







目录
1. 前言
DenseUNet是为生物医学图像分割任务提出的U-Net架构的变体。它旨在通过在卷积层之间加入密集的连接来处理高度复杂和详细的图像。
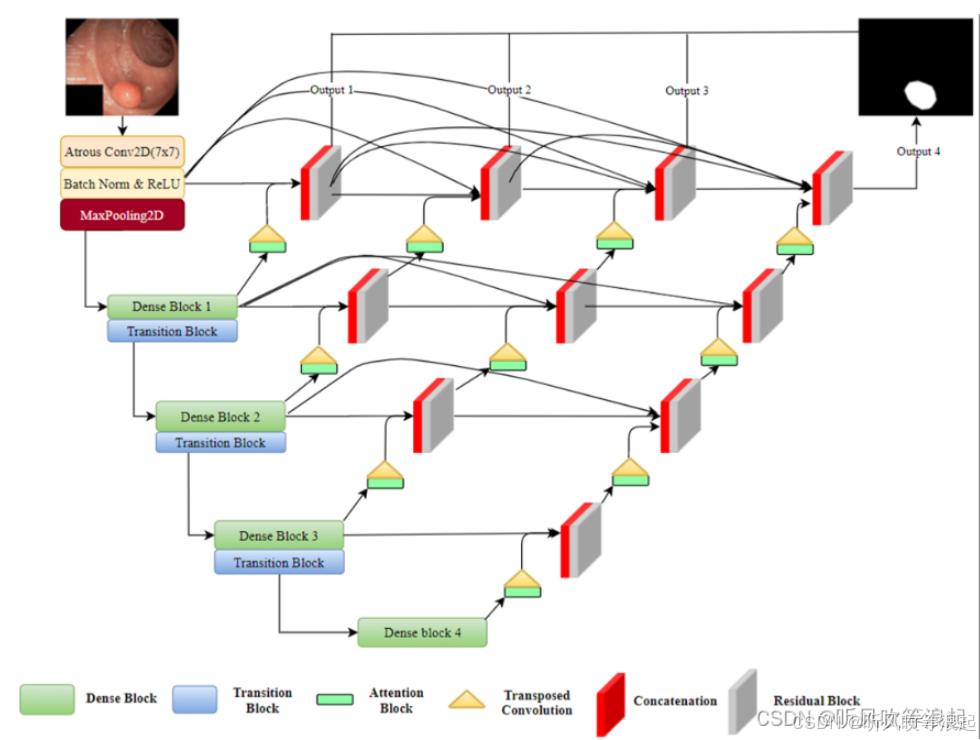
DenseUNet架构由类似于U-Net的编码器-解码器结构组成。然而,它在编码器和解码器的每个阶段都添加了密集的块。密集块是一系列卷积层,其中每一层都接收来自块中所有先前层的输入。这允许重用功能,并促进整个网络中更好的信息流。
DenseUNet中也修改了编码器和解码器之间的跳过连接。DenseUNet没有直接将特征图从编码器连接到相应的解码器级,而是利用了这些特征图之间的密集连接。这有助于在上采样过程中保留更多低级细节。
DenseUNet在各种生物医学图像分割任务中显示出有前景的结果,例如分割器官、肿瘤和细胞。它捕获详细信息和处理复杂图像的能力使其成为医学成像领域的一个有价值的工具。
本章将在绝缘子图像分割的数据集上,实现DenseUnet和Unet的实验对比
2. DenseUnet 和 Unet
其中DenseUnet实现代码如下:
class DenseUNet(nn.Module):
def __init__(self, in_ch=3, out_ch=3):
super(DenseUNet, self).__init__()
densenet = models.densenet161(weights=models.DenseNet161_Weights.IMAGENET1K_V1)
backbone = list(list(densenet.children())[0].children())
if in_ch != 3:
backbone[0] = nn.Conv2d(in_ch, 96, kernel_size=7, stride=2, padding=3, bias=False)
self.conv1 = nn.Sequential(*backbone[:3])
self.mp = backbone[3]
self.denseblock1 = backbone[4]
self.transition1 = backbone[5]
self.denseblock2 = backbone[6]
self.transition2 = backbone[7]
self.denseblock3 = backbone[8]
self.transition3 = backbone[9]
self.denseblock4 = backbone[10]
self.bn = backbone[11]
self.up1 = _Up(x1_ch=2208, x2_ch=2112, out_ch=768)
self.up2 = _Up(x1_ch=768, x2_ch=768, out_ch=384)
self.up3 = _Up(x1_ch=384, x2_ch=384, out_ch=96)
self.up4 = _Up(x1_ch=96, x2_ch=96, out_ch=96)
self.up5 = nn.Sequential(
_Interpolate(),
nn.BatchNorm2d(num_features=96),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=96, out_channels=64, kernel_size=3, padding=1)
)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=out_ch, kernel_size=1)
self.up1_conv = nn.Conv2d(in_channels=768, out_channels=out_ch, kernel_size=1)
self.up2_conv = nn.Conv2d(in_channels=384, out_channels=out_ch, kernel_size=1)
self.up3_conv = nn.Conv2d(in_channels=96, out_channels=out_ch, kernel_size=1)
self.up4_conv = nn.Conv2d(in_channels=96, out_channels=out_ch, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
x_ = self.mp(x)
x1 = self.denseblock1(x_)
x1t = self.transition1(x1)
x2 = self.denseblock2(x1t)
x2t = self.transition2(x2)
x3 = self.denseblock3(x2t)
x3t = self.transition3(x3)
x4 = self.denseblock4(x3t)
x4 = self.bn(x4)
x5 = self.up1(x4, x3)
x6 = self.up2(x5, x2)
x7 = self.up3(x6, x1)
x8 = self.up4(x7, x)
feat = self.up5(x8)
cls = self.conv2(feat)
up1_cls = self.up1_conv(x5)
up2_cls = self.up2_conv(x6)
up3_cls = self.up3_conv(x7)
up4_cls = self.up4_conv(x8)
# return {'output': cls, 'up1_cls': up1_cls, 'up2_cls': up2_cls, 'up3_cls': up3_cls, 'up4_cls': up4_cls}
return cls
class _Interpolate(nn.Module):
def __init__(self, scale_factor=2, mode='bilinear', align_corners=True):
super(_Interpolate, self).__init__()
self.scale_factor = scale_factor
self.mode = mode
self.align_corners = align_corners
def forward(self, x):
x = nn.functional.interpolate(x, scale_factor=self.scale_factor, mode=self.mode,
align_corners=self.align_corners)
return x
class _Up(nn.Module):
def __init__(self, x1_ch, x2_ch, out_ch):
super(_Up, self).__init__()
self.up = _Interpolate()
self.conv1x1 = nn.Conv2d(in_channels=x2_ch, out_channels=x1_ch, kernel_size=1)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=x1_ch, out_channels=out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
x1 = self.up(x1)
x2 = self.conv1x1(x2)
x = x1 + x2
x = self.conv(x)
return xUnet 主干网络实现的代码如下:
# 搭建unet 网络
class DoubleConv(nn.Module): # 连续两次卷积
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels), # 用 BN 代替 Dropout
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.double_conv(x)
return x
class Down(nn.Module): # 下采样
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.downsampling = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
x = self.downsampling(x)
return x
class Up(nn.Module): # 上采样
def __init__(self, in_channels, out_channels):
super(Up, self).__init__()
self.upsampling = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) # 转置卷积
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.upsampling(x1)
diffY = torch.tensor([x2.size()[2] - x1.size()[2]]) # 确保任意size的图像输入
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1) # 从channel 通道拼接
x = self.conv(x)
return x
class OutConv(nn.Module): # 最后一个网络的输出
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, num_classes, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module): # unet 网络
def __init__(self, in_channels=3, num_classes=2):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.in_conv = DoubleConv(in_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.out_conv = OutConv(64, num_classes)
def forward(self, x):
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.out_conv(x)
return x
相比较unet,DenseUnet加入了密集的dense模块,可以更加有效的提取图像的高层信息,并且和低维度的信息融合
3. 绝缘子分割
数据集文件如下:
标签采用0 255标注,方便观察

其中,训练集的总数为8900,验证集的总数为900

4. 训练
训练的参数如下:
- ct 如果数据集是医学影像的ct格式,那么会自动进行windowing增强,效果会更好
- model 可以选择DenseUnet或者unet
- base size是预处理的图像大小,也就是输入model的图像尺寸
- batch size 批大小,epoch 训练轮次,lr 是cos衰减的起始值,lrf是衰减倍率,这里lr最终大小是0.01 * 0.001
- results 是训练生成的主目录
parser.add_argument("--ct", default=False,type=bool,help='is CT?') # Ct --> True
parser.add_argument("--model", default='denseUnet',help='denseUnet,Unet')
parser.add_argument("--base-size",default=(256,256),type=tuple) # 根据图像大小更改
parser.add_argument("--batch-size", default=8, type=int)
parser.add_argument("--epochs", default=50, type=int)
parser.add_argument('--lr', default=0.01, type=float)
parser.add_argument('--lrf',default=0.001,type=float) # 最终学习率 = lr * lrf
parser.add_argument("--img_f", default='.jpg', type=str) # 数据图像的后缀
parser.add_argument("--mask_f", default='.png', type=str) # mask图像的后缀
parser.add_argument("--results", default='runs', type=str) # 保存目录
parser.add_argument("--data-train", default='./data/train/images', type=str)
parser.add_argument("--data-val", default='./data/val/images', type=str)这里跑了30个epoch,效果如下
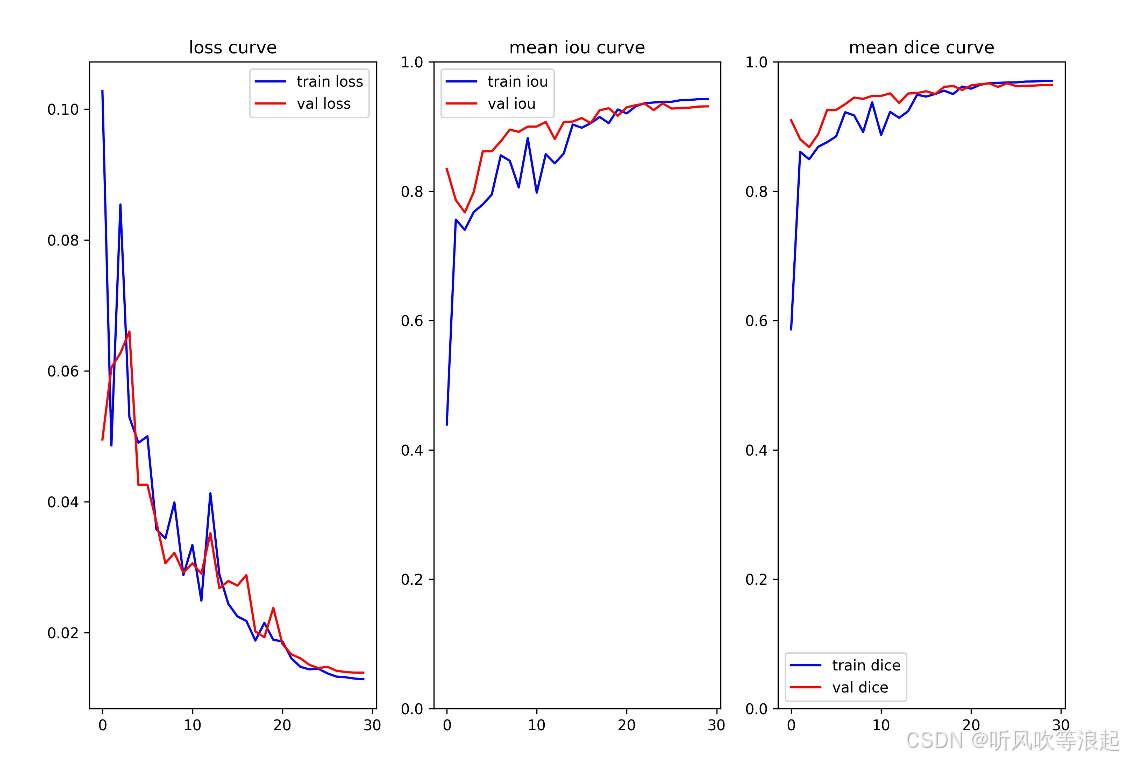
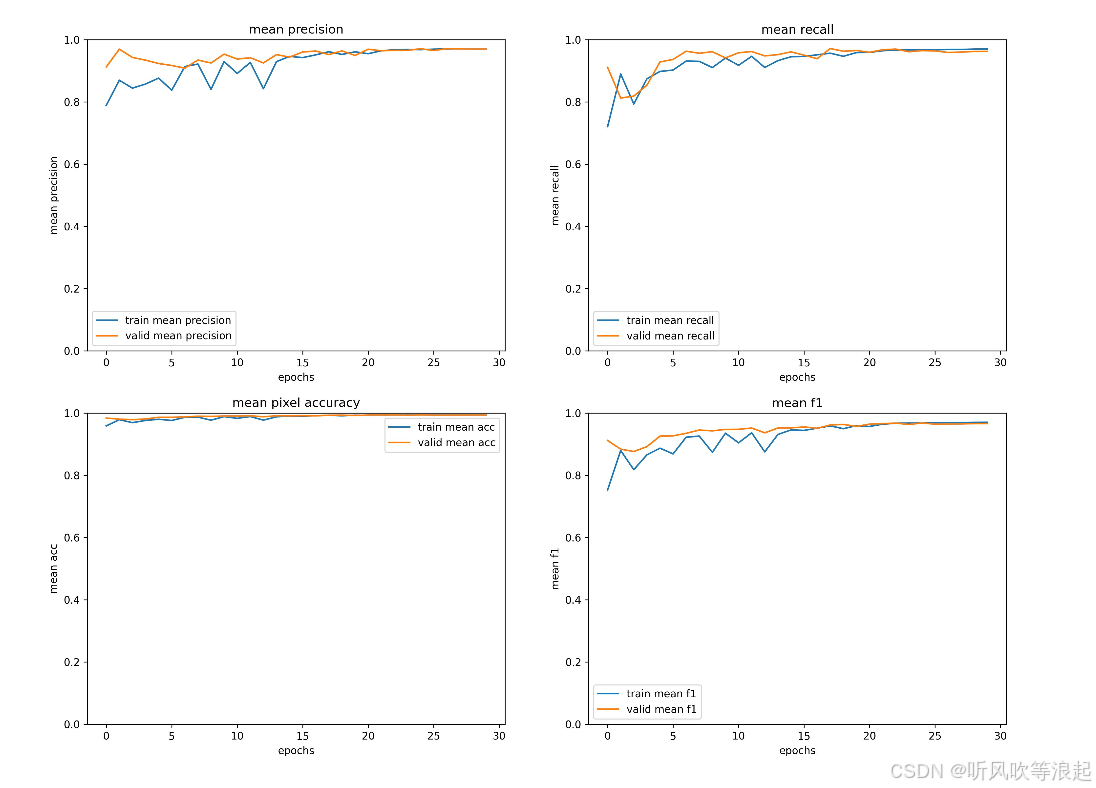
训练日志如下:
"epoch:29": {
"train log:": {
"info": {
"pixel accuracy": [
0.9948181509971619
],
"Precision": [
"0.9706"
],
"Recall": [
"0.9700"
],
"F1 score": [
"0.9703"
],
"Dice": [
"0.9703"
],
"IoU": [
"0.9423"
],
"mean precision": 0.9705663323402405,
"mean recall": 0.9700431823730469,
"mean f1 score": 0.9703047275543213,
"mean dice": 0.9703046679496765,
"mean iou": 0.9423220753669739
}
},
"val log:": {
"info": {
"pixel accuracy": [
0.9938134551048279
],
"Precision": [
"0.9700"
],
"Recall": [
"0.9624"
],
"F1 score": [
"0.9662"
],
"Dice": [
"0.9662"
],
"IoU": [
"0.9346"
],
"mean precision": 0.9699863791465759,
"mean recall": 0.9623918533325195,
"mean f1 score": 0.9661741256713867,
"mean dice": 0.9661741852760315,
"mean iou": 0.9345618486404419
}
}5. 推理
推理是指没有gt的,这里测试结果如下:


掩膜效果为:

6. 项目下载
关于本项目代码和数据集、训练结果的下载:基于DenseUnet和Unet实现的语义分割对比项目:高压线绝缘子图像语义分割资源-CSDN文库
更换数据集进行训练的话,参考readme文件,pip requirements文件就行了



















 9016
9016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











