






一、数据预处理
1 数据加载
1.1 标签在文件夹上的数据集加载
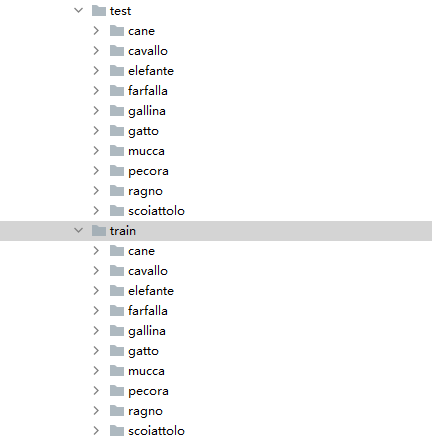
所有文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名
使用ImageFolder数据加载器
参数详解
dataset=torchvision.datasets.ImageFolder(root, transform=None,target_transform=None,loader=,is_valid_file=None)
- root:图片存储的根目录,即各类别文件夹所在目录的上一级目录。
- transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。
- target_transform:对label的转换(对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…)
- loader:表示数据集加载方式,通常默认加载方式即可。
- is_valid_file:获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
返回值
- self.classes:用一个 list 保存类别名称
- self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应
- self.imgs:保存(img-path, class) tuple的 list
注意
ImageFolder() 读取指定文件夹下的所有文件的索引,imageFolder()过程只会加载index,而不会执行transform操作(transform操作是懒加载的,只有使用dataLoader的时候才会执行
执行操作:
- 扫描目录:它会递归遍历指定的根目录,查找所有符合条件的图像文件。这个过程中,它会按照目录结构将找到的图像自动分类,目录名被用作类别标签。
- 建立索引:对于每个找到的图像文件,ImageFolder 会创建一个包含图像路径和其对应标签索引的元组。这些信息被存储在一个内部列表中,用于后续的数据加载。
十分类文件夹
- classes+class_to_idx

输出如下:

- imgs 返回所有文件夹中得到的图片的路径及其类别

输出如下:

- 返回第一个元素,结构是(img_data,class_id)

输出如下:

1.2 标签在文件名中的数据集加载
所有数据混在一个文件夹中,文件名即是标签
1.3 数据集划分训练集和验证集的方法
主要针对的是标签在图片名上的加载方式
1.4 读取csv文件的数据集加载方法
2 数据处理
PIL库读取的图片格式为HxWxC,而图片的张量形式为CxHxW
因此,需要将数组转置,用到transpose
图片到tensor:img=np.array(img).transpose(2,0,1)
tensor到图片:img = img.numpy().transpose(1,2,0)
2.1 数据增广
何为增广:对现有数据进行一些图形学或者几何学上的图像变换
在线增广
在模型训练过程中一边训练一边对数据进行增广,这种方法优点是不需要将增广的数据合成出来,因此节省了数据的存储空间,具有很高的灵活性,并且理论上来说训练过程中的数据量是无限的,但是这也可能导致一个问题每个epoch训练的图像都是不一样的,在进行分类或者其他对数据变化要求不太高的任务时这种方法能取得很好的效果,但是在进行如文字识别等对数据变化要求很高的任务时可能不会取得太好的提升,尤其是当数据增广后图像变化很大的情况下模型甚至无法很好的收敛,这种情况下可以尝试离线增广或者在做增广的时候提高使用原图像的概率。
离线增广
在进行模型训练之前就对数据进行增广并生成图像,这种方法的优点是增广的数据可视化,使得开发者能够控制好增广数据的效果,由于离线增广的数据往往都是有限的因此可以很好的评价数据增广对模型性能的提升,但是缺点是需要将增广数据生成出来因此占用更多的存储空间并且灵活性差。
2.2 数据扩充
3 自定义数据集加载
3.1 前言
from torch.utils.data import Dataset
from torchvision import datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
1、Dataset 在 torch.utils.data 无论是加载文本还是图像数据集,加载自定义数据集都需要他。官方提供的dataset则从torchvision里import。
2、DataLoader 在torch.utils.data 不管是文本还是图片都用这个包。
3、 对图像的预处理 用torchvision.transforms 包
3.2 数据预处理部分
- 数据增强:torchvision中transforms模块自带功能,比较实用
- 数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid': transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
3.3 图像数据集加载部分
- 几种数据集加载的方法区别本质在于文件里的内容,标签的位置之类的。
- 想让PyTorch能读取我们自己的数据,首先要了解pytroch读取图片的机制和流程,然后按流程编写代码。
3.4 自定义DataSet加载
PyTorch读取图片,主要是通过Dataset类,所以先简单了解一下Dataset类。Dataset类作为所有的datasets的基类存在,所有的datasets都需要继承它,类似于C++中的虚基类。
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
要让PyTorch能读取自己的数据集,只需要两步:
- 制作图片数据的索引
- 构建Dataset子类
然而,如何制作这个list呢,通常的方法是将图片的路径和标签信息存储在一个txt中,然后从该txt中读取。
整个读取自己数据的基本流程就是:
- 制作存储了图片的路径和标签信息的txt
- 将这些信息转化为list,该list每一个元素对应一个样本
- 通过getitem函数,读取数据和标签,并返回数据和标签。
首先制作图片数据的索引
就是读取图片路径,标签,保存到txt文件中。
- 一堆相同类别的图片已经在一个文件夹下了,可以用下面这种方法产生一个txt文件。
参考:如何用python生成带图片名称和标签的.txt文件(代码) - 标签和图片标号都在csv文件里,可以用以下方法。
pytorch 自定义数据集载入(标签在csv文件里)(代码)
然后构建Dataset子类
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
# 初始化数据集的存储路径
# 载入数据集,转化为tensor格式
fh = open(txt_path, 'r') #读取 制作好的txt文件的 图片路径和标签到imgs里
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
# 返回单个样本及其标签
fn, label = self.imgs[index] #self.imgs是一个list,self.imgs的一个元素是一个str,包含图片路径,图片标签,这些信息是在init函数中从txt文件中读取的
# fn是一个图片路径
img = Image.open(fn).convert('RGB') #利用Image.open对图片进行读取,img类型为 Image ,mode=‘RGB’
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
# 返回整个数据集大小
return len(self.imgs)
- 注意到Dataset类里的初始化中还会初始化transform,transform是一个Compose类型,里边有一个list,list中就会定义了各种对图像进行处理的操作,可以设置减均值,除标准差,随机裁剪,旋转,翻转,仿射变换等操作。
- 在这里我们要知道,一张图片读取进来之后,会经过数据处理(数据增强),最终变成模型的输入数据。这里就有一点需要注意,PyTorch的数据增强是将原始图片进行了处理,并不会生成新的一份图片,而是“覆盖”原图,当采用randomcrop之类的随机操作时,每个epoch输入进来的图片几乎不会是一模一样的,这达到了样本多样性的功能。
最后DataLoader加载即可
- 当自定义Dataset构建好,剩下的操作就交给DataLoader了。在DataLoader中,会触发Mydataset中的getiterm函数读取一个batch大小的图片的数据和标签,并返回,(清晰的底层逻辑见该博客)作为模型真正的输入。
- 最后像下面这样,处理好了前面说的两步之后,得到data,交给DataLoader就很简单了。
train_data = MyDataset(txt='../gender/train1.txt',type = "train", transform=transform_train)
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=batch_size,
sampler=train_sampler)
二、模型构建
SE-ResNet
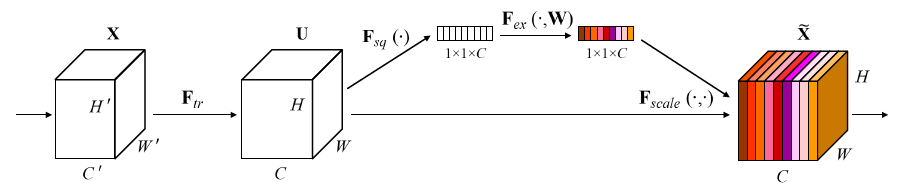
SE:Squeeze and Excitation 压缩(全局信息嵌入)激励(自适应重新校准)
选择性地强调信息特征和抑制无用的特征
SE块,其目标是通过显示建模卷积特征通道之间的相互依赖来提高网络产生的表征的质量(相当于对特征提纯,使得特征表达能力更强)
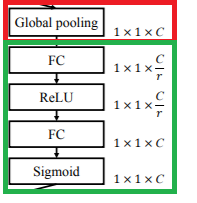
1、Squeeze操作
使用通道的全局平均池化,将包含全局信息的W×H×C 的特征图直接压缩成一个1×1×C的特征向量,即将每个二维通道变成一个具有全局感受野的数值,此时1个像素表示1个通道,屏蔽掉空间上的分布信息,更好的利用通道间的相关性。
2、Excitation操作
目的:为了利用在"squeeze"操作中聚合的信息,接着进行Excitation操作,来完全捕获通道依赖关系
方法:为实现上述目标,函数必须符合两个标准:
(1)灵活性:它必须能够学习通道之间的非线性相互作用
(2)必须学习一种非互斥关系:因为我们希望确保允许强调多个通道不同重要程度(而不是强制一个one-hot激活)。因为我们不光要学习特征,还要学习通道之间信息的相关性。
为了满足这两个条件,这篇论文这里采用两个全连接层+两个激活函数组成的结构输出和输入特征同样数目的权重值,也就是每个特征通道的权重系数。
基于特征通道间的相关性,每个特征通道生成一个权重,用来代表特征通道的重要程度。由原本全为白色的C个通道的特征,得到带有不同深浅程度的颜色的特征向量,也就是不同的重要程度。
- 第一个FC层:ReLU
- 第二个FC层:Sigmoid
Q1:加入全连接层的作用?
这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。
Q2:为什么加两个全连接层?
应该是类似bottleneck的设计,增加非线性(model capacity),减少参数和运算量,不压缩的话这块儿的参数量和运算量会多r^2倍,比如1024个特征到1024个特征,直接全连接运算量是1024×1024,如果中间插入一个256层,那么它的运算量是1024×256×2,运算量降低了一半。
Q3:为什么前面用ReLU激活,后面为什么要改用Sigmoid呢?
(1)具有更多的非线性:可以更好地拟合通道间复杂的相关性。
(2)极大地减少了参数量和计算量:降维参数 r 用于控制第一个FC层中的神经元个数,在论文中也是经过多次对比实验得出r=16 时,模型得到的效果是最好的。
(3)由于Sigmoid函数图像的特点,它的值域在0—1之间,那么这样很符合概率分布的特点,最后能够获得 在0—1 之间归一化的权重参数,这样的话再通过乘法逐通道加权到先前的特征图上,使得有用的信息的注意力更趋向于1,而没有用的信息则更趋向于0,得到最后带有注意力权重的特征图。
SE块可以即插即用
-
首先由 Inception结构 或 ResNet结构处理后的C×W×H特征图开始,通过Squeeze操作对特征图进行全局平均池化(GAP),得到1×1×C 的特征向量
-
紧接着两个 FC 层组成一个 Bottleneck 结构去建模通道间的相关性:
- 经过第一个FC层,将C个通道变成 C/ r ,减少参数量,然后通过ReLU的非线性激活,到达第二个FC层
- 经过第二个FC层,再将特征通道数恢复到C个,得到带有注意力机制的权重参数
-
最后经过Sigmoid激活函数,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
结合
下图是SE-ResNet, 可以看到SE module被apply到了residual branch上。
- 首先将特征维度降低到输入的1/r,
- 然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。这样做比直接用一个Fully Connected层的好处在于:
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得01之间归一化的权重, - 最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。在Addition前对分支上Residual的特征进行了特征重标定。
如果对Addition后主支上的特征进行重标定,由于在主干上存在01的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
中心思想:对于每个输出channel,预测一个常数权重,对每个channel加权一下。
对于每一输出通道,先global average pool,每个通道得到1个标量,C个通道得到C个数,然后经过FC-ReLU-FC-Sigmoid得到C个0到1之间的标量,作为通道的权重,然后原来的输出通道每个通道用对应的权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征,作者称之为feature recalibration。
第一步每个通道HxW个数全局平均池化得到一个标量,称之为Squeeze,然后两个FC得到01之间的一个权重值,对原始的每个HxW的每个元素乘以对应通道的权重,得到新的feature map,称之为Excitation。

三、训练模型
目标函数(损失函数)
优化算法
目的:搜索出最佳参数,以最小化损失函数
SGD
Adam
Adamw
四、测试模型
实验结果
resnet18
1、lr=5e-4 batch_size=16 epoch=120
1)不扩充不分类
********** best_test **********
epoch: 111
train_loss: 0.008756421879465086
train_acc: 0.9543448686599731
test_loss: 0.034533544455740625
test_acc: 0.8472222089767456
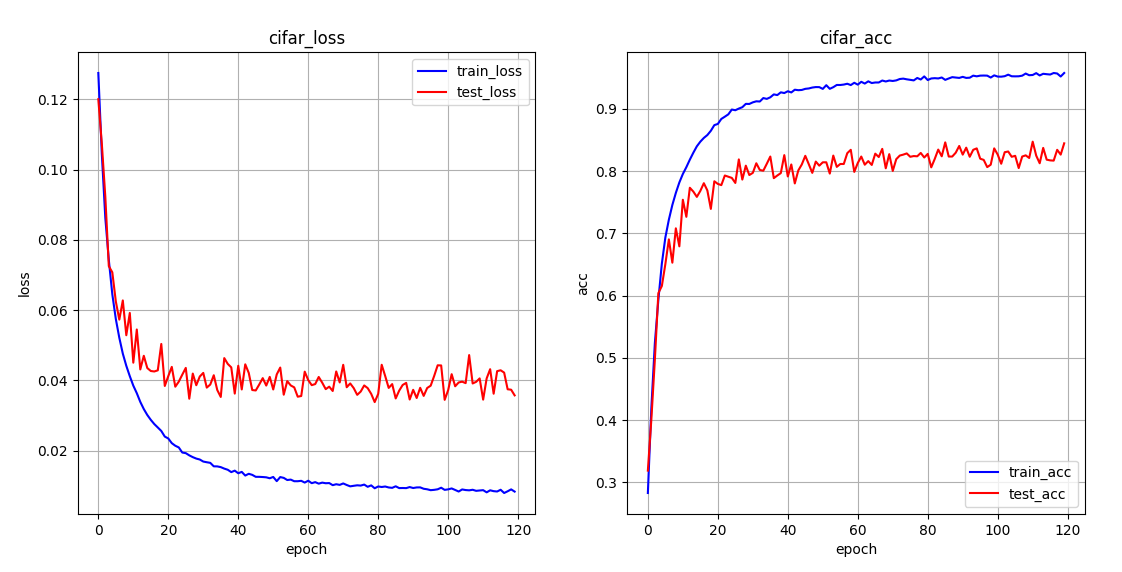
se-resnet18 与 resnet18
lr=0.00003 学习率动态调整
se-resnet
resnet
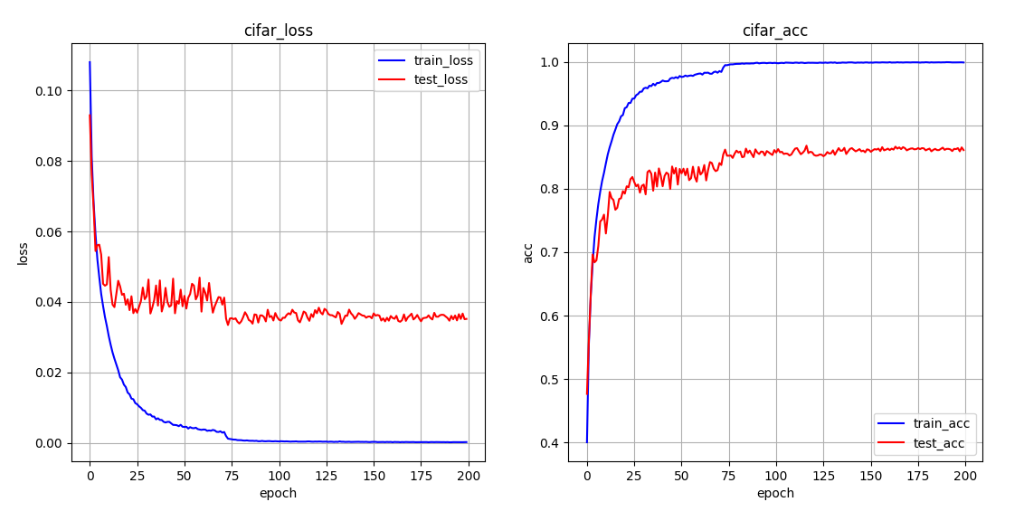
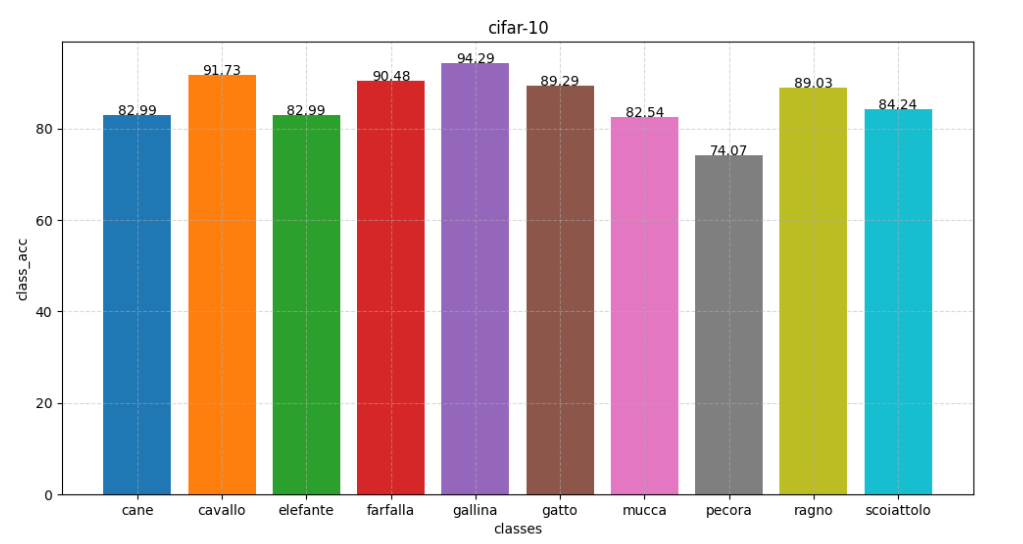
se-resnet34 扩充 与 se-resnet18 扩充
lr=3e-4 图像旋转(-20,20)
se-resnet18 90
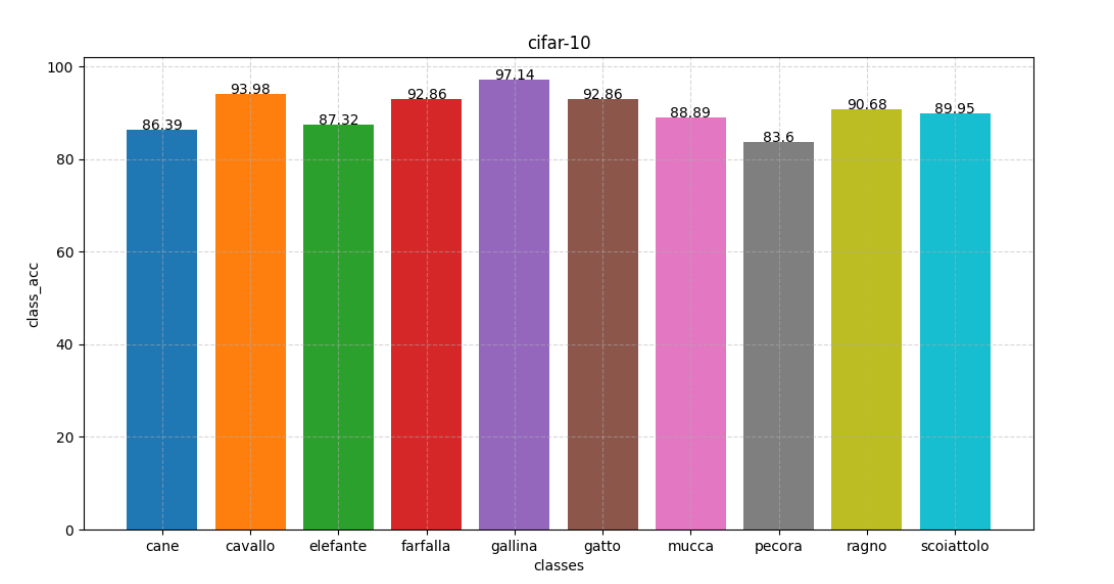
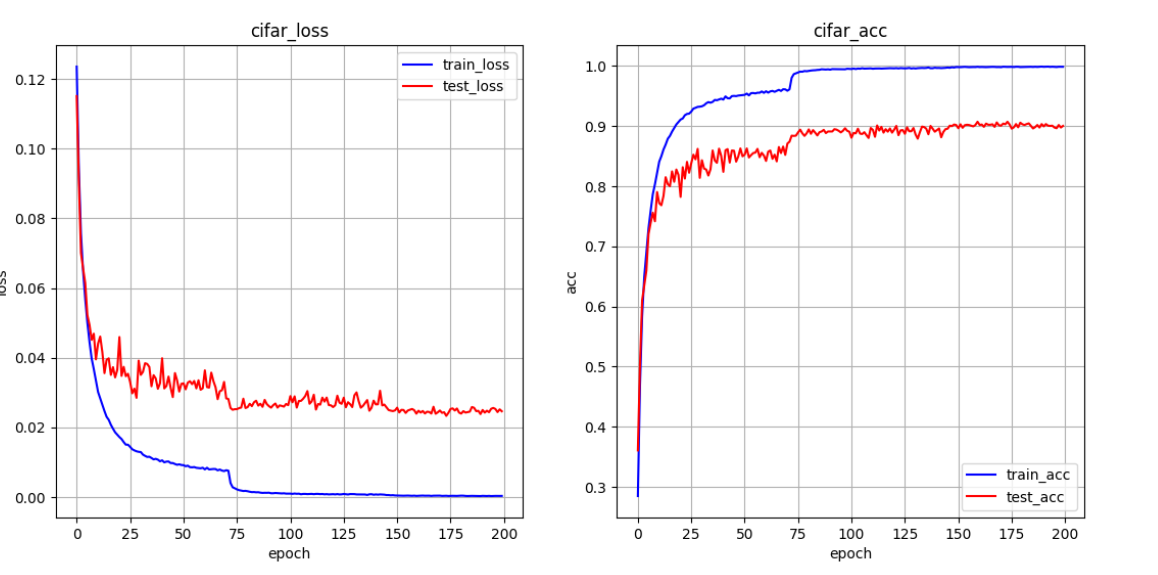
se-resnet34 91
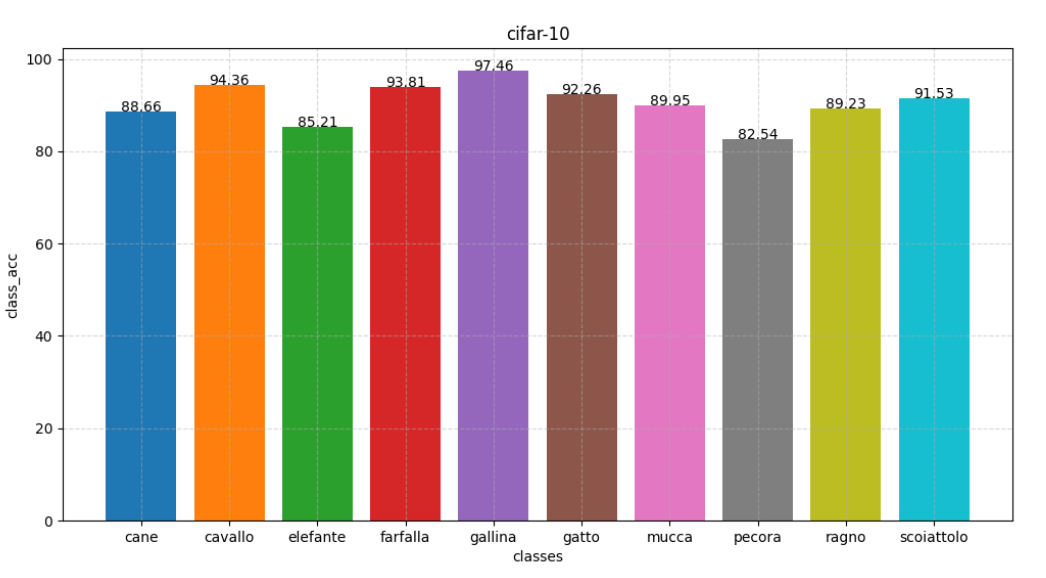
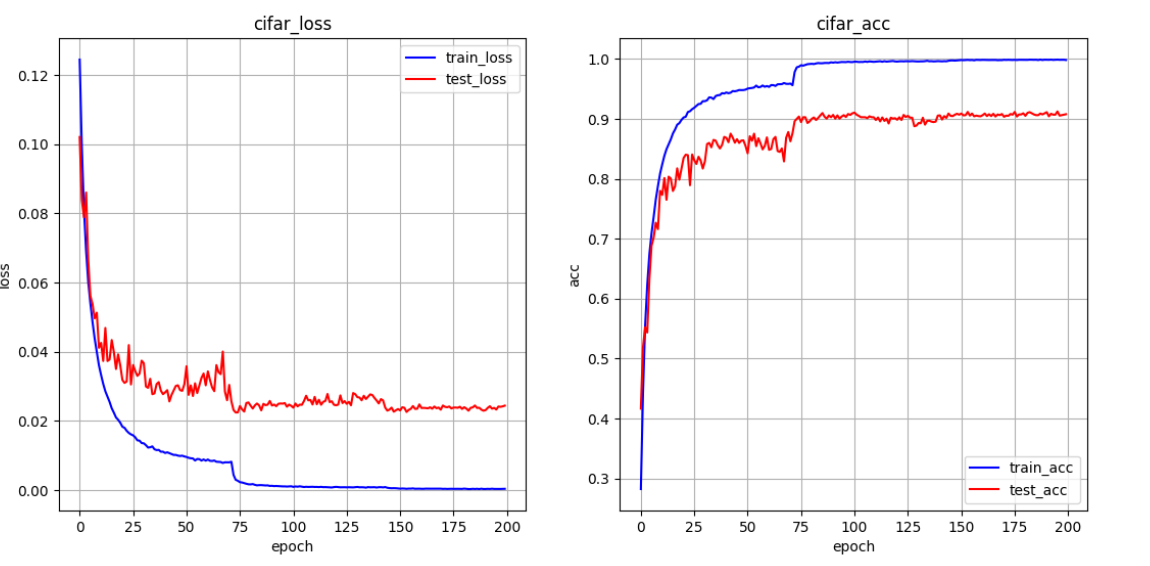
五、提升精度
5.1 基础模型
5.2 数据增强
目的:缓解过拟合
方法:
- 图像旋转
- 图像裁剪
- 改变图像色差
- 改变图像大小
- 增强图像噪音(高斯噪声,椒盐噪声)
- 图像标准化
5.3 模型改进
- 注意力机制:所谓Attention机制,便是聚焦于局部信息的机制,让模型更加专注于这一局部信息进行训练,比如,图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。
- Dropout:深度学习中最常用的正则化技术是dropout,让一部分的神经元不参加训练,简而言之就是随机的丢掉一些神经元。这样可以防止过拟合,提高模型的泛化能力。
- LRN:即局部响应归一化层,LRN函数类似Dropout和数据增强作为relu激活函数之后防止数据过拟合而提出的一种处理方法。这个函数很少使用,基本上被类似Dropout这样的方法取代。
- 正则化:对于目标函数加入正则化项,限制权重参数的个数,这是一种防止过拟合的方法,这个方法其实就是机器学习中的 l2 正则化方法。
5.4 模型深度
5.5 特征融合
六、整体代码
实现时选用resnet18+SE模块
6.1 自定义数据集加载
self_load.py
"""
自定义dataset加载
数据增广
数据扩充
多分类增广
"""
import os
import torch
import torchvision
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms, utils, datasets
from torchvision.datasets import ImageFolder
from config import batch_size, data_dir
from PIL import Image
import random
import numpy as np
import matplotlib.pyplot as plt
# 过滤警告信息
import warnings
warnings.filterwarnings("ignore")
"""
综上所述,自定义dataset
"""
# 数据集文件夹
# data_dir = '/data/DL_DATA/classify_ten_data/'
class LoadData(Dataset):
def __init__(self, data_dir, transform=None, is_train=False, Extend_data=False, Separate_aug=False):
# 初始化数据集的存储路径
# 载入数据集,转化为tensor格式
super(LoadData, self).__init__()
self.root_dir = data_dir
self.transform = transform
self.is_train = is_train
# self.images_info = self.get_data(self.root_dir) # path+label
self.extend_data = Extend_data
self.separate_aug = Separate_aug
self.classes = ['cane', 'cavallo', 'elefante', 'farfalla', 'gallina', 'gatto', 'mucca', 'pecora', 'ragno',
'scoiattolo']
if self.extend_data is False:
self.images_info = self.get_data(self.root_dir) # path+label
print('extend_data=',self.extend_data)
else:
self.images_info = self.data_extender(self.get_data(self.root_dir)) # path+label
print('extend_data=', self.extend_data)
# 训练集图像预处理
self.transform_train = transforms.Compose([
transforms.Resize(300),
transforms.RandomSizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])
])
# 测试集图像预处理,只对图形执行标准化,以消除评估结果中的随机性
self.transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(), # 将图片转化为张量tensor,并使图片的形式表现为通道x高x宽的形式
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])
])
def get_data(self, root_dir):
"""
:return:
"""
images = []
if self.is_train:
root_dir = root_dir + 'train'
else:
root_dir += 'test'
for item in os.listdir(root_dir):
# 分类路径
class_path = root_dir + '/' + item
for data in os.listdir(class_path):
# 图像路径
data_path = class_path + '/' + data
images.append((data_path, self.classes.index(item)))
return images
def data_extender(self, img_info):
"""
数据扩充
:return:
"""
# 获取所有类别中最多的图片数量
class_num = []
for i in range(len(self.classes)):
count = 0
for path, label in img_info:
if label == i:
count += 1
class_num.append(count)
max_num = max(class_num)
# 测试最大值
# print(max_num)
images_exd = img_info.copy()
for i in range(len(class_num)):
# 获取当前样本的路径列表
class_sample = [(path, label) for path, label in img_info if label == i]
# 计算当前类别的样本数量
current_count = len(class_sample)
# print(self.classes[i], current_count)
# 计算需要增加的数量
aug_count = max_num - current_count
# print(aug_count)
# 从当前样本中随机选择并复制进行增广
aug_sample = random.choices(class_sample, k=aug_count)
# 将扩充的样本添加到训练集中
images_exd += aug_sample
# print(len(images_exd))
return images_exd
def class_aug(self, label):
"""
单类增广
:return:
"""
specific_transforms = {
0: transforms.Compose([
transforms.Resize(300),
# transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.2),
# transforms.RandomAffine(degrees=25, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
# transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
# transforms.RandomRotation((-20, 20)),
transforms.RandomResizedCrop((224, 224), scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.2)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5314, 0.5090, 0.4335], std=[0.2758, 0.2724, 0.2852]),
]),
1: transforms.Compose([
transforms.Resize(300),
# transforms.RandomAffine(degrees=8, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
# transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
transforms.RandomResizedCrop((224, 224), scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5032, 0.4925, 0.4115], std=[0.2609, 0.2615, 0.2777]),
]),
2: transforms.Compose([
transforms.Resize(300),
# transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
# transforms.RandomRotation((-20, 20)),
transforms.RandomResizedCrop((224, 224), scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5138, 0.4935, 0.4231], std=[0.2535, 0.2499, 0.2642]),
]),
3: transforms.Compose([
transforms.Resize(300),
# transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.2),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
# transforms.RandomRotation((-20, 20)),
# transforms.RandomAffine(degrees=25, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5094, 0.5089, 0.3924], std=[0.3159, 0.2984, 0.3326]),
]),
4: transforms.Compose([
transforms.Resize(300),
# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.4989, 0.4782, 0.4049], std=[0.2528, 0.2509, 0.2553]),
]),
5: transforms.Compose([
transforms.Resize(300),
# transforms.RandomRotation((-20, 20)),
# transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.2),
# transforms.RandomAffine(degrees=45, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5191, 0.4875, 0.4375], std=[0.2849, 0.2814, 0.2921]),
]),
6: transforms.Compose([
transforms.Resize(300),
transforms.RandomRotation((-5, 5)),
# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.4894, 0.4889, 0.3955], std=[0.2539, 0.2530, 0.2791]),
]),
7: transforms.Compose([
transforms.Resize(400),
transforms.RandomRotation((0, 10)),
# transforms.RandomAffine(degrees=5, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
transforms.RandomSizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
# 随机遮挡
# transforms.RandomErasing(p=0.5),
# 水平翻转
transforms.RandomHorizontalFlip(p=0.5),
# 上下翻转
transforms.RandomVerticalFlip(p=0.5),
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
# 改变颜色 亮度 对比度 饱和度 色调 0.5即随机值为原始图像的1-0.5~1+0.5
# transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
# p=0.5),
# transforms.RandomAffine(degrees=5, translate=(0.1, 0.1), scale=(0.9, 1.1), shear=20),
# transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.4892, 0.4921, 0.3782], std=[0.2386, 0.2317, 0.2482]),
]),
8: transforms.Compose([
transforms.Resize(300),
# transforms.RandomRotation((-20, 20)),
# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.5667, 0.5384, 0.4373], std=[0.2615, 0.2588, 0.2818]),
]),
9: transforms.Compose([
transforms.Resize(300),
# transforms.RandomRotation((-10, 10)),
# transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
transforms.RandomResizedCrop(224, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)],
p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
# transforms.Normalize(mean=[0.4872, 0.4662, 0.3756], std=[0.2424, 0.23805, 0.2526]),
]),
}
for class_id, class_transform in specific_transforms.items():
if class_id == label:
return class_transform
def __getitem__(self, index):
"""
返回数据的信息
:param item:
:return:
"""
# 判断要不要分类增广,是的话默认训练集
if self.separate_aug is False:
# 判断是否训练集
if self.is_train:
trans = self.transform_train
else:
trans = self.transform_test
img_path, label = self.images_info[index]
img = Image.open(img_path).convert('RGB')
if self.transform is not None:
img = self.transform(img)
else:
img = trans(img)
return img, label
else:
img_path, label = self.images_info[index]
img = Image.open(img_path).convert('RGB') # 统一图像的通道数
class_transform = self.class_aug(label)
img = class_transform(img)
return img, label
def __len__(self):
"""
返回数据的个数
:return:
"""
return len(self.images_info)
# 加载训练集
train_ds = LoadData(data_dir, is_train=True, Extend_data=True, Separate_aug=True)
# print(len(train_datasets.samples))
# print(len(train_ds))
# print(type(train_datasets))
# print(train_datasets)
# print(train_datasets.samples[0])
# 为训练集创建DataLoader对象(DataLoader 数据集 每次给网络的数据数量 是否打乱数据 进程数量)
train_ir = DataLoader(train_ds, batch_size=batch_size, shuffle=True, num_workers=8, drop_last=True)
# 加载测试集
test_ds = LoadData(data_dir,is_train=False,Extend_data=False,Separate_aug=False)
# 为测试集创建DataLoader对象
test_ir = DataLoader(test_ds, batch_size=batch_size, shuffle=False, num_workers=8, drop_last=True)
if __name__ == '__main__':
# data_ds = LoadData(data_dir, is_train=True, Extend_data=True, Separate_aug=True)
# for item in data_ds:
# print(item)
# break
# data_iter = DataLoader(data_ds, batch_size=8, num_workers=2, shuffle=True, drop_last=True)
# for item in data_iter:
# print(item)
# break
# 画图测试1
# img = train_datasets[10678][0]
# #img = torchvision.utils.make_grid(train_datasets[1][0].numpy())
# img = torchvision.utils.make_grid(img)
# # print(img)
# plt.imshow(np.transpose(img,(1,2,0)))
# plt.show()
# 画图测试2
print(train_datasets.classes[7])
print(type(train_datasets))
# class_img = []
# for i in range(len(train_datasets.classes)):
# class_samples = []
# for item in train_datasets:
# img,label = item
# if label == i:
# class_samples.append((img,label))
# class_img.append(class_samples)
# print(len(class_img))
class_samples = [(img, label) for img, label in train_datasets if label == 7]
print(len(class_samples))
# plt.show()
6.2 模型设计以及改进
model_def.py
"""
ResNet模型
利用残差块训练出有效的深度神经网络:输入可以通过层间的残余连接更快地向前传播
模型
损失函数
优化器
"""
from torch import nn
import torch.nn.functional as F
import torch
# 定义SE-ResNet 块
class SE_Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1, reduction=16):
"""
:param input_channels:输入通道数
:param num_channels:输出通道数
:param use_1x1conv:要不要使用1x1卷积进行降维
:param strides:步长
"""
super().__init__()
# 第一个卷积层可以指定strides,第二个不变
self.conv1 = nn.Conv2d(
input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(
num_channels, num_channels, kernel_size=3, padding=1) # 注意
# 改变通道数
if use_1x1conv:
self.conv3 = nn.Conv2d(
input_channels, num_channels, kernel_size=1, stride=strides)
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
# 第一次卷积,以卷积代替全连接(全连接层参数量大,计算复杂度高)
nn.Conv2d(num_channels, num_channels // reduction, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_channels // reduction),
nn.ReLU(num_channels // reduction),
# 第二次卷积
nn.Conv2d(num_channels // reduction, num_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_channels),
nn.Sigmoid(),
# nn.ReLU()
)
else:
self.conv3 = None
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
# 第一次卷积,以卷积代替全连接(全连接层参数量大,计算复杂度高)
nn.Conv2d(input_channels, input_channels // reduction, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(input_channels // reduction),
nn.ReLU(input_channels // reduction),
# 第二次卷积
nn.Conv2d(input_channels // reduction, input_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(input_channels),
nn.Sigmoid(),
# nn.ReLU()
)
# 批量规范化
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True) # 修改原始张量,节省内存操作,原始张量在函数计算完成后会被修改,节省了额外的内存空间
def forward(self, X):
# 两层前置,每个卷积层后接一个批量规范化层和激活层
Y = F.relu(self.bn1(self.conv1(X)), inplace=True)
Y = self.bn2(self.conv2(Y))
Y1 = Y
Y1 = self.se(Y1)
Y = Y * Y1 # 增强特征
if self.conv3:
X = self.conv3(X)
Y = Y + X
return F.relu(Y, inplace=True)
def se_resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
SE_Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(SE_Residual(num_channels, num_channels))
return blk
def se_resnet18(num_classes):
b1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b2 = nn.Sequential(*se_resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*se_resnet_block(64, 128, 2))
b4 = nn.Sequential(*se_resnet_block(128, 256, 2))
b5 = nn.Sequential(*se_resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, num_classes)
)
return net
6.3 训练模型以及测试
train_test.py
import copy
from self_load import train_ds, train_ir, test_ir, test_ds
from config import learning_rate, epochs, batch_size
from pic_draw import draw, draw_all, draw_classes
from model_def import se_resnet18
from save_acc import write_excel, save_data
import torch
import torchvision
from torch import nn
import torch.optim as optim
import matplotlib.pyplot as plt
import time
def train_data(dataset, dataloader, model, loss_fn, optimizer, device):
"""
:param dataset: 训练数据集
:param dataloader:采样
:param model:网络模型
:param loss_fn:损失函数
:param optimizer:优化器
:param device:cpu/gpu
:return:
"""
running_loss = 0.0
running_correct = 0.0
sum_loss = 0.0
correct = 0.0
total = 0.0
# print(len(dataset))
model.train()
for imgs, labels in dataloader:
# X_train,y_train = torch.autograd.Variable(X_train),torch.autograd.Variable(y_train)
imgs, labels = imgs.to(device), labels.to(device)
# 梯度清零,将loss关于weight的导数变为0
optimizer.zero_grad()
outputs = model(imgs)
_, predicted = torch.max(outputs.data, 1)
# torch.max()返回两个值,第一个是具体的value,第二个是value所在的index
# torch.max(a,0) 获取最大值所在列号 torch.max(a,1) 获取最大值所在行号
# 计算损失值
loss = loss_fn(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
running_loss += loss.item()
# running_correct += torch.sum(predicted == labels.data)
# print(len(dataset))
train_l = running_loss / len(dataset)
# train_a = running_correct / len(dataset)
# 每训练1个batch打印一次loss和准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
train_a = correct / total
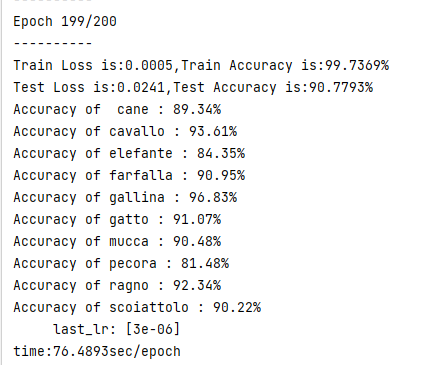
print("Train Loss is:{:.4f},Train Accuracy is:{:.4f}%".format(train_l, train_a * 100))
# print('Accuracy of the network on the %d train images: %.4f %%' % (total, 100 * correct / total))
return train_l, train_a
def test_data(dataset, dataloader, model, loss_fn, device):
"""
:param dataset:
:param dataloader:
:param model:
:param loss_fn:
:param device:
:return:
"""
testing_correct = 0
testing_loss = 0
correct = 0 # 预测正确的图片数
total = 0 # 总共的图片数
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
class_acc = []
model.eval()
with torch.no_grad():
for imgs, labels in dataloader:
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
testing_correct += torch.sum(predicted == labels.data)
testing_loss += loss.item()
# testing_correct += (predicted == y_test).sum().item()
# print(testing_loss)
test_l = testing_loss / len(dataset)
# test_a = testing_correct / len(dataset)
total += labels.size(0)
# 累积计算预测正确的数据集的大小
correct += (predicted == labels).sum() # 两个一维张量逐行对比,相同的行记为1,不同的行记为0,再利用sum(),求总和,得到相同的个数。
test_a = correct / total
# 单个精度
c = (predicted == labels).squeeze() # 去掉矩阵里维度为1的维度
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
print("Test Loss is:{:.4f},Test Accuracy is:{:.4f}%".format(test_l, test_a * 100))
# print('Accuracy of the network on the %d test images: %.4f %%' % (total, 100 * correct / total))
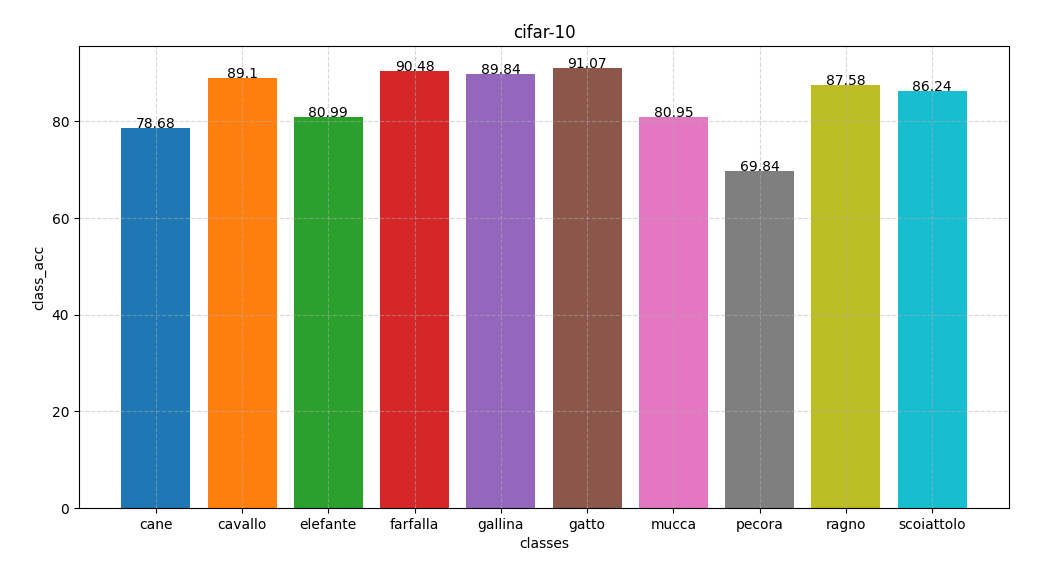
for i in range(10):
acc = 100 * class_correct[i] / class_total[i]
print('Accuracy of %5s : %.2f%%' % (dataset.classes[i], acc))
class_acc.append(float('{:.2f}'.format(acc)))
return test_l, test_a, class_acc
def train_test():
# 定义是否使用gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 网络模型 SENet
model = se_resnet18(10).to(device)
# 优化器 Adam / SGD
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-4)
# optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=5e-3)
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9,weight_decay=1e-4)
# 学习率调整策略 在0.56倍epochs和0.78倍时分别下降为前一段学习率的0.1倍
scheduler = optim.lr_scheduler.MultiStepLR(
optimizer=optimizer,
milestones=[int(epochs * 0.36), int(epochs * 0.72)],
gamma=0.1,
last_epoch=-1
)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 所有
loss_train = []
loss_test = []
acc_train = []
acc_test = []
acc_class = []
num_name = ['cane', 'cavallo', 'elefante', 'farfalla', 'gallina', 'gatto', 'mucca', 'pecora', 'ragno', 'scoiattolo',
'train_loss', 'test_loss', 'train_acc', 'test_acc']
num_data = []
best_acc = 90.0
for epoch in range(epochs):
# 开始时间
epoch_start = time.time()
print("-" * 10)
print("Epoch {}/{}".format(epoch + 1, epochs))
print("-" * 10)
train_loss, train_acc = train_data(train_ds, train_ir, model, loss_fn, optimizer, device)
test_loss, test_acc, class_acc = test_data(test_ds, test_ir, model, loss_fn, device)
# 更新学习率并查看当前的学习率
scheduler.step()
print('\t last_lr:',scheduler.get_last_lr())
# 添加训练误差和测试误差
loss_train.append(train_loss)
loss_test.append(test_loss)
# 添加训练精度和测试精度
acc_train.append(train_acc.item())
acc_test.append(test_acc.item())
# 添加个分类精度 以便绘图
acc_class.append(class_acc)
# 添加所有信息
num_data_row = class_acc.copy()
num_data_row.append(train_loss)
num_data_row.append(test_loss)
num_data_row.append(train_acc.item())
num_data_row.append(test_acc.item())
num_data.append(num_data_row)
# 结束时间
epoch_end = time.time()
print('time:{:.4f}sec/epoch'.format(epoch_end - epoch_start))
# 保存最优精度的模型
if best_acc < test_acc.item():
best_acc = test_acc.item()
# 保存当前模型
best_model = copy.deepcopy(model.state_dict())
save_name = '/home/cj2/CNN/picture_classify/ResNet/model/net_{}.pth'.format(epoch+1)
torch.save(best_model,save_name)
print('已保存最优模型,准确率为:{:.2f},文件名为:{}'.format(best_acc*100,save_name))
else:
continue
# # 保存路径
# save_path = '/home/cj2/CNN/picture_classify/ResNet/data/class_acc_200_5e_4_4.xls'
# # 将所有图像精度保存
# write_excel(classes=train_ds.classes,classes_acc=acc_class,save_file=save_path,sheet_name='test')
# 表格名称
# save_name = '/home/cj2/CNN/picture_classify/ResNet/data/info1.xls'
# save_data(num_name=num_name, num_data=num_data, save_path=save_name, sheet_name='info1')
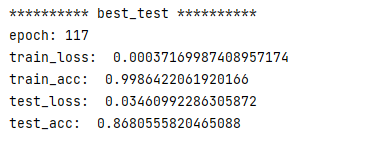
print("*" * 10, "best_test", "*" * 10)
best_test = max(acc_test)
best_test_id = acc_test.index(best_test)
print("epoch:", best_test_id + 1)
print("train_loss: ", loss_train[best_test_id])
print("train_acc: ", acc_train[best_test_id])
print("test_loss: ", loss_test[best_test_id])
print("test_acc: ", best_test)
# 绘图
draw(loss_train, loss_test, acc_train, acc_test)
# draw_all(loss_train, loss_test, acc_train, acc_test)
draw_classes(acc_class[best_test_id])
# 模型测试
def test_net(dataloader):
x_test, y_test = next(iter(dataloader))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x_test, y_test = x_test.to(device), y_test.to(device)
outputs = net(x_test)
_, pred = torch.max(outputs, 1)
print("Predict Label :", [classes[i] for i in pred.data])
print("Real Label:", [classes[i] for i in y_test])
# 测试图片可视化
img = torchvision.utils.make_grid((x_test))
img = img.numpy().transpose(1, 2, 0)
img = img * 0.5 + 0.5
plt.imshow(img)
plt.show()
6.4 图像可视化
pic_draw.py
"""
画图
"""
# 导入所需的包
import matplotlib.pyplot as plt
import numpy as np
import torchvision
from config import epochs,classes
# 显示图片的函数
def imshow(img):
img = img / 2 + 0.5 # 逆归一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 交换图像的维度
plt.show()
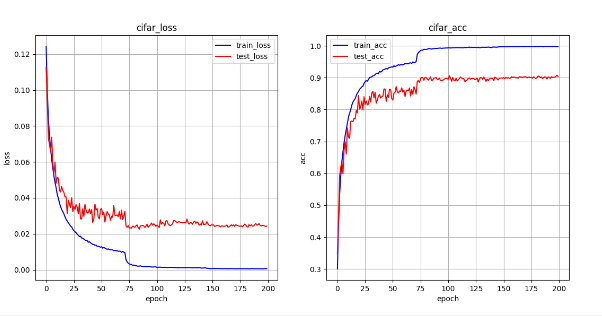
def draw(train_loss, test_loss, train_acc, test_acc):
"""
:param train_loss:
:param test_loss:
:param train_acc:
:param test_acc:
:return:
"""
plt.figure(figsize=(13, 6))
epoch = [i for i in range(len(train_loss))]
plt.subplot(1, 2, 1)
plt.plot(epoch, train_loss, label='train_loss', color='blue')
plt.plot(epoch, test_loss, label='test_loss', color='red')
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("cifar_loss")
plt.grid()
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epoch, train_acc, label='train_acc', color='blue')
plt.plot(epoch, test_acc, label='test_acc', color='red')
plt.xlabel("epoch")
plt.ylabel("acc")
plt.title("cifar_acc")
plt.grid()
plt.legend()
plt.show()
def draw_all(train_loss, test_loss, train_acc, test_acc):
plt.figure(figsize=(10, 10))
epoch = [i for i in range(len(train_loss))]
plt.plot(epoch, train_loss, label='train_loss', color='blue')
plt.plot(epoch, test_loss, label='test_loss', color='red')
plt.plot(epoch, train_acc, label='train_acc', color='blue')
plt.plot(epoch, test_acc, label='test_acc', color='red')
plt.xlabel("epoch")
plt.ylabel("loss_acc")
plt.title("cifar_acc")
plt.grid(b=True, linestyle="--", alpha=0.5, axis="both")
plt.legend()
plt.show()
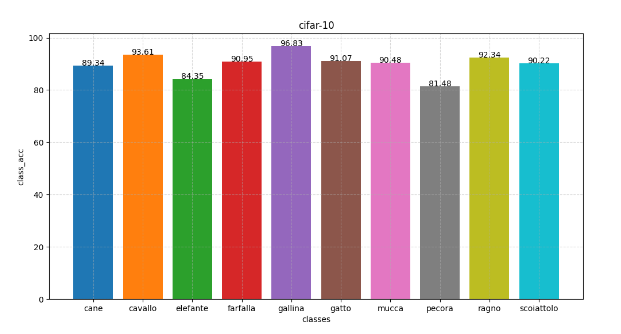
def draw_classes(classes_acc):
"""
:param classes_acc:
:return:
"""
x_data = [classes[i] for i in range(len(classes_acc))]
y_data = classes_acc.copy()
plt.figure(figsize=(12, 6))
# 画柱状图
for i in range(len(x_data)):
plt.bar(x_data[i], y_data[i])
plt.text(i, y_data[i], y_data[i],ha ="center")
# 设置图片名称
plt.title("cifar-10")
# 设置x轴签名
plt.xlabel("classes")
# 设置y轴签名
plt.ylabel("class_acc")
plt.grid(b=True, linestyle="--", alpha=0.5, axis="both")
# 显示
plt.show()
6.5 数据保存
save_acc.py
import xlwt
import xlrd
# row 每一轮 epochs
# column 十分类精度
def write_excel(classes, classes_acc, save_file, sheet_name):
"""
:param classes:
:param classes_acc:
:param save_file:
:param sheet_name:
:return:
"""
try:
# 创建工作簿
data_acc = xlwt.Workbook(encoding='utf-8')
# 创建sheet表单
sheet = data_acc.add_sheet(sheet_name)
# 写表头
header = classes.copy()
for k in range(len(header)):
sheet.write(0, k, header[k])
# 添加内容
row = 1
for i in range(len(classes_acc)):
for j in range(len(classes)):
sheet.write(row, j, classes_acc[i][j])
# 写完一行,行号+1
row += 1
# 保存
data_acc.save(save_file)
print('success')
except Exception as e:
print('defeat', e)
def save_data(num_name, num_data, save_path, sheet_name):
"""
:param num_name:
:param num_data:
:param save_path:
:param sheet_name:
:return:
"""
try:
# 创建工作簿
data_acc = xlwt.Workbook(encoding='utf-8')
# 创建sheet表单
sheet = data_acc.add_sheet(sheet_name)
# 写表头
header = num_name.copy()
for k in range(len(header)):
sheet.write(0, k, header[k])
# 添加内容
row = 1
for i in range(len(num_data)):
for j in range(len(num_name)):
sheet.write(row, j, num_data[i][j])
# 写完一行,行号+1
row += 1
# 保存
data_acc.save(save_path)
print('success')
except Exception as e:
print('defeat', e)
def read_excel(xls_file, sheet_name, row):
# 打开文件
data_acc = xlrd.open_workbook(xls_file)
# 获取所有sheet的名字 list
all_sheetname = data_acc.sheet_names()
print(all_sheetname)
# 获取指定表单的索引
sheet_id = all_sheetname.index(sheet_name)
print(sheet_id)
# 获取指定表单的内容
sheet_content = data_acc.sheet_by_name(sheet_name) # 通过表单名获取
# sheet_content = data_acc.sheet_by_index(sheet_id) # 通过索引获取
rows = sheet_content.row(row) # 获取指定行的内容 数组类型
print(rows)
# 定义一个空队列,将读取的一行数据保存
class_acc = []
for i in range(len(rows)):
class_acc.append(rows[i].value)
print(class_acc)
return class_acc
6.6 主函数
main.py
from train_test import train_test
train_test()















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









