







DeepSeek不同参数版本在vLLM部署过程中的常见问题及解决方案
1. 前言
1.1 DeepSeek模型简介
DeepSeek系列模型是基于Transformer架构的大语言模型,提供从1.5B到671B不同参数规模的版本。其特点包括:
-
改进的注意力机制
-
动态稀疏激活策略
-
多阶段预训练优化

作者简介
猫头虎是谁?
大家好,我是 猫头虎,猫头虎技术团队创始人,也被大家称为猫哥。我目前是COC北京城市开发者社区主理人、COC西安城市开发者社区主理人,以及云原生开发者社区主理人,在多个技术领域如云原生、前端、后端、运维和AI都具备丰富经验。
我的博客内容涵盖广泛,主要分享技术教程、Bug解决方案、开发工具使用方法、前沿科技资讯、产品评测、产品使用体验,以及产品优缺点分析、横向对比、技术沙龙参会体验等。我的分享聚焦于云服务产品评测、AI产品对比、开发板性能测试和技术报告。
目前,我活跃在CSDN、51CTO、腾讯云、阿里云开发者社区、华为云开发者社区、知乎、微信公众号、视频号、抖音、B站、小红书等平台,全网粉丝已超过30万。我所有平台的IP名称统一为猫头虎或猫头虎技术团队。
我希望通过我的分享,帮助大家更好地掌握和使用各种技术产品,提升开发效率与体验。
作者名片 ✍️
- 博主:猫头虎
- 全网搜索关键词:猫头虎技术团队
- 作者微信号:Libin9iOak
- 作者公众号:猫头虎技术团队
- 更新日期:2025年03月06日
- 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
加入我们AI共创团队 🌐
- 猫头虎AI共创社群矩阵列表:
加入猫头虎的共创圈,一起探索编程世界的无限可能! 🚀
正文
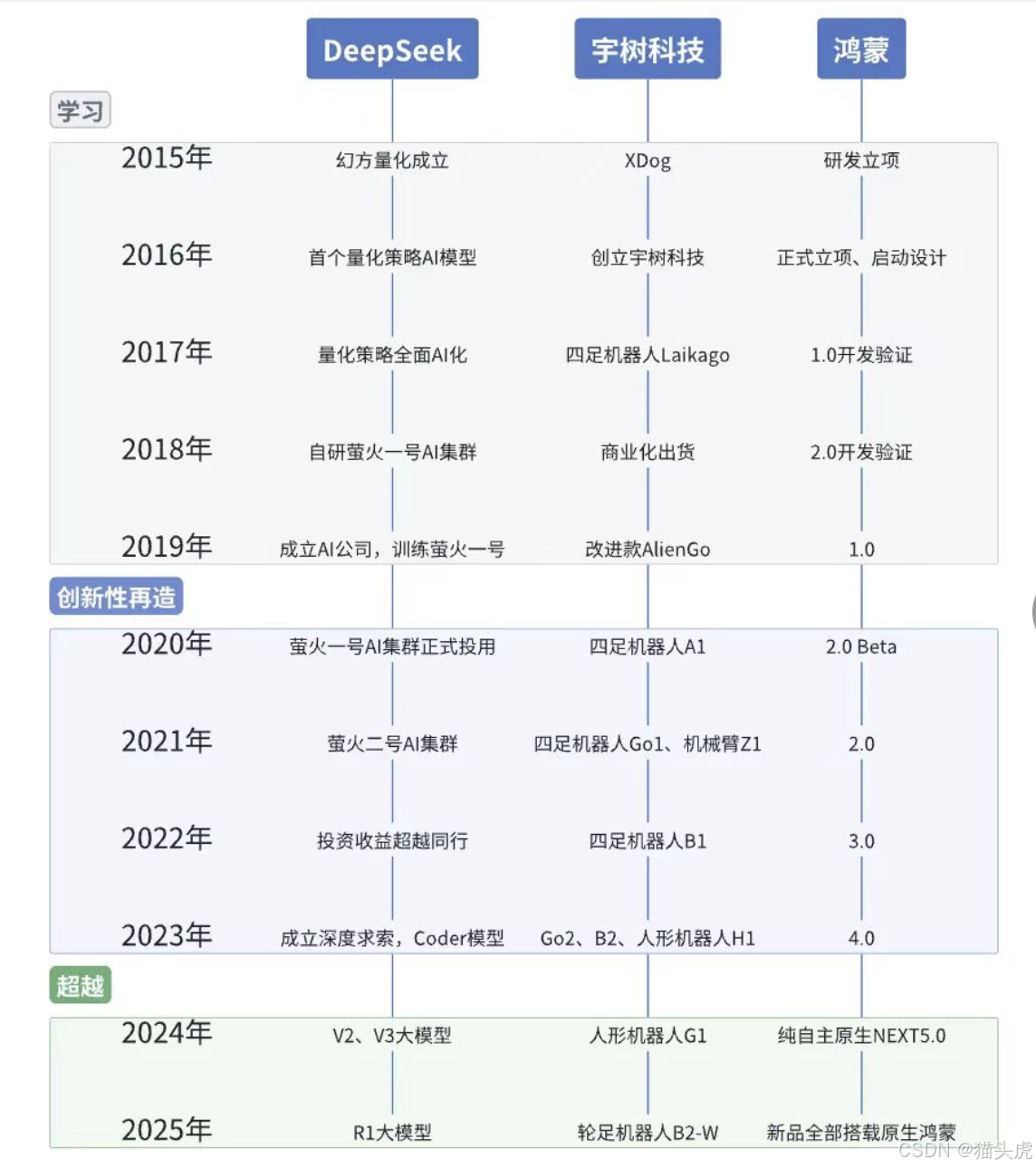
DeepSeek 的发展史
1.2 vLLM框架特性
vLLM是专为LLM推理优化的框架,核心优势:
- PagedAttention显存管理
- 连续批处理(Continuous Batching)
- 低延迟高吞吐量
1.3 不同参数版本的特点
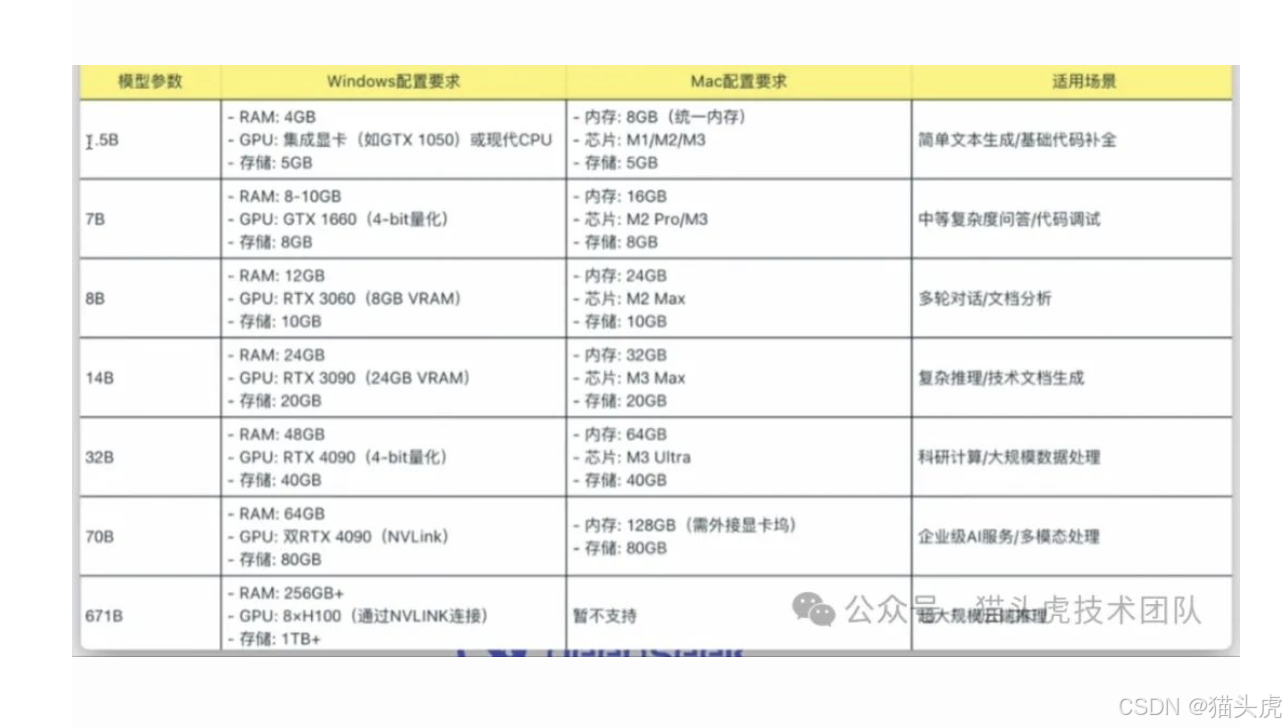
2. 部署环境准备
2.1 硬件要求与推荐配置
最低要求:
- CUDA 11.8+
- NVIDIA Driver 535+
- PCIe 4.0 x16

推荐配置:
# 检查GPU拓扑结构
nvidia-smi topo -m
2.2 基础依赖项安装
推荐使用Docker环境:
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
RUN pip install vllm==0.3.2 \
deepseek-utils==1.2.0 \
flash-attn==2.3.3
2.3 模型下载与转换
处理不同版本模型:
from deepseek import convert_to_vllm_format
# 转换7B版本
convert_to_vllm_format(
input_dir="deepseek-7b-hf",
output_dir="deepseek-7b-vllm",
shard_size="10GB"
)
# 对于32B以上大模型需添加:
convert_to_vllm_format(..., max_shard_workers=8)
3. 常见问题分类及解决方案
3.1 环境配置类问题
问题1:CUDA版本不兼容
- 现象:
CUDA error: no kernel image is available for execution - 解决方案:
# 查看vLLM支持的CUDA架构 python -c "from vllm._C import get_compute_capability; print(get_compute_capability())" # 重新编译 export VLLM_TARGET_DEVICES=cuda pip install --no-build-isolation vllm
问题2:Python包冲突
- 现象:
AttributeError: module 'torch' has no attribute 'compile' - 解决步骤:
- 创建纯净虚拟环境
- 固定依赖版本:
torch==2.1.2 transformers==4.35.2
3.2 显存管理问题
问题:OOM(显存不足)
-
7B模型优化:
from vllm import LLM llm = LLM( model="deepseek-7b", enable_prefix_caching=True, block_size=32 # 降低内存碎片 ) -
33B模型优化:
llm = LLM( model="deepseek-33b", tensor_parallel_size=4, swap_space=64 # 启用CPU offload )
3.3 模型加载异常
问题:权重形状不匹配
- 典型错误:
RuntimeError: shape mismatch [4096, 5120] vs [5120, 4096] - 原因:模型版本与加载配置不匹配
- 解决方案:
# 指定正确的hidden_size和num_heads llm = LLM( model="deepseek-14b", model_config={ "hidden_size": 5120, "num_attention_heads": 40 } )
4. 各参数版本特殊问题解析
4.1 7B版本高频问题
问题:低显存利用率
- 优化方案:
# 启用连续批处理 llm = LLM( model="deepseek-7b", max_num_seqs=256, max_seq_length=4096 ) # 设置并行度 export VLLM_USE_MODELSCOPE=1
4.3 33B/65B大模型部署
关键配置:
# 多卡并行配置
llm = LLM(
model="deepseek-32b",
tensor_parallel_size=4,
worker_use_ray=True,
gpu_memory_utilization=0.92
)
# NCCL调优
export NCCL_ALGO=Tree
export NCCL_SOCKET_IFNAME=eth0
5. 高级调试技巧
5.1 内存泄漏排查
# 启用内存分析
from vllm.utils import memory_utils
with memory_utils.trace_memory():
llm.generate(...)
# 输出显存事件日志
vllm.engine.arg_utils.DEBUG_MEMORY = True
5.3 自定义Kernel优化
// 示例:优化LayerNorm kernel
__global__ void layer_norm_kernel(
half* output,
const half* input,
const half* gamma,
...) {
// 自定义实现...
}
6. 附录
6.1 常用vLLM参数速查表
| 参数 | 7B推荐值 | 32B推荐值 |
|---|---|---|
| max_num_seqs | 256 | 128 |
| block_size | 32 | 64 |
| gpu_memory_utilization | 0.85 | 0.92 |
总结:
部署DeepSeek系列模型时需注意:
- 严格匹配模型版本与配置参数
- 根据模型规模选择并行策略
- 合理设置显存利用率参数
- 使用vLLM原生监控工具进行性能分析
建议部署前通过基准测试验证配置:
python -m vllm.entrypoints.benchmark \
--model deepseek-7b \
--dataset lmsys/human-eval \
--quantization awq
持续关注vLLM GitHub仓库的更新(https://github.com/vllm-project/vllm),及时获取最新优化策略。
本文档将持续更新,建议收藏GitHub仓库获取最新版本:
https://github.com/yourusername/deepseek-vllm-guide
粉丝福利
👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击文末名片获取更多信息。我是猫头虎,期待与您的交流! 🦉💬
🌐 第一板块:
- 链接:[直达链接]https://zhaimengpt1.kimi.asia/list

💳 第二板块:最稳定的AI全平台可支持平台
- 链接:[粉丝直达链接]https://bewildcard.com/?code=CHATVIP


联系我与版权声明 📩
- 联系方式:
- 微信: Libin9iOak
- 公众号: 猫头虎技术团队
- 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击✨⬇️下方名片⬇️✨,加入猫头虎AI共创社群,交流AI新时代变现的无限可能。一起探索科技的未来,共同成长。🚀



















 6080
6080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











