







概述
当我们观察周围的世界时,我们会很自然地对所看到的事物进行组织、分组、区别和划分,以便帮助我们更好地了解周围的一切;这类心理分类过程是学习和理解的基础。同样,为了帮助您了解以及更好地理解数据,您可以使用空间约束多元聚类工具。给定要创建的聚类数,它将寻找一个能够使每个聚类中的所有要素都尽可能相似但各个聚类之间尽可能不同的解。要素相似性是基于您为分析字段参数指定的一组特性,同时还可以包括对于聚类大小的约束。该算法使用的算法采用连通图(最小跨度树)和一种被称为 SKATER 的方法来查找数据中存在的自然聚类以及证据累积以评估聚类从属度似然法。
虽然存在数百个类似这样的聚类分析算法,但它们都被归类为 NP-hard 问题。这意味着要确保某个解能够完美地实现组内相似性和聚类间差异最大化,唯一方法就是对要聚类的要素的每一种可能组合都进行尝试。虽然这对于少量的要素是可行的,但对于问题来说,会很快变得非常棘手。
不但确保找到最佳解非常困难,而且尝试找到一种最适合所有可能数据情景的聚类算法也不现实。各个聚类包含的形状、大小和密度各不相同;属性数据可能包括各种范围、对称性、连续性和测量单位。这就是过去 50 年来开发了如此众多不同聚类分析算法的原因。因此,将空间约束多元聚类视为一种可帮助您更好地了解数据基本结构的探索性工具比较合适。
应用
如果您收集了有关动物观察方面的数据,以便更好地了解它们的领地,空间约束多元聚类工具可能很有帮助。例如,了解鲑鱼在不同生命阶段的聚集地点和时间,可以帮助您规划保护区,以帮助确保成功繁育。
作为一名农学家,您可能想将研究领域内的不同土壤进行分类。对通过一系列样本发现的土壤特征使用空间约束多元聚类可以帮助识别出明显的、空间上相邻的土壤类型的聚类。
按购买方式、人口统计特征和旅行方式对客户进行聚类,可以帮助您为公司产品制订有效的营销策略。
城市规则师常常需要将各个城市划分成不同的邻域,以便有效地定位公共设施、促进地方能动性并提高社区参与度。对城市街区的物理和人口统计特征使用空间约束多元聚类,可以帮助规划师确定具有相似物理和人口统计特征并且在空间上相邻的城市区域。
每当对聚合的数据进行分析时,生态谬误都是一个众所周知的统计推断问题。通常,用于分析的聚合方案对您想要分析的内容没有任何关系。例如,人口普查数据是根据人口分布而聚合,而人口分布情况可能不是用来进行火灾分析的最佳选择。针对与目前分析问题准确相关的一组属性,将可能的最小聚合单位划分成同质区域,是降低聚合偏差和避免生态谬误的一种有效方法。
聚类大小约束
可通过聚类大小约束参数管理聚类的大小。可以设置每个聚类必须满足的最大或最小阈值。大小约束可以是每个聚类所包含的要素数量,也可以是属性值的总和。例如,如果根据一组经济变量对美国各县进行聚类,则可以指定每个聚类的最小人口数为 500 万,最大人口数为 2500 万。或者,可指定每个聚类都必须至少包含 30 个县。
在指定每个聚类的最大值约束时,该算法将以单个聚类开始,并对空间上相邻和具有相似值的聚类进行分割。考虑到每次分割时的所有变量,将会创建新聚类,直到所有聚类大小都低于每个聚类的最大值。
SKATER 通过对感兴趣要素具有相似值的数据进行空间分区来形成聚类。聚类大小约束参数可能不会对所有聚类生效。如果定义的聚类大小约束不支持最佳聚类定义就会出现这种情况。
SKATER 还可通过对所有指定分析字段具有相似值的数据进行空间分区来形成聚类。聚类大小约束可能不会对所有聚类生效。如果最大约束和最小约束的设置值彼此相近可能会发生这种情况,基于空间约束构建最小跨度树也可能会引起这种情况的发生。如果发生了这种情况,该工具将完成工作,没有满足特定要求的聚类将在消息窗口中予以报告。
聚类数
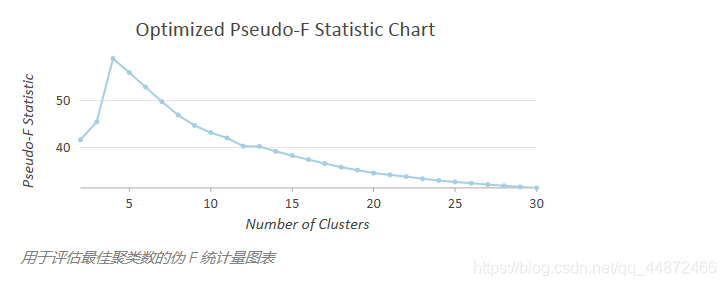
有时,您会知道最适合于您的问题的聚类数。例如,如果您有五位销售经理,并且要为每一位经理指定自己的相邻区域,那么您可以为聚类数参数使用 5。但是,在许多情况下,对于选择具体聚类数您没有任何标准;而只是希望得到一个数,这个数能够最恰当地对要素相似性和差异性进行区分。为帮助您解决这种情形,您可以留空聚类数参数,然后让空间约束多元聚类工具评估将要素分为 2、3、4 和多达 30 个聚类时的有效性。聚类有效性通过 Calinski-Harabasz 伪 F 统计量来测量,它是一个反映聚类间方差和聚类内方差的比率。换言之,是反映组内相似性和组间差异的比率,如下所示:

假设您想要创建四个空间上相邻的聚类。在这种情况下,此工具将创建一个既能反映要素的空间结构又能反映其相关的分析字段值的最小跨度树。然后,将使用此工具确定切割树的最佳位置,以便创建两个单独的聚类。接下来,此工具将决定对生成的两个聚类中的哪个聚类进行划分,以生成三个最佳的聚类解决方案。将划分两个聚类中的其中一个,另一个聚类则保持不变。最后,此工具将决定应对生成的三个聚类中的哪个聚类进行划分,以提供最佳的四个聚类解决方案。对于每个分组,最佳解决方案即为将聚类内相似性和聚类差异性最大化的解决方案。当聚类中所有要素的分析字段值相同时,将不再对该聚类进行划分(随机性除外)。如果生成的所有聚类中具有的要素均相同,那么即使没达到您所指定的聚类数值,空间约束多元聚类工具也将停止创建新聚类。当所有分析字段具有相同值时,不存在任何划聚类的依据。
空间约束
空间约束参数可以确保生成的聚类在空间上相邻。可以启用面要素类的邻接选项,来指明仅当要素与聚类中的另一从属度共享某条边(仅邻接边)或共享某条边或某个折点(邻接边拐角)时,才表示这些要素属于同一聚类。但是,如果数据集包括不连续面或根本没有相邻邻域的面的聚类,则面邻接选项并不是很好的选择。
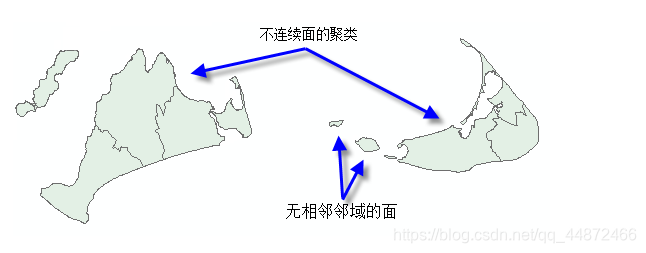
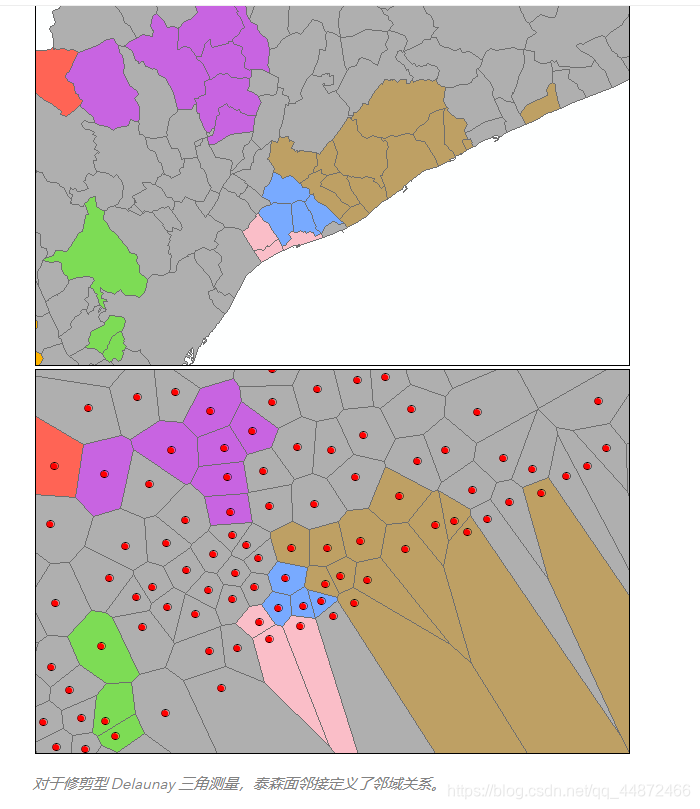
修剪型 Delaunay 三角测量选项适合点或面要素,并确保仅当某个要素至少有一个其他聚类从属度是自然邻域 (Delaunay Triangulation) 时,该要素才能包括在聚类中。从概念上讲,Delaunay 三角测量可以根据要素质心创建不重叠的三角网。每个要素是一个三角形结点,具有公共边的结点被视为邻域。然后将这些三角形剪裁成凸包,以确保要素无法与凸包外的任何要素相邻。此选项不得用于具有重合要素的数据集。另外,由于 Delaunay 三角测量方法会将要素转换为泰森面来确定邻域关系,特别是与面要素的邻域关系,有时是与数据集中外围要素的邻域关系,因此使用此选项所得的结果可能不会始终与您的预期相符。请注意,在下图中,某些分组的原始面不是连续的。然而,当它们转换为泰森多边形时,所有分组的要素实际上都共享边。
最小跨度树
为将聚类从属度限制为相连或相邻要素,工具首先会构造一个表示要素间邻域关系的连通图。连通图上的最小跨度树将汇总要素空间关系和要素数据相似性。要素将成为最小跨度树中通过权重边进行连接的节点。每个边的权重与其连接的对象的相似性成正比。构建最小跨度树后,树中的分支(边)将被剪除,从而生成两个最小跨度树。要剪除的边会被选择,以使生成的聚类中的差异最小化,同时避免(如果可能)单一化(聚类中只具有一个要素)。在每次迭代时,将通过这种剪除过程对其中一个最小跨度树进行分割,直至获得指定的聚类数。所采用的发布方法被称为 SKATER (Spatial "K"luster Analysis by Tree Edge Removal)。虽然在每次迭代时会选择可优化聚类相似性的分支进行剪除,但并不保证最终结果是最佳的。
从属度概率
计算成员关系概率的置换参数可定义置换检验次数以使用证据累积计算聚类成员关系概率。从属度概率包含在 PROB 字段的输出要素类中。从属度概率高表明此要素与其所分配到的聚类相似或相邻,您可以确信该要素属于其所分配到的聚类。从属度概率低可能表明此要素与其被 SKATER 算法分配到的聚类差别很大,或当分析字段、聚类大小约束或空间约束参数进行了某些更改,该要素可能包含在其他聚类中。
您指定的置换检验次数定义了为扰乱 SKATER 空间约束而创建的随机跨度树数量。随后该算法将针对为每个随机跨度树指定的聚类数进行求值。置换检验过程使用了由 SKATER 定义的原始聚类,可记录聚类成员在更改跨度树时聚集在一起的频率。易切换聚类的要素由于对跨度树的细微更改而从属度概率小,而不切换聚类的要素从属度概率较大。
对于较大的数据集来说,计算这些概率可能会耗费大量的运行时间。建议您首先进行迭代并为您的分析找到最佳聚类数,然后在随后的运行中计算分析的概率。您也可以通过将并行处理因子环境 设置增加到 50 来提升性能。
最佳做法
虽然倾向于引入尽可能多的分析字段,但对空间约束多元聚类工具而言,最好从单个变量开始构建。较少的分析字段的结果更易于解释。而且,字段较少时,还易于确定哪些变量是最佳辨别因素。
在许多情况下,您可能运行空间约束多元聚类工具多次,才能查找到最佳聚类数、最有效的空间约束以及能够对要素进行最有效聚类的分析字段的组合。
如果工具返回 30 作为聚类的最佳数量,请务必查看 F 统计量图表。选择聚类数与解释 F 统计量图表也是一种艺术,较低的聚类数可能更加适合您的分析。

















 9783
9783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









