







探索AI新时代:从GPT-4o特性到实用技巧,解锁高效AI助手的全部潜力
猫头虎是谁?
大家好,我是 猫头虎,别名猫头虎博主,擅长的技术领域包括云原生、前端、后端、运维和AI。我的博客主要分享技术教程、bug解决思路、开发工具教程、前沿科技资讯、产品评测图文、产品使用体验图文、产品优点推广文稿、产品横测对比文稿,以及线下技术沙龙活动参会体验文稿。内容涵盖云服务产品评测、AI产品横测对比、开发板性能测试和技术报告评测等。
目前,我活跃在CSDN、51CTO、腾讯云开发者社区、阿里云开发者社区、知乎、微信公众号、视频号、抖音、B站和小红书等平台,全网拥有超过30万的粉丝,统一IP名称为 猫头虎 或者 猫头虎博主。希望通过我的分享,帮助大家更好地了解和使用各类技术产品。
原创作者 ✍️
- 博主:猫头虎
- 全网搜索关键词:猫头虎
- 作者微信号:Libin9iOak
- 作者公众号:猫头虎技术团队
- 更新日期:2024年6月16日
- 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
专栏链接 🔗
- 精选专栏:
- 《面试题大全》 — 面试准备的宝典!
- 《IDEA开发秘籍》 — 提升你的IDEA技能!
- 《100天精通鸿蒙》 — 从Web/安卓到鸿蒙大师!
- 《100天精通Golang(基础入门篇)》 — 踏入Go语言世界的第一步!
- 《100天精通Go语言(精品VIP版)》 — 踏入Go语言世界的第二步!
领域矩阵 🌐
加入猫头虎的技术圈,一起探索编程世界的无限可能! 🚀

GPT-4o是 OpenAI 广受欢迎的大型多模态模型GPT-4的第三次主要迭代,该模型通过 Vision 扩展了 GPT-4的功能。新发布的模型能够以集成和无缝的方式与用户交谈、查看和交互,在使用 ChatGPT 界面时比以前的版本更加出色。
在GPT-4o 公告中,OpenAI 重点介绍了该模型的“更自然的人机交互”能力。在本文中,我们将讨论 GPT-4o 是什么、它与之前的模型有何不同、评估其性能以及 GPT-4o 的用例。
什么是 GPT-4o?
OpenAI 的 GPT-4o,“o”代表 omni(意思是“全部”或“普遍”),于 2024 年 5 月 13 日在直播公告和演示中发布。它是一个具有文本、视觉和音频输入和输出功能的多模态模型,基于OpenAI 的 GPT-4的上一个版本(带有视觉模型 GPT-4 Turbo)。GPT-4o 的强大功能和速度来自于它是一个处理多种模态的单一模型。以前的 GPT-4 版本使用了多个单一用途的模型(语音到文本、文本到语音、文本到图像),并创建了在不同任务之间切换模型的碎片化体验。
OpenAI 声称,与 GPT-4T 相比,它的速度提高了一倍,输入令牌(每百万 5 美元)和输出令牌(每百万 15 美元)都便宜了 50%,并且速率限制提高了五倍(每分钟最多 1000 万个令牌)。GPT-4o 具有 128K 上下文窗口,知识截止日期为 2023 年 10 月。目前,一些新功能可通过 ChatGPT、桌面和移动设备上的 ChatGPT 应用程序、OpenAI API(参见API 发行说明)和Microsoft Azure在线获得。
GPT-4o 有什么新功能?
虽然发布演示仅展示了 GPT-4o 的视觉和音频功能,但发布博客中包含的示例远远超出了 GPT-4 先前版本的功能。与前代产品一样,它具有文本和视觉功能,但 GPT-4o 还具有对包括视频在内的所有支持模式的原生理解和生成功能。
正如 Sam Altman 在个人博客中指出的那样,最令人兴奋的进步是模型的速度,尤其是当模型通过语音进行交流时。这是第一次几乎零延迟的响应,你可以像在日常与人交谈中互动一样与 GPT-4o 互动。
在发布带有 Vision 的 GPT-4 不到一年后(参见我们对2023 年 9 月GPT-4的分析),OpenAI 在性能和速度方面取得了重大进步,您一定不会错过。
让我们开始吧!
GPT-4o 的文本评估
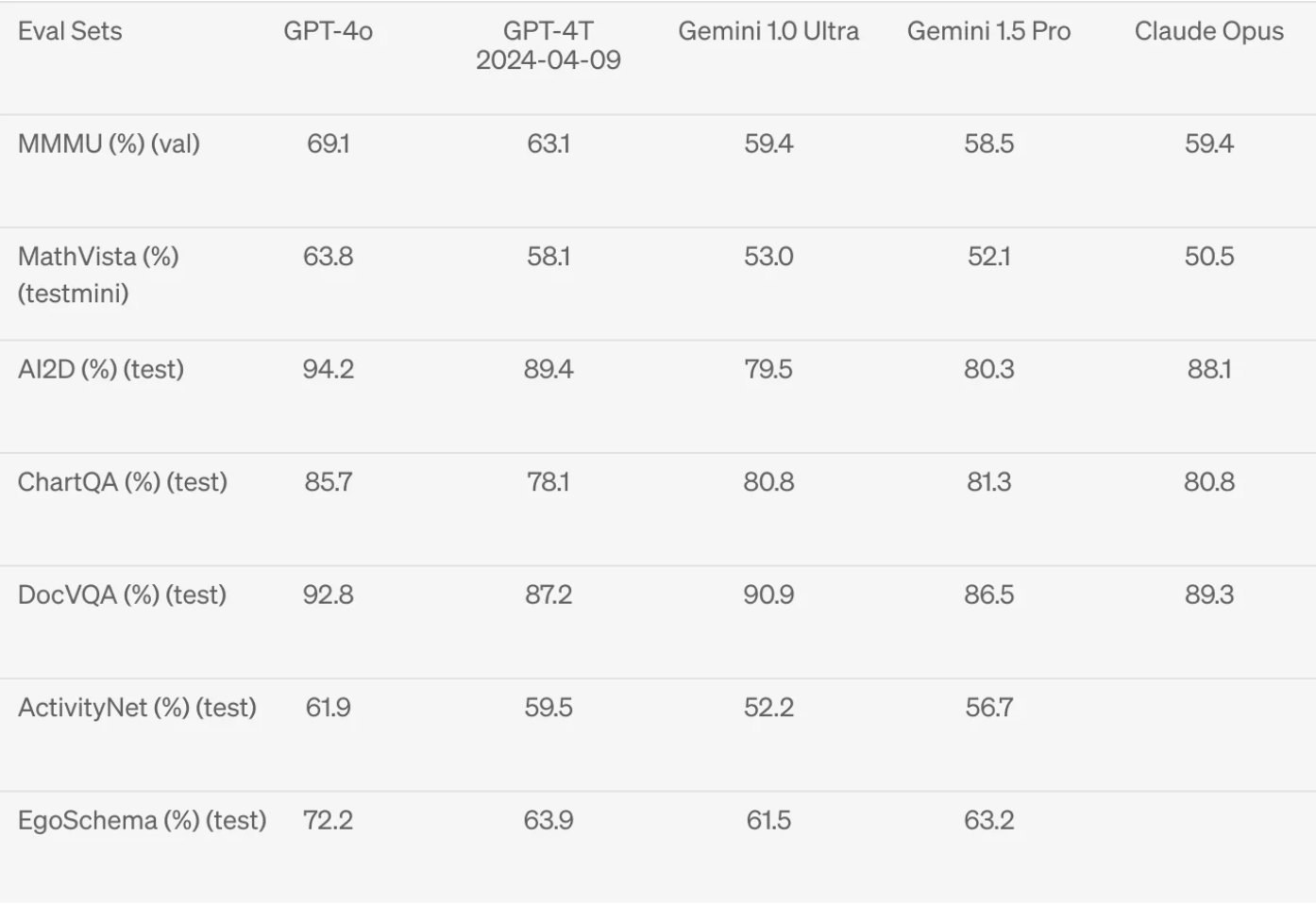
对于文本,根据 OpenAI 自行发布的基准测试结果,与其他 LMM(如之前的 GPT-4 版本、Anthropic 的 Claude 3 Opus、谷歌的 Gemini 和 Meta 的 Llama3)相比,GPT-4o 的得分略有提高或相似。
请注意,在提供的文本评估基准测试结果中,OpenAI 比较了 Meta 的 Llama3 的 400b 变体。在发布结果时,Meta 尚未完成对其 400b 变体模型的训练。
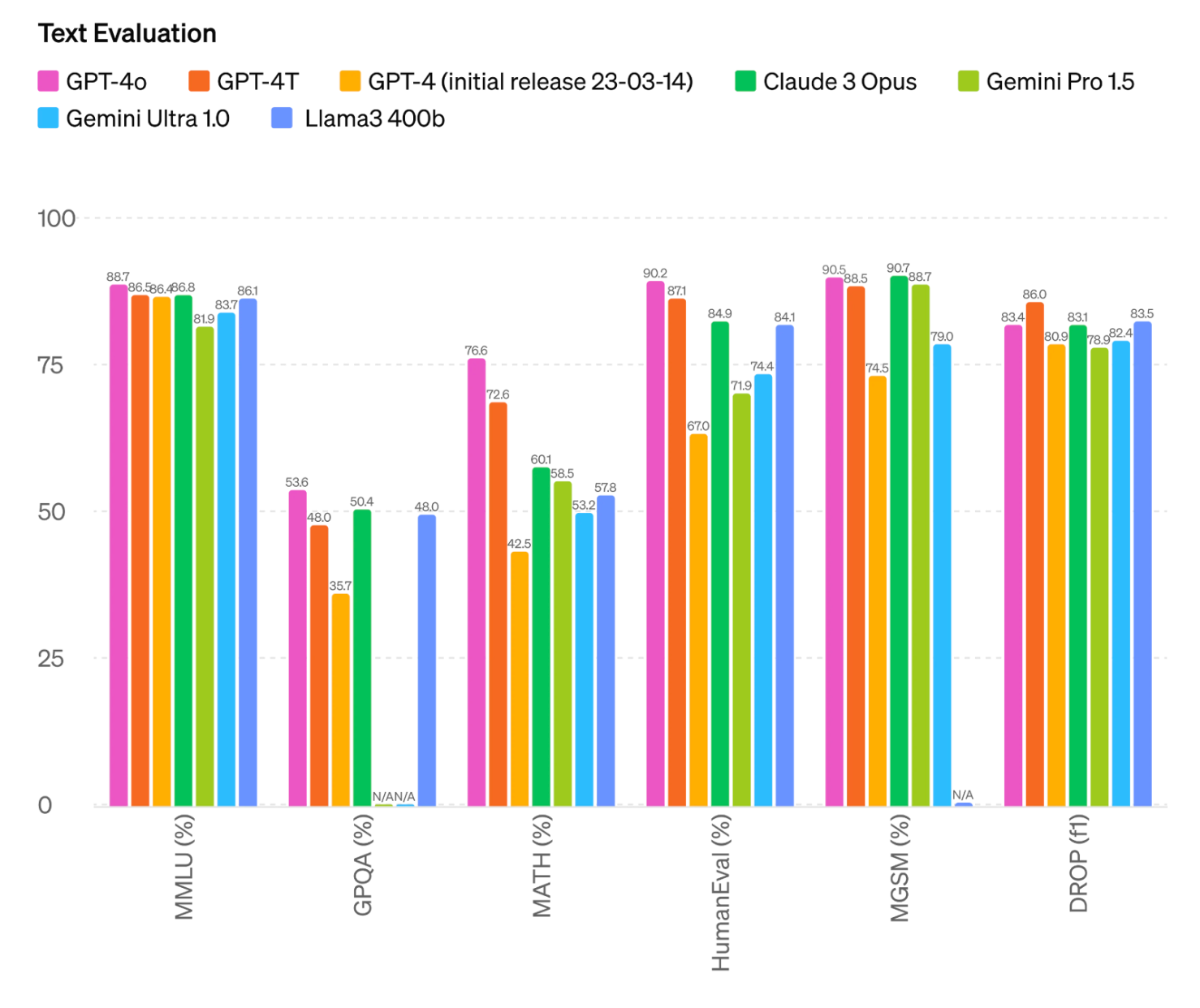 图片来源:OpenAI
图片来源:OpenAI
GPT-4o 的视频功能
API 发行说明中有关视频使用的重要说明:“API 中的 GPT-4o 支持通过视觉功能理解视频(不带音频)。具体来说,视频需要转换为帧(每秒 2-4 帧,统一采样或通过关键帧选择算法采样)才能输入到模型中。”使用OpenAI 视觉手册可以更好地了解如何使用视频作为输入以及版本的局限性。
GPT-4o 被证明既具有查看和理解上传的视频文件中的视频和音频的能力,也具有生成短视频的能力。
在初始演示中,GPT-4o 多次被要求对视觉元素进行评论或回应。与我们对Gemini 的初步观察类似,演示并未明确说明模型是在接收视频还是在需要“查看”实时信息时触发图像捕获。在初始演示中,有一段时间GPT-4o 可能没有触发图像捕获,因此看到了之前捕获的图像。
在 YouTube 上的这段演示视频中,GPT-4o “注意到” 一个人走到 Greg Brockman 身后,做了兔子耳朵。在可见的手机屏幕上,除了音效外,还会出现“眨眼”动画。这意味着 GPT-4o 可能使用与 Gemini 类似的视频处理方法,即在提取视频图像帧的同时处理音频。
! 演示视频的裁剪部分展示了 GPT-4o“闪烁”的动画。
唯一演示的视频生成示例是 3D 模型视频重建,但据推测它可能具有生成更复杂视频的能力。
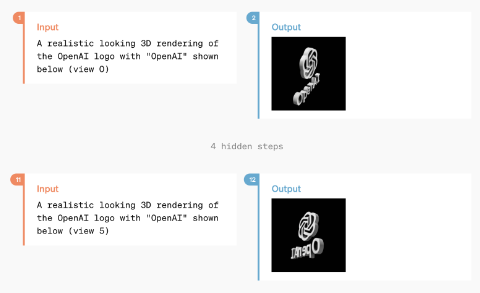
GPT-4o 之间的一次交换,用户请求并接收基于多张参考图像的旋转徽标的 3D 视频重建
GPT-4o 的音频功能
与视频和图像类似,GPT-4o 还具备提取和生成音频文件的能力。
GPT-4o 对生成的声音表现出了令人印象深刻的精细控制水平,能够改变交流速度、根据要求改变音调,甚至按需唱歌。GPT-4o 不仅可以控制自己的输出,还能理解输入音频的声音作为任何请求的附加上下文。演示显示,GPT-4o 会向试图说中文的人提供音调反馈,并在呼吸练习期间反馈某人的呼吸速度。
根据自行发布的基准测试,GPT-4o 的表现优于 OpenAI 自己的 Whisper-v3(自动语音识别(ASR)领域之前最先进的技术),并且优于 Meta 和 Google 的其他模型的音频翻译。
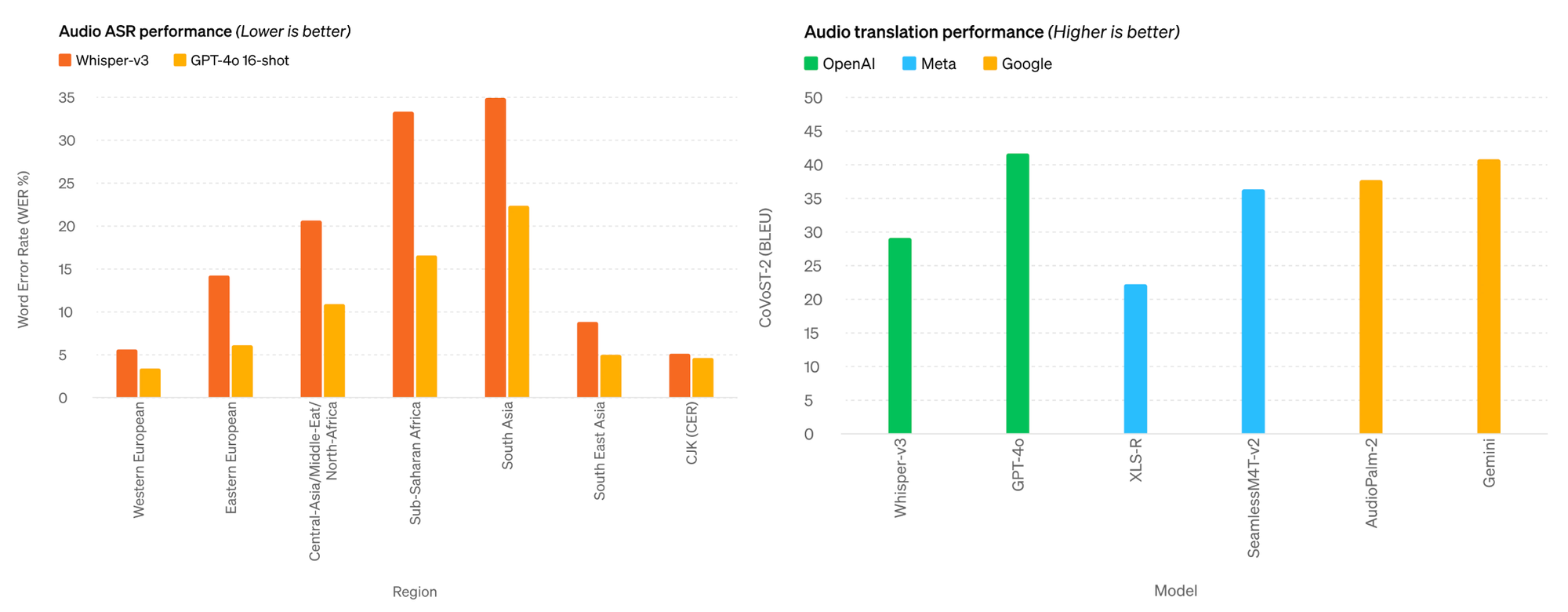 图片来源:OpenAI
图片来源:OpenAI
使用 GPT-4o 生成图像
GPT-4o 具有强大的图像生成能力,展示了一次性基于参考的图像生成和准确的文本描述。
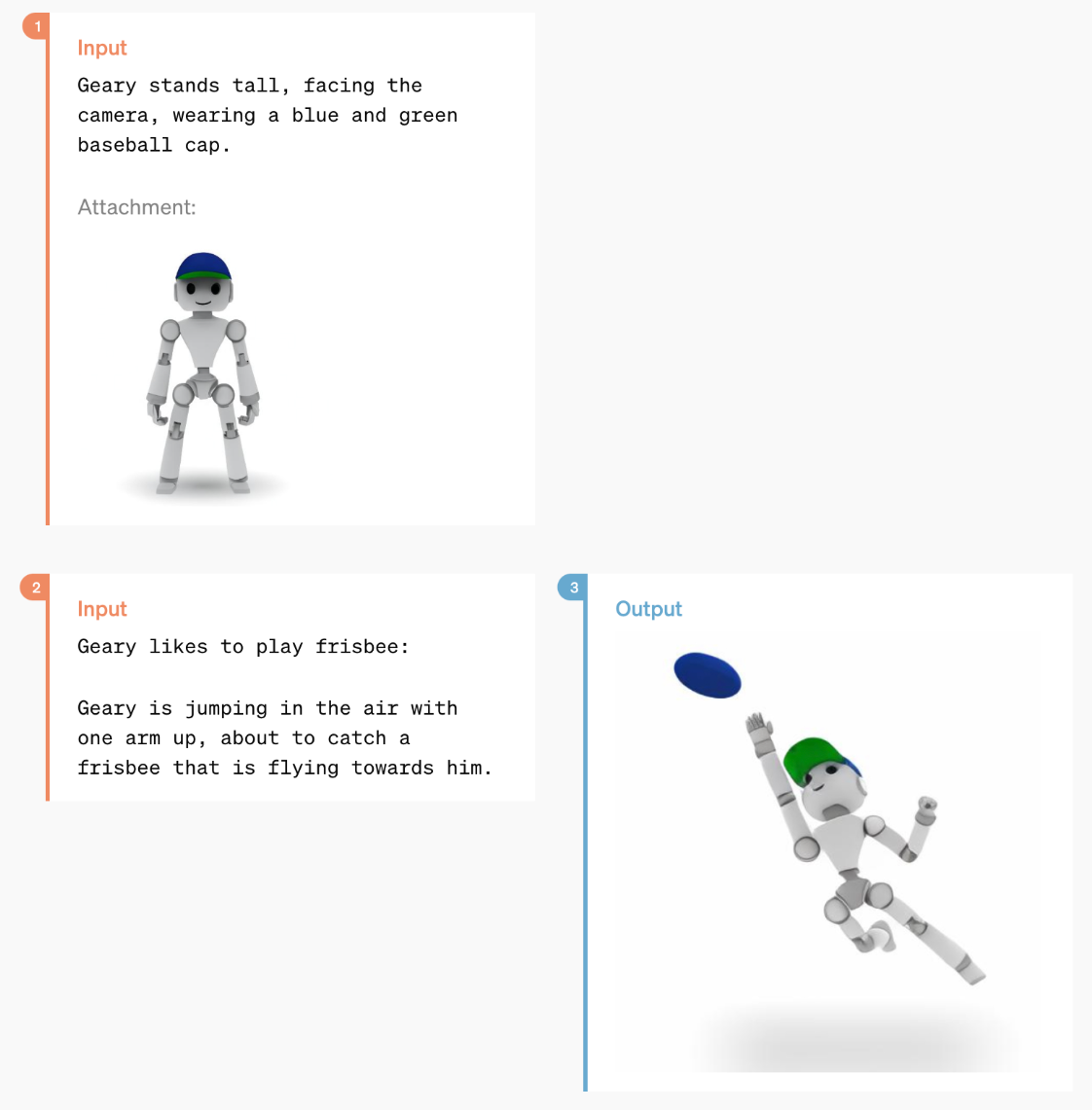
用户 / GPT-4o 交换生成图像(图片来源:OpenAI)
考虑到保留特定单词并将其转换为替代视觉设计的要求,下面的图像尤其令人印象深刻。这项技能与 GPT-4o 创建自定义字体的能力类似。
 来自各种提示的 GPT-4o 输出示例(图片来源:OpenAI)
来自各种提示的 GPT-4o 输出示例(图片来源:OpenAI)
GPT-4o 的视觉理解
尽管在之前的迭代中已经具备了最先进的能力,但视觉理解能力得到了改进,在与 GPT-4T、Gemini 和 Claude 的多个视觉理解基准测试中达到了最先进的水平。Roboflow 维护着一套不太正式的视觉理解评估,请参阅开源大型多模态模型的真实世界视觉用例结果。
 图片来源:OpenAI
图片来源:OpenAI
尽管 OpenAI 尚未公布 GPT-4o 的 OCR 能力,但我们将在本文后面对其进行评估。
评估 GPT-4o 的视觉用例
接下来,我们同时使用 OpenAI API 和 ChatGPT UI 来评估 GPT-4o 的不同方面,包括光学字符识别(OCR)、文档 OCR、文档理解、视觉问答(VQA) 和对象检测。

使用 GPT-4o 进行光学字符识别 (OCR)
OCR 是一种常见的计算机视觉任务,用于以文本格式返回图像中的可见文本。在这里,我们提示 GPT-4o “读取序列号。”和“读取图片中的文本”,它都正确回答了这两个问题。
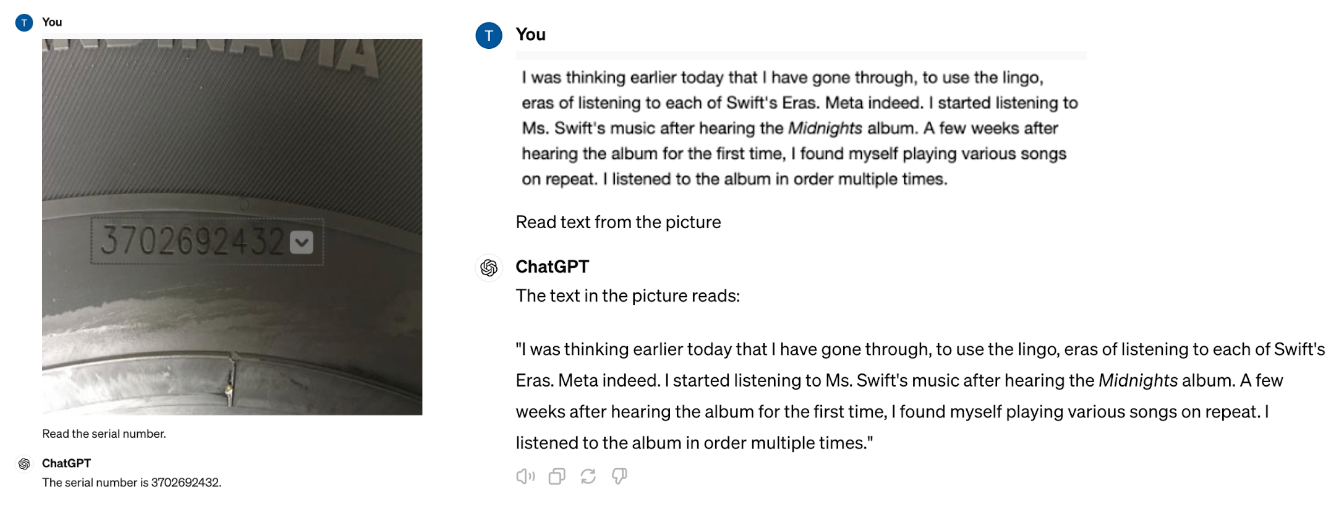 GPT-4o 提示 OCR 问题
GPT-4o 提示 OCR 问题
接下来,我们在用于在真实世界数据集上 测试其他 OCR 模型的同一数据集上对 GPT-4o 进行了评估。
我们发现平均准确率为 94.12%(比 GPT-4V 高 10.8%),中位准确率为 60.76%(比 GPT-4V 高 4.78%),平均推理时间为 1.45 秒。
与 GPT-4V 相比,速度提升了 58.47%,使得 GPT-4o 在速度效率(给定时间的准确度指标,按准确度除以经过的时间来计算)类别中处于领先地位。
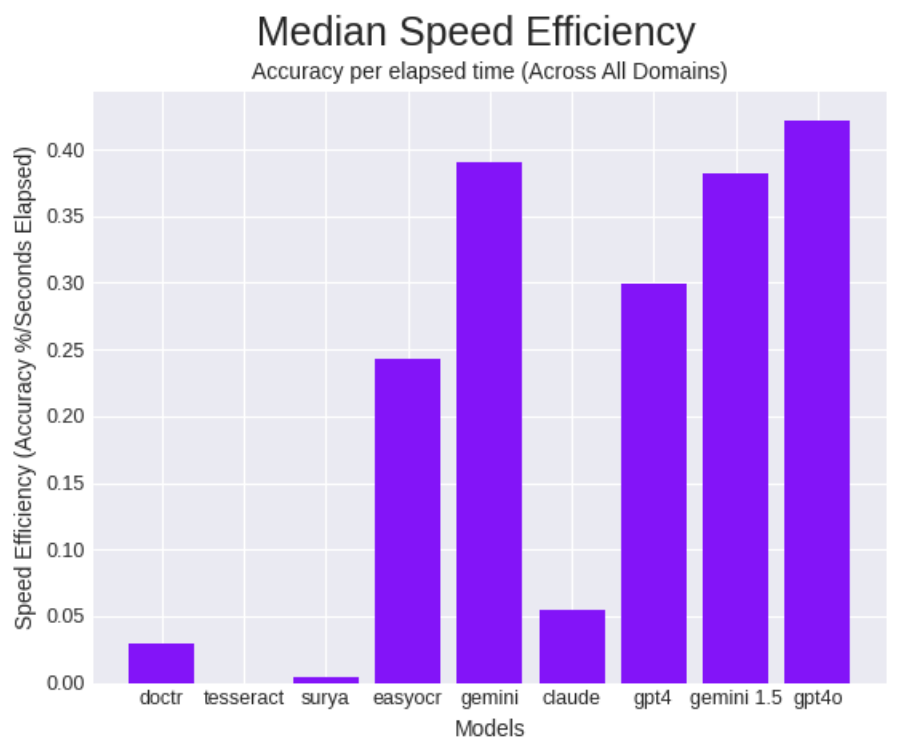 与其他支持 OCR 的型号相比,速度效率处于中等水平
与其他支持 OCR 的型号相比,速度效率处于中等水平
使用 GPT4-o 进行文档理解
接下来,我们评估 GPT-4o 从文本密集的图像中提取关键信息的能力。向 GPT-4o 询问“我付了多少税?”(指收据)和“熏牛肉披萨的价格是多少?”(指披萨菜单),GPT-4o 都正确回答了这两个问题。
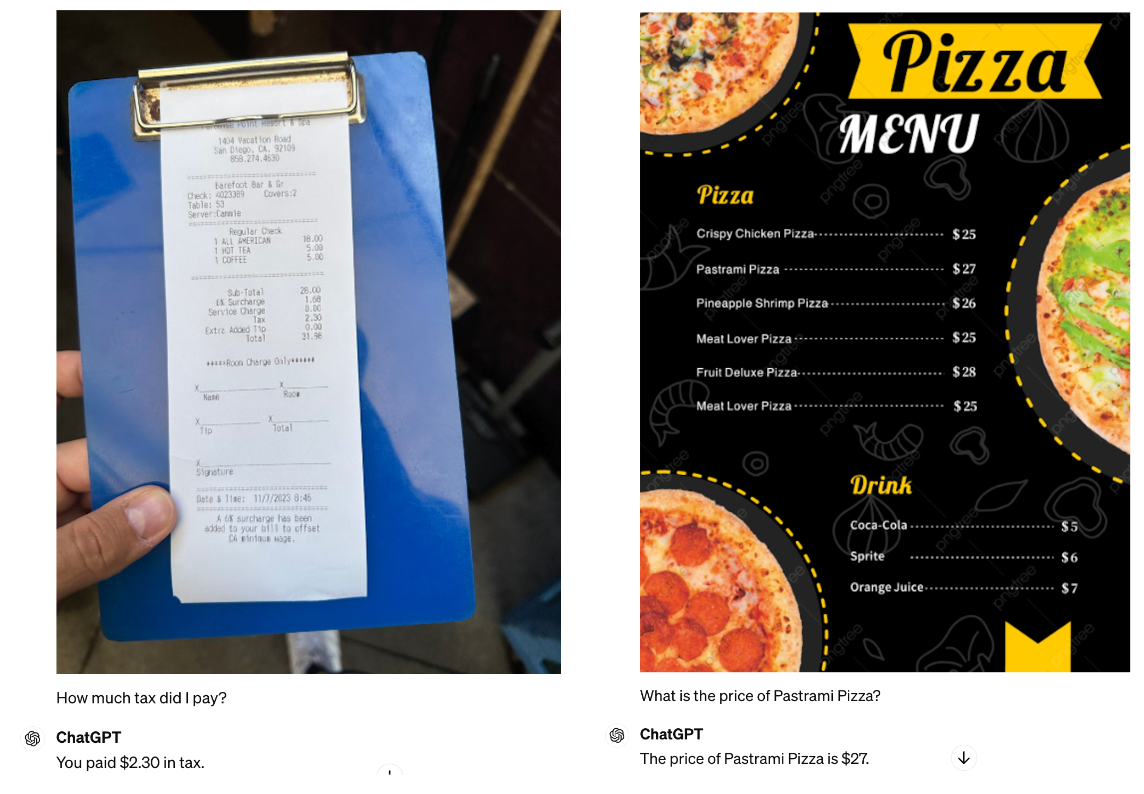
这是对 GPT-4 Vision 的改进,之前它无法从收据中提取税款。
使用 GPT-4o 进行视觉问答
接下来是一系列视觉问答提示。首先,我们询问 GPT-4o 在一张有四枚硬币的图像中数出了多少枚硬币。
GPT-4o 的答案是五枚硬币。然而,当重试时,它确实回答正确了。响应的这种变化是GPT Checkup网站存在的原因——闭源 LMM 的性能会随着时间的推移而变化,监控其性能非常重要,这样您就可以放心地在应用程序中使用 LMM。

这表明 GPT-4o 的计数能力与我们在 GPT-4 Vision 中看到的一样不一致。
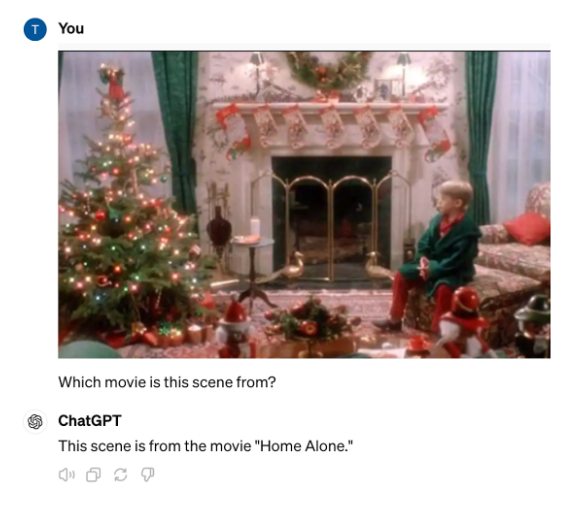
此外,GPT-4o 正确识别了《小鬼当家》场景中的图像。
使用 GPT-4o 进行对象检测
最后,我们测试了物体检测,事实证明这对于多模态模型来说是一项艰巨的任务。 Gemini、GPT-4 with Vision 和 Claude 3 Opus 都失败了,而 GPT-4o 也未能生成准确的边界框。
 GPT-4o 的两个不同实例响应了错误的物体检测坐标,这两个坐标均在最右侧图像上进行了注释。(左侧坐标为黄色,右侧坐标为蓝色)
GPT-4o 的两个不同实例响应了错误的物体检测坐标,这两个坐标均在最右侧图像上进行了注释。(左侧坐标为黄色,右侧坐标为蓝色)
GPT-4o 用例
随着 OpenAI 继续扩展 GPT-4 的功能,并最终发布 GPT-5,用例将呈指数级增长。GPT-4 的发布使图像分类和标记变得非常容易,尽管 OpenAI 的开源CLIP 模型性能相似,但成本要低得多。添加视觉功能使得将GPT-4 与计算机视觉管道中的其他模型相结合成为可能,这为使用 GPT-4 增强开源模型创造了机会,从而可以使用视觉实现功能更全面的自定义应用程序。
GPT-4o 的一些关键元素开辟了另一组以前不可能实现的用例,而这些用例都与基准测试中模型性能的提高无关。Sam Altman 的个人博客表示,他们有一个明确的意图,即“创建人工智能,然后其他人会用它来创造各种让我们都受益的令人惊叹的东西”。如果 OpenAI 的目标是不断降低成本并提高性能,那么这将把事情带到何处?
让我们考虑一些新的用例。
实时计算机视觉用例
新的速度改进与视觉和音频相结合,最终为 GPT-4 开辟了实时用例,这对于计算机视觉用例尤其令人兴奋。使用周围世界的实时视图并能够与 GPT-4o 模型对话意味着您可以快速收集情报并做出决策。这对于从导航到翻译到引导说明再到理解复杂的视觉数据等所有事情都很有用。
以与极其有能力的人类交互的速度与 GPT-4o 交互意味着,随着人工智能不断满足您的需求,您将花费更少的时间向我们的人工智能输入文本,而有更多的时间与周围的世界交互。
单设备多模式用例
让 GPT-4o 在桌面和移动设备上运行(如果这种趋势继续下去,Apple VisionPro等可穿戴设备也会出现),您可以使用一个界面来解决许多任务。您可以显示桌面屏幕,而不是输入文本来提示您如何回答问题。您无需将内容复制并粘贴到 ChatGPT 窗口中,而是在传递视觉信息的同时提出问题。这减少了在各种屏幕和模型之间切换的次数,并减少了创建集成体验的提示要求。
GPT4-o 的单一多模式模型消除了摩擦、提高了速度并简化了设备输入的连接,从而降低了与模型交互的难度。
通用企业应用程序
GPT-4o 将更多模态集成到一个模型中,并提高了性能,因此适用于企业应用程序管道中不需要对自定义数据进行微调的某些方面。虽然比运行开源模型要昂贵得多,但更快的性能使 GPT-4o 在构建自定义视觉应用程序时更实用。
您可以在尚未提供开源模型或微调模型的地方使用 GPT-4o,然后将自定义模型用于应用程序中的其他步骤,以增强 GPT-4o 的知识或降低成本。这意味着您可以快速开始对复杂的工作流程进行原型设计,而不会受到许多用例的模型功能的限制。
结论
GPT-4o 的最新改进包括速度提高了两倍、成本降低了 50%、速率限制降低了 5 倍、上下文窗口大小为 128K 以及单一多模态模型,这些对于构建 AI 应用程序的人们来说都是令人兴奋的进步。越来越多的用例适合用 AI 来解决,而多个输入可实现无缝界面。
更快的性能和图像/视频输入意味着 GPT-4o 可与自定义微调模型和预先训练的开源模型一起 用于计算机视觉工作流程,以创建企业应用程序。
参考资料
Leo Ueno、Trevor Lynn。(2024 年 5 月 14 日)。GPT-4o:综合指南和说明。Roboflow 博客:https://blog.roboflow.com/gpt-4o-vision-use-cases/
👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击下方文末名片获取更多信息。我是猫头虎博主,期待与您的交流! 🦉💬

联系与版权声明 📩
- 联系方式:
- 微信: Libin9iOak
- 公众号: 猫头虎技术团队
- 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击✨⬇️下方名片⬇️✨,加入猫头虎领域社群矩阵。一起探索科技的未来,共同成长。🚀



















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











