调整干预上下文。实验表明,我们的方法显著提高了在ACE05、MAVEN和KBP17数据集上的FSED性能。
实验:ACE05 MAVEN KBP17
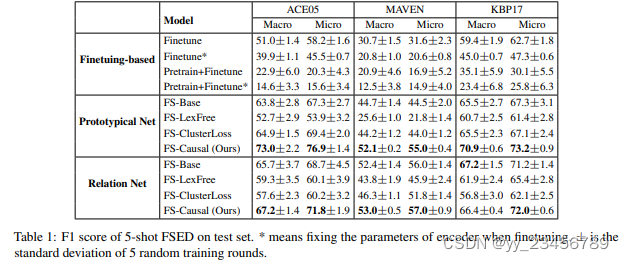
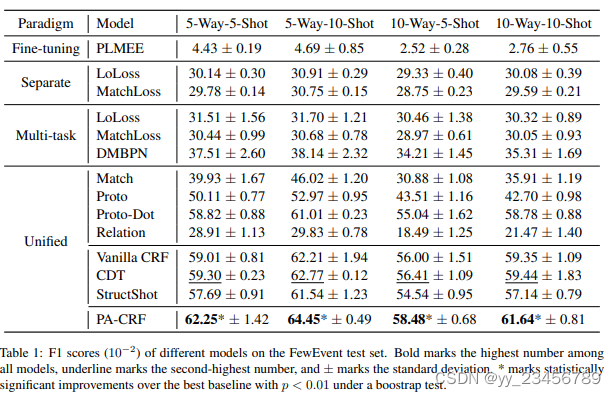
4.PA-CRF:Few-Shot Event Detection with Prototypical Amortized Conditional Random Field
论文来源:ACL2021
论文链接:2012.02353.pdf (arxiv.org)
代码链接:GitHub - congxin95/PA-CRF:“使用原型摊销条件随机场进行少样本事件检测”的代码,ACL 2021 的发现
摘要:事件检测在需要使用少量样本识别新颖事件类型时往往表现不佳。先前的工作试图以识别-分类的方式解决这个问题,但忽略了事件类型之间的触发器差异,从而容易出现误差传播。在这篇论文中,我们提出了一种新的统一模型,将任务转换为具有双部分标记方案的少样本标注问题。为此,我们首先提出了原型渐近条件随机场(PA-CRF)来模拟少样本场景中的标签依赖关系,该模型基于标签原型近似标签之间的转移分数。然后引入高斯分布来建模转移分数,以减轻由于数据不足而导致的不确定性估计。实验结果表明,统一的模型比现有的识别-分类模型效果更好,而我们的PA-CRF在基准数据集FewEvent上进一步实现了最佳结果。
实验:FewEvent
5.HCL-TAT: A Hybrid Contrastive Learning Method for Few-shot Event Detection with Task-Adaptive Threshold
论文来源:EMNLP 2022
论文链接:arxiv.org/pdf/2210.08806.pdf
代码链接:GitHub - CCIIPLab/HCL-TAT
摘要:在监督学习设置下的传统事件检测模型由于缺乏足够的注释,无法转移到新出现的事件类型。一种常用的解决方案是采用识别-分类的方式,首先确定触发器,然后通过少数样本学习范式转换分类任务。然而,由于以下两个原因,这些方法仍然无法达到预期效果:(1)在低资源场景中学习判别性表示的能力不足;(2)由触发器和非触发器的学习表示的重叠导致的触发器误识别。为了解决这些问题,本文提出了一种新的混合对比学习方法,即具有任务自适应阈值(简称为HCL-TAT),该方法利用两视图对比损失(支持-支持和原型-查询)进行判别性表示学习,并设计了一个易于适应的阈值来减轻触发器的误识别。在基准数据集FewEvent上的大量实验表明,我们的方法在实现更好的结果方面优于现有最先进的方法。本文的所有代码和数据将在线公开访问。
实验: FewEvent、ACE2005、 KBP2017

6.partialED:Learning with Partial Annotations for Event Detection
论文来源:ACL2023
论文链接:aclanthology.org/2023.acl-long.30.pdf
代码链接:https://github.com/ jianliu-ml/partialED
摘要:事件检测(ED)旨在在纯文本中发现和分类事件实例。先前的ED方法通常采用监督学习,需要完全标记和高质量的训练数据。然而,在实际应用场景中,我们可能无法获得干净的训练数据,而只有部分标记的数据,这可能会严重阻碍学习过程。在本研究中,我们进行了一项关于使用对比学习进行部分注释的学习的初步研究。我们提出了一种新的触发器定位公式,利用对比学习来区分真实触发器与上下文,显示出处理部分注释噪声的相当鲁棒性。令人印象深刻的是,在一个超过90%的事件未标记的极端情况下,我们的方法实现了超过60%的F1分数。此外,我们对ACE 2005重新进行注释并提供了两个完全注释的子集作为事件检测的无偏基准。我们希望我们的方法和应用数据能够激发未来对该重要但研究不足的问题的研究兴趣。
实验:ACE2005、MAVEN
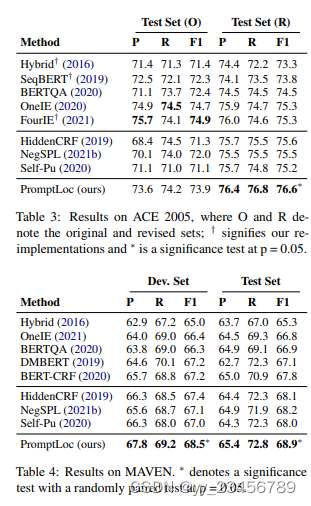
7.Event_ APEX:The Art of Prompting: Event Detection based on Type Specific Prompts
论文来源:ACL2023
论文链接:2023.acl-short.111.pdf (aclanthology.org)
代码链接:https://github.com/VT-NLP/Event_ APEX(未上传)
摘要:我们比较了各种形式的提示以表示事件类型,并开发了一个统一的框架来纳入监督、少样本和零样本事件检测的事件类型特定提示。实验结果表明,明确且全面的事件类型提示可以显著提高事件检测的性能,特别是在标注数据稀缺(少样本事件检测)或不可用(零样本事件检测)的情况下。通过利用事件类型的语义,我们的统一框架在F-score上比先前最先进的基线提高了24.3%。
实验:ACE05-E+ ERE-EN MAVEN
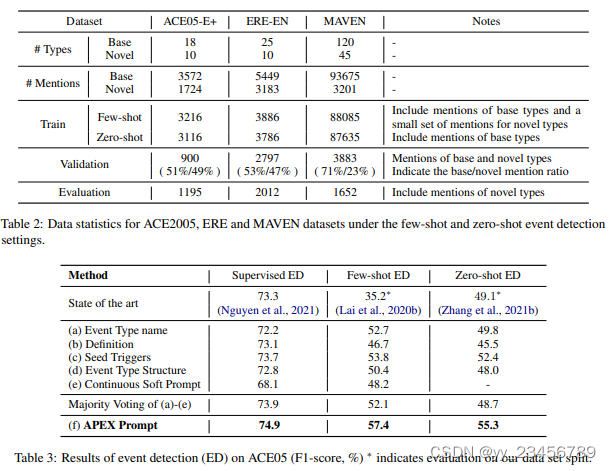
8.MetaEvent:Zero- and Few-Shot Event Detection via Prompt-Based Meta Learning
论文来源:ACL2023
论文链接:2305.17373.pdf (arxiv.org)
代码链接:https://github.com/Yueeeeeeee/MetaEvent https://github.com/Yueeeeeeee/MetaEvent
https://github.com/Yueeeeeeee/MetaEvent
摘要:随着新兴的在线话题成为众多新事件的源头,检测未见/罕见的事件类型对于现有的事件检测方法来说是一个难以克服的挑战,因为它们在训练时只能获得有限的数据访问权限。为了解决事件检测中的数据稀缺问题,我们提出了MetaEvent,这是一个基于元学习的零样本和少样本事件检测框架。具体而言,我们从现有的事件类型中采样训练任务,并执行元训练以快速适应未见任务搜索最佳参数。在我们的框架中,我们建议使用基于填空的任务提示和一种对触发器敏感的软词汇模型来有效地将输出投影到未见的事件类型上。此外,我们还设计了一种基于最大均值差异(MMD)的对比性元目标,用于学习区分类别的特征。因此,所提出的MetaEvent可以在没有任何先验知识的情况下通过将特征映射到事件类型来执行零样本事件检测。在我们的实验中,我们在零样本和少样本场景下展示了MetaEvent的有效性,其中所提出的方法在广泛的基准数据集FewEvent和MAVEN上取得了最先进的性能。
实验:FewEvent MAVEN
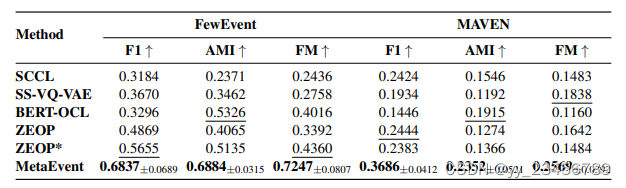
9.(Reasoning_In_EE) OntoED: Low-resource Event Detection with Ontology Embedding
论文来源:ACL2021
论文链接:OntoED: Low-resource Event Detection with Ontology Embedding (aclanthology.org)
代码链接:GitHub - 231sm/Reasoning_In_EE:ACL 2021 论文“OntoED:使用本体嵌入的低资源事件检测”的代码和数据集
摘要:事件检测(Event Detection,ED)旨在从给定的文本中识别事件触发词,并将其分类为事件类型。当前大多数ED方法严重依赖训练实例,几乎忽略了事件类型的相关性。因此,它们往往容易受到数据稀缺性的影响,无法处理新的未见事件类型。为了解决这些问题,我们将ED定义为事件本体生成的过程:将事件实例链接到事件本体中的预定义事件类型,并提出一个名为OntoED的新颖ED框架,该框架具有本体嵌入功能。我们在事件类型之间丰富了事件本体的联系,并进一步诱导了更多的事件-事件相关性。基于事件本体,OntoED可以利用和传播相关性知识,特别是从数据丰富的事件类型到数据贫乏的事件类型。此外,OntoED可以应用于新的未见事件类型,通过建立与现有类型的联系来实现。实验表明,OntoED在数据稀缺的情况下比先前的ED方法更为优越和稳健。
实验:OntoEvent is established based on two newly proposed datasets for ED: MAVEN (Wang et al., 2020b) and FewEvent
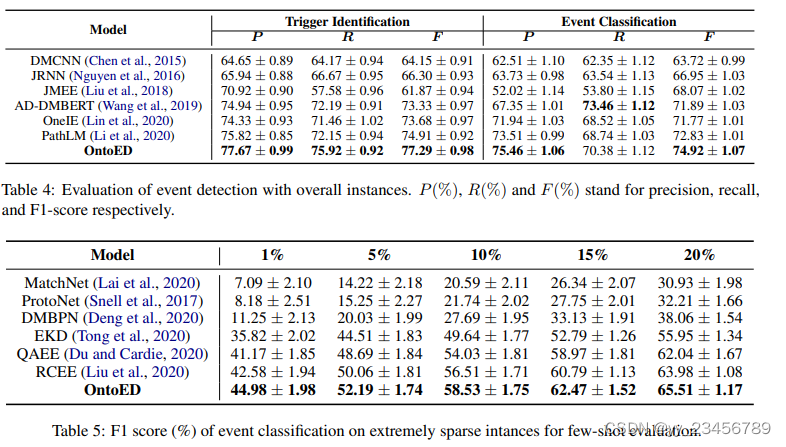
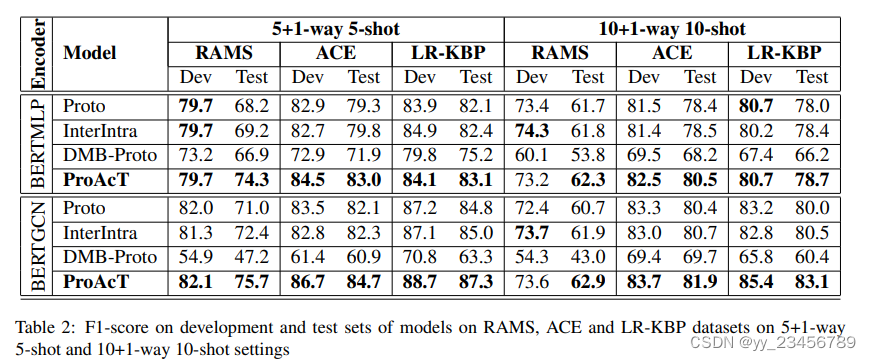
10.fsl-proact:Learning Prototype Representations Across Few-Shot Tasks for Event Detection
论文来源:ACL2021
论文链接:Learning Prototype Representations Across Few-Shot Tasks for Event Detection (aclanthology.org)
代码链接:http://github.com/ laiviet/fsl-proact
摘要:我们解决了在事件检测的少样本学习中存在的采样偏差和离群值问题,这是信息提取的一个子任务。我们通过引入跨任务原型来建模基于事件的少样本学习中不同训练任务之间的关系。我们还提出要在不同任务的分类器之间强制预测一致性,以使模型对离群值更加稳健。我们的广泛实验表明,在三个少样本学习数据集上的表现都得到了一致的改进。研究结果发现,当我们标记的新事件类型的标注数据有限时,我们的模型更稳健。
实验:RAMS、ACE、LR-KBP
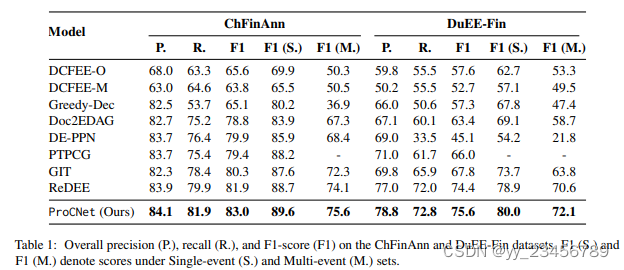
11.procnet:Document-Level Multi-Event Extraction with Event Proxy Nodes and Hausdorff Distance Minimization
论文来源:ACL2023
论文链接:2023.acl-long.563.pdf (aclanthology.org)
代码链接:https://github.com/xnyuwg/procnet
摘要:文档级多事件抽取旨在从给定文档中自动提取结构信息。最近的方法是涉及两个步骤:(1)建模实体交互;(2)将实体交互解码为事件。然而,这种方法忽略了多个事件的全局依赖性。此外,通过迭代地将其相关实体作为参数合并来解码事件,可能遭受到错误传播和计算效率低下的问题。在本论文中,我们提出了一种替代方法,使用事件代理节点和Hausdorff距离最小化进行文档级多事件抽取。事件代理节点(表示伪事件)能够与其他事件代理节点建立连接,有效地捕获全局信息。Hausdorff距离使比较预测事件集合和真实事件集合之间的相似性成为可能。通过直接最小化Hausdorff距离,模型可以直接朝着全局最优解训练,从而提高性能并减少训练时间。实验结果表明,在只有一小部分训练时间的情况下,我们的模型在两个数据集上的性能优于先前的最先进的方法,在F1-score方面表现出色。
实验:ChFinAnn、DuEE-Fin
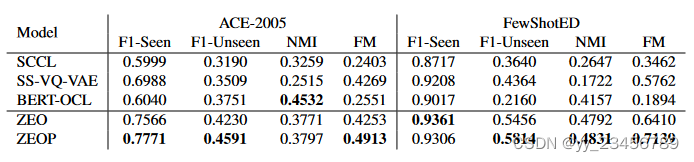
12、NAACL-ZEOP :Zero-Shot Event Detection Based on Ordered Contrastive Learning and Prompt-Based Prediction
论文来源:NAACL 2022
摘要:
事件检测是一项典型的自然语言处理任务。然而,不断出现的新事件不断出现的新事件使得有监督的方法不适用于未知类型。以前的零事件检测方法要么需要预先定义的事件类型作为启发式规则定义的事件类型作为启发式规则,或者借助外部语义分析工具。为了克服为克服这一弱点,我们提出了一种端到端框架工作框架。基于有序对比学习和提示预测(Zero-Shot Event Detection Based on Ordered Contrastive Learning and Prompt ZEOP)。通过创造性地引入通过创造性地引入多个具有或通过创造性地引入多个具有或有相似性的对比样本,编码器可以从实例级和提示级学习事件编码器可以从实例级和级学习事件表征,从而使不同未见类型之间的区别更加明显。不同未见类型之间的区别更加显著。同时,我们利用基于提示的预言来识别触发词,而无需依赖外部资源。实验证明与最先进的方法相比,我们的模型能更有效、更准确地检测事件。
实验:Ace-2005、 FewShotED
事件论元抽取EAE
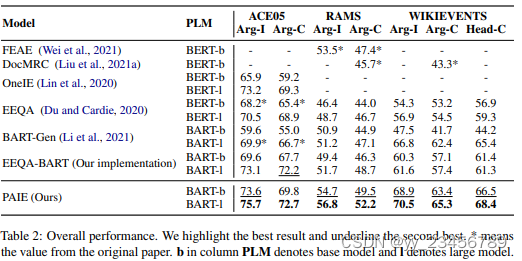
1. PAIE:Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction
论文来源:ACL2022
论文链接:2022.acl-long.466.pdf (aclanthology.org)
代码链接:https://github.com/mayubo2333/PAIE
摘要:本文提出了一种高效且有效的模型PAIE,可用于句子级和文档级事件参数提取(EAE),并且在缺乏训练数据时也能够很好地泛化。一方面,PAIE利用提示调整提取目标,以充分发挥预训练语言模型(PLMs)的优势。它引入了基于提示的两个跨度选择器,用于在输入文本中为每个角色选择开始/结束标记。另一方面,它通过多角色提示捕获参数交互,并通过二分匹配损失与最优跨度分配进行联合优化。此外,通过灵活的提示设计,PAIE可以提取具有相同角色的多个参数,而不是传统的启发式阈值调整。我们在三个基准上进行了广泛的实验,包括句子级和文档级EAE。结果表明PAIE有令人鼓舞的改进(在三个基准上平均分别提高了3.5%和2.3%的F1得分,PAIE-base和PAIE-large)。进一步的分析表明了不同提取提示调整策略的效率、对少样本设置的泛化能力和效力。
实验:ACE05、RAMS、WIKIEVENTS
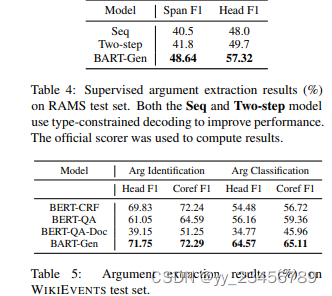
2.gen-arg:Document-Level Event Argument Extraction by Conditional Generation
论文来源:ACL2021
论文链接:Document-Level Event Argument Extraction by Conditional Generation (aclanthology.org)
代码链接:https://github.com/ raspberryice/gen-arg
摘要:事件提取长期以来被认为在IE社区中是一个句子级任务。我们认为这种设置不符合人类信息获取行为,并导致不完整和无信息性的提取结果。我们提出了一种文档级中性事件参数提取模型,通过将任务模拟为遵循事件模板的条件生成。我们还构建了一个新的文档级事件提取基准数据集WIKIEVENTS,其中包括完整的事件和共指注释。在参数提取任务上,我们在RAMS和WIKIEVENTS数据集上分别比下一个最佳模型实现了7.6%的绝对F1和5.7%的F1增益。在要求隐式共指推理的更具挑战性的任务中,我们比最佳基线实现了9.3%的F1增益。为了展示我们的模型的可移植性,我们还创建了第一个端到端的零样本事件提取框架,并在仅访问ACE上的10种类型的情况下实现了97%的完全监督模型的触发器提取性能和82%的参数提取性能。
实验:WIKIEVENTS、RAMS
3.TSAR:A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction
论文来源:NAACL2022
论文链接:2022.naacl-main.370.pdf (aclanthology.org)
代码链接:https://github.com/PKUnlp-icler/TSAR
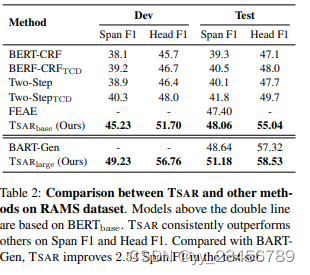
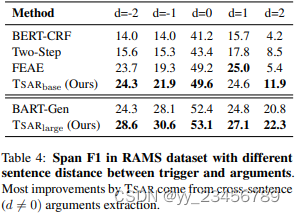
摘要:大多数先前的研究旨在从单个句子中提取事件,而文档级事件提取仍然没有得到充分的探索。在这篇论文中,我们专注于从整个文档中提取事件参数,主要面临着两个关键问题:a) 句子之间触发器和参数之间的长距离依赖关系;b) 对文档中的事件的干扰性上下文。为了解决这些问题,我们提出了一种双流抽象意义表示增强提取模型(TSAR)。TSAR通过双流编码模块以不同的角度对文档进行编码,以利用局部和全局信息并降低干扰性上下文的影响。此外,TSAR引入了一个基于本地和全局构建的AMR语义图的AMR引导交互模块,以捕获句子内和句子间的特征。引入辅助边界损失来显式地增强文本跨度的边界信息。广泛的实验表明,TSAR的性能明显优于以前的最先进的方法,在公共RAMS和WIKIEVENTS数据集上分别获得了2.54 F1和5.13 F1的提高,展示了跨句子参数提取方面的优越性。
实验:RAMS、WIKIEVENTS
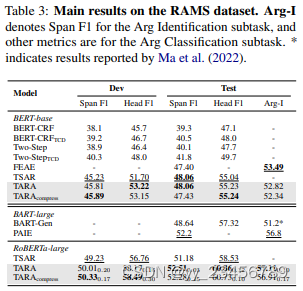
4.TARA:An AMR-based Link Prediction Approach for Document-level Event Argument Extraction
论文来源:ACL2023
论文链接:arxiv.org/pdf/2305.19162.pdf
代码链接:https://github.com/ayyyq/TARA
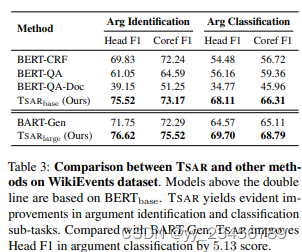
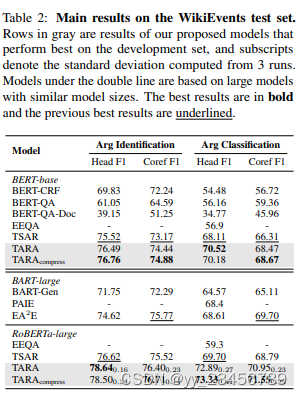
摘要:最近的一些工作引入了抽象意义表示(AMR)用于文档级事件参数提取(Doc-level EAE),因为AMR提供了复杂语义结构的有用解释,并有助于捕获长距离依赖关系。然而,在这些工作中,AMR仅被隐式地使用,例如作为附加特征或训练信号。基于所有事件结构都可以从AMR推断的事实,这项工作将EAE重新定义为AMR图上的链接预测问题。由于AMR是通用的结构,并不完全适合EAE,我们提出了一种新颖的图形结构 - 定制AMR图(TAG),它压缩了信息量较少的子图和边缘类型,整合了跨度信息,并突出显示同一文档中的周围事件。有了TAG,我们进一步提出了一种新的方法,即使用图神经网络作为链接预测模型来查找事件参数。我们在WikiEvents和RAMS上进行的广泛实验表明,这种方法比最先进的模型表现更好,分别提高了3.63个F1和2.33个F1,并且推理时间减少了56%。
实验:WikiEvents、RAMS
5.Document-Level Event Argument Extraction via Optimal Transport
论文来源:ACL2022
论文链接:2022.findings-acl.130.pdf (aclanthology.org)
代码链接:null
摘要:事件参数提取(EAE)是事件提取的子任务之一,旨在识别每个实体提及对特定事件触发器的作用。尽管先前在句子级EAE中取得了成功,但文档级设置的研究还比较少。具体来说,虽然句子的句法结构已经被证明对于句子级EAE有效,但是先前的文档级EAE模型完全忽略了文档的句法结构。因此,在本研究中,我们研究了句法结构在文档级EAE中的重要性。具体而言,我们提出了采用最优传输(OT)来基于句子级句法结构和针对EAE任务定制的文档结构来引入文档的结构。此外,我们还提出了一种新的规则化技术,以显式约束无关上下文词在EAE最终预测中的贡献。我们在基准文档级EAE数据集RAMS上进行了广泛的实验,导致了最先进的性能。此外,我们在ACE 2005数据集上的实验揭示了所提模型在句子级EAE中的有效性,并建立了新的最先进的结果。
实验:RAMS、ACE2005
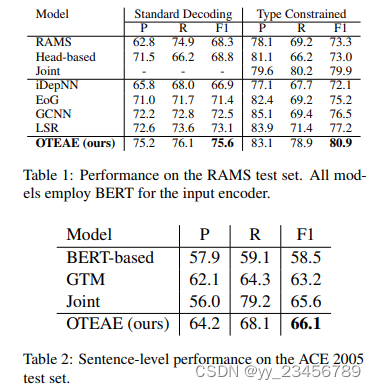
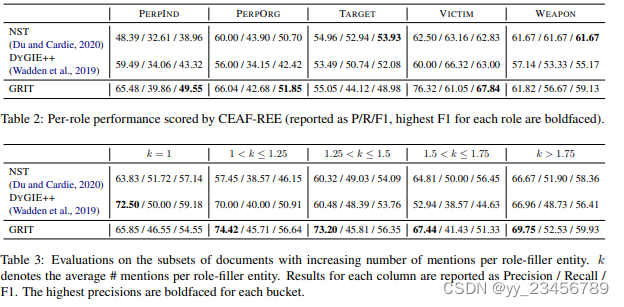
6.GRIT: Generative Role-filler Transformers for Document-level Event Entity Extraction
论文来源:EACL 2021
论文链接:GRIT: Generative Role-filler Transformers for Document-level Event Entity Extraction (aclanthology.org)
代码链接:https://github.com/xinyadu/grit_doc_ event_entity
摘要:我们重新审视了文档级角色填充实体提取(REE)的经典问题,用于模板填充。我们认为,句子级方法不适合这项任务,并引入了一种基于生成的Transformer编码器-解码器框架(GRIT),旨在在文档级别建模上下文:它可以跨越句子边界进行提取决策;隐式地意识到名词短语共指结构,并有能力尊重模板结构中的跨角色依赖关系。我们在MUC-4数据集上评估了我们的方法,并表明我们的模型表现明显优于先前的工作。我们还表明,我们的建模选择有助于模型性能,例如通过隐式捕捉诸如识别指代实体的核心语言知识。
实验:MUC-4
事件抽取EE
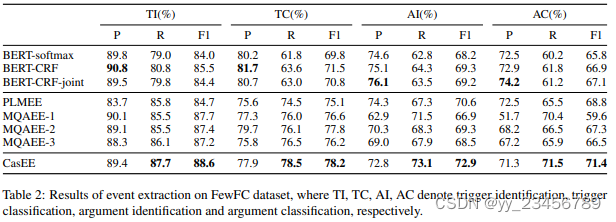
1.CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction
论文来源:ACL 2021
论文链接:https://arxiv.org/pdf/2107.01583.pdf
代码链接:https://github.com/JiaweiSheng/CasEE
摘要:事件提取(Event extraction,EE)是一项关键的信息提取任务,旨在从文本中提取事件信息。然而,大多数现有方法都假设事件在句子中不重叠出现,这并不适用于复杂的重叠事件提取。这项工作系统地研究了现实中的重叠问题,即一个单词可能作为多个类型或具有不同角色的多个参数的触发器。为了解决上述问题,我们提出了一种新的基于级联解码的重叠事件提取联合学习框架,称为CasEE。具体来说,CasEE顺序执行类型检测、触发器提取和参数提取,其中重叠目标是根据特定的前一个预测分别提取的。所有子任务都在一个框架内联合学习,以捕捉子任务之间的依赖关系。在一个公共的事件提取基准FewFC上的评估表明,CasEE1在重叠事件提取方面比先前的竞争方法取得了显著改进。
实验:FewFC
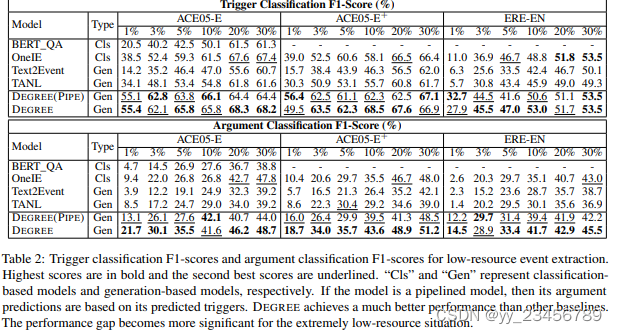
2.DEGREE: A Data-Efficient Generation-Based Event Extraction Model
论文来源:ACL 2022
论文链接:2022.naacl-main.138.pdf (aclanthology.org)
代码链接:https: //github.com/PlusLabNLP/DEGREE
摘要:事件提取需要高质量的专家人工注释,这通常很昂贵。因此,学习一种可以用少量标记示例训练的数据高效的事件提取模型成为了一项关键挑战。在本文中,我们专注于低资源端到端事件提取,并提出DEGREE,这是一种将事件提取视为条件生成问题的数据高效模型。给定一篇文章和一个手动设计的提示,DEGREE学习将文章中提到的事件总结为遵循预定义模式的自然句子。最终的事件预测然后使用确定性算法从生成的句子中提取出来。DEGREE具有三个优势,可以在更少的训练数据下学习良好。首先,我们设计的描述为DEGREE提供了语义指导,以利用标签语义从而更好地捕捉事件参数。此外,DEGREE能够使用附加的弱监督信息,例如提示中编码的事件描述。最后,DEGREE以端到端的方式联合学习触发器和参数,这鼓励模型更好地利用它们之间的共享知识和依赖关系。我们的经验结果表明DEGREE在低资源事件提取方面表现强劲。
实验:ACE 2005、ERE-EN
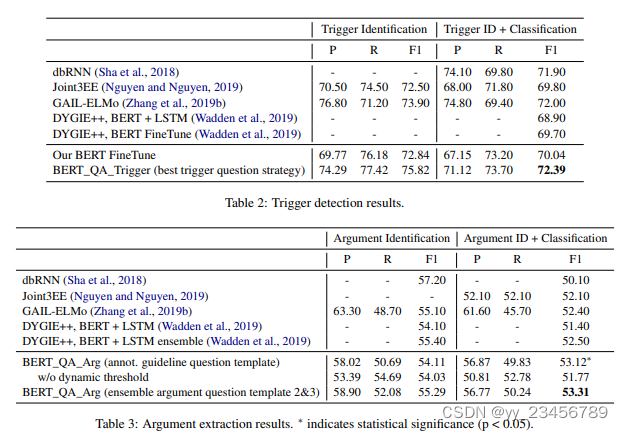
3.eeqa:Event Extraction by Answering (Almost) Natural Questions
论文来源:2020
论文链接:Event Extraction by Answering (Almost) Natural Questions (aclanthology.org)
代码链接: https://github.com/xinyadu/eeqa
摘要:事件提取的问题需要检测事件触发器并提取其相应的参数。现有事件参数提取工作通常严重依赖实体识别作为预处理/并发步骤,导致众所周知的错误传播问题。为了避免这个问题,我们引入了一种新的范式来提取事件,将其表述为一个问答(QA)任务,以端到端的方式提取事件参数。实证结果表明,我们的框架远远超过了先前的方法;此外,它还能够为在训练时没有见过的角色(即零射击学习设置)提取事件参数。
实验:ACE 2005

















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









