






好多博客都只说简单shuffer与随机种子,没有说清楚他们具体作用,这次我来具体说说。
DataLoader用于加载数据到模型中
在pytorch 中的数据加载到模型的操作顺序是这样的:
① 创建一个 Dataset 对象 (自己去实现以下这个类,内部使用yeild返回一组数据数据)
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练
DataLoader中的shuffer=False表示不打乱数据的顺序,然后以batch为单位从头到尾按顺序取用数据。
DataLoader中的shuffer=Ture表示在每一次epoch中都打乱所有数据的顺序,然后以batch为单位从头到尾按顺序取用数据。这样的结果就是不同epoch中的数据都是乱序的。
在训练网络时,同样的结构与数据,但是训练后结果每次都不同,有时结果相差还很大,这就很苦恼,复现不了以前的结果,这除了和模型的参数随机初始化有关,还有一点点原因是因为你这一次训练是与你上一次训练的数据乱得不一样。
设置随机种子的作用就是让你的每一次训练都乱的一样,即可以让你在单次训练内部数据保持乱序但不同训练之间都是一样的乱序。
有图有真相,下面请看:
代码部分参考自:简单测试一下pytorch dataloader里的shuffle=True是如何工作的
import numpy as np
from torch.utils.data import TensorDataset, DataLoader, Dataset
import torch
#定义一个dataset
class DealDataset(Dataset):
def __init__(self):
xy = np.loadtxt(open('./5555.csv', 'rb'), delimiter=',', dtype=np.float32)
# data = pd.read_csv("iris.csv",header=None)
# xy = data.values
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
#创建一个dataset对象
dealDataset = DealDataset()
这是建的一些简单的数据,用于loder:
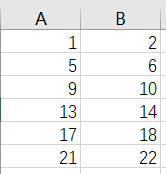
设置shuffle=False
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=2,
shuffle=False)
for epoch in range(3):
for i, data in enumerate(train_loader2):
inputs, labels = data
# inputs, labels = Variable(inputs), Variable(labels)
print(inputs)
# print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
print("----------epoch分割线-----------------------")
结果:

设置shuffle=Ture


设置shuffle=Ture并设置随机种子
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=2,
shuffle=True)
# print(dealDataset.x_data)
#为CPU中设置种子,生成随机数
#======设置随机种子==============
seed=10
torch.manual_seed(seed)
for epoch in range(3):
for i, data in enumerate(train_loader2):
inputs, labels = data
# inputs, labels = Variable(inputs), Variable(labels)
print(inputs)
# print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
print("----------epoch分割线-----------------------")


另外,参考自别的博客,使用下面的代码应该就可以在每一次训练时固定住模型的一些随机的东西了吧(事实上,我使用了下面的代码以后,实验结果依旧不稳定):
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed) #为CPU设置种子用于生成随机数,以使得结果是确定的
torch.cuda.manual_seed(args.seed) #为当前GPU设置随机种子;
torch.backends.cudnn.deterministic = True

















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









