






gan公式理解+源码
GAN
应用目标
生成式任务(生成、重建、超分辨率、风格迁移、补全、上采样等)
核心思想
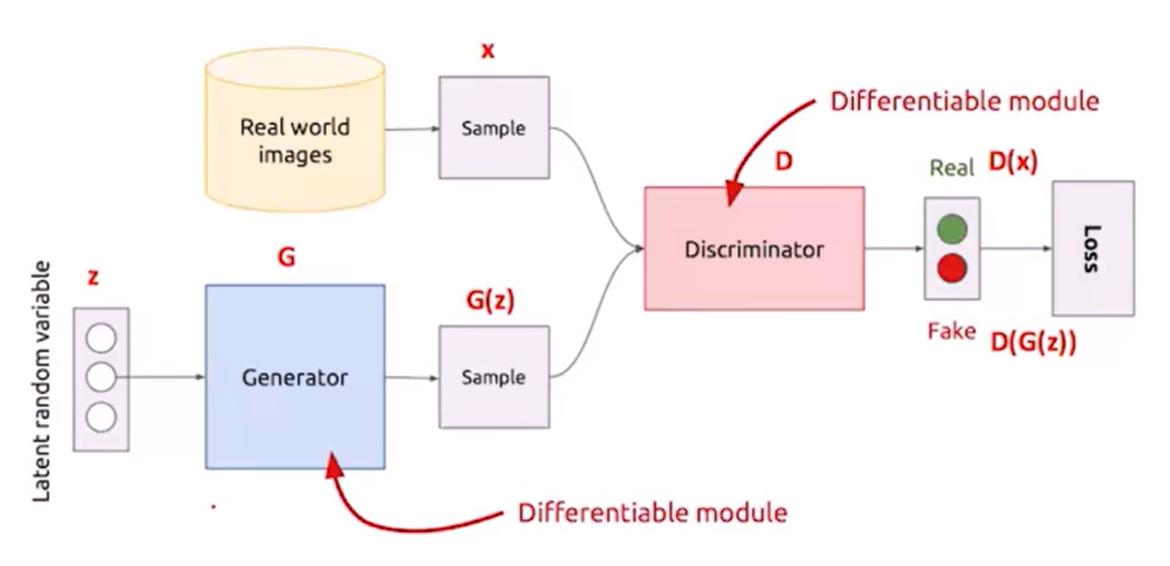
生成器G和判别器D的一代代博弈
- 生成器G:生成网络,通过输入生成图像,希望生成的数据可以让D分辨不出来
- 判别器D:二分类网络,将生成器生成图像作为负样本,真实图像作为正样本,希望尽可能分辨出G生成的数据和真实数据的分布
- 判别器D训练:给定G,通过G生成图像产生负样本,并结合真实图像作为正样本来训练D
- 生成器G训练:给定D,以使得D对G生成图像的评分尽可能接近正样本作为目标来训练G
- G和D的训练过程交替进行,对抗过程使得G生成的图像越来越逼真,D分辨真假的能力越来越强
算法原理
GAN的精妙之处:对生成模型损失函数的处理
G(生成网络):接受一个随机噪声 z z z,通过该噪声生成图片,记作 G ( z ) G(z) G(z)
输入噪声的随机性可以带来生成图像的多样性
D(判别网络):输入参数为 x x x, x x x代表一张图片,输出 D ( x ) D(x) D(x)代表 x x x为真实图片的概率,如果为1,就代表100%是真实图片,若为0,则代表不可能是真实的图片
问题分析
目标函数如何分析?

对数函数:在其定义域内是单调递增函数,数据取对数不改变数据间的相对关系,使用 l o g log log后,可放大损失,便于计算和优化
-
前半部分公式 E x ∽ p d a t a ( x ) [ l o g D ( x ) ] E_{x\backsim p_{data}(x)}[logD(x)] Ex∽pdata(x)[logD(x)]
- D ( x ) D(x) D(x)表示判别器对真实图片的判别,取对数函数后目的是为了其值趋于0,也就是 D ( x ) D(x) D(x)趋于1,也就是放大损失
-
E
x
∽
p
d
a
t
a
(
x
)
E_{x\backsim p_{data}(x)}
Ex∽pdata(x)表示期望
x
x
x从
p
d
a
t
a
p_{data}
pdata中获取
- x x x表示真实的数据(图片)
- P d a t a P_{data} Pdata表示真实数据的分布
- 综上所述,前半部分公式
- 含义:判别器判别出真实数据的概率。
- 优化目标:使得该概率越大越好
-
后半部分公式 E z ∽ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] E_{z\backsim p_{z}(z)}[log(1-D(G(z)))] Ez∽pz(z)[log(1−D(G(z)))]
-
E
z
∽
p
z
(
z
)
E_{z\backsim p_{z}(z)}
Ez∽pz(z)表示期望
z
z
z从
p
z
p_{z}
pz中获取
- z z z表示随机的噪声
- P z ( z ) P_{z}(z) Pz(z)表示生成随机噪声的分布
- 对于判别器D来说,若输入的是生成数据( D ( G ( z ) ) D(G(z)) D(G(z))),其目标便是将生成数据判定为0(即 D ( G ( z ) ) = 0 D(G(z))=0 D(G(z))=0),也就是希望 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))越大越好
- 对于生成器G来说,其目的是生成的数据被判别器识别为真(即 D ( G ( z ) ) = 1 D(G(z))=1 D(G(z))=1),也就是希望 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))越小越好
- 综上所述,D和G的优化目标相反
-
E
z
∽
p
z
(
z
)
E_{z\backsim p_{z}(z)}
Ez∽pz(z)表示期望
z
z
z从
p
z
p_{z}
pz中获取
-
总结
- 对于判别器D,最大化 l o g D ( x ) logD(x) logD(x)和 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))),从而达到最大化 V ( D , G ) V(D,G) V(D,G)
- 对于生成器G,最小化 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))),从而达到最小化 V ( D , G ) V(D,G) V(D,G) 的目标
先更新D参数指导G方向
公式解析:
m
i
n
G
m
a
x
D
V
(
D
,
G
)
=
E
x
∽
p
d
a
t
a
(
x
)
[
l
o
g
D
(
x
)
]
+
E
z
∽
p
z
(
z
)
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
min_{G}max_{D}V(D,G)=E_{x\backsim p_{data}(x)}[logD(x)]+E_{z\backsim p_{z}(z)}[log(1-D(G(z)))]
minGmaxDV(D,G)=Ex∽pdata(x)[logD(x)]+Ez∽pz(z)[log(1−D(G(z)))]
- 先算 m a x D V ( D , G ) = E x ∽ p d a t a ( x ) [ l o g D ( x ) ] + E z ∽ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] max_{D}V(D,G)=E_{x\backsim p_{data}(x)}[logD(x)]+E_{z\backsim p_{z}(z)}[log(1-D(G(z)))] maxDV(D,G)=Ex∽pdata(x)[logD(x)]+Ez∽pz(z)[log(1−D(G(z)))],固定G,用D区分正负样本,因此是 m a x D max_{D} maxD
- 后算 整体 ,判别式D固定不动,通过调整生成器G,希望判别器不失误,尽可能不让判别器区分出正负样本(提高生成图像的真实性)
每训练出一个生成器,就要生出一个判别器,判别器要使真实图像的值尽可能的大,生成图像的值尽可能的小。也就是说让判别器具有更强的判别能力。是个动态的问题,跟以前损失函数恒定不变的思想不同
如何生成图片?
G和D应该如何设置?
如何进行训练?

伪代码如下:
for 迭代 in range(迭代总数):
for batch in range(batch_size):
新batch = input1的batch + input2的batch # (batch加倍)
for 轮数 in range(判别器总轮数):
步骤一
步骤二
损失函数
生成器损失(能否生成近似真实图片并使得判别器将生成图片判定为真):通过判别器的输出来计算
判别器损失(能否正确区分生成的图片和真实图片):判别器输出为一个概率值,通过交叉熵计算
代码实现
import torch.cuda
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
from data_load import MnistDataset
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
"""
gan
从头到尾
应用领域
1、图像生成:生成一些假的数据,比如海报中的人脸
2、图像增强:从分割图生成假的真实街景,方便训练无人汽车
3、风格化和艺术的图像创造:转换图像风格,修补图像
4、声音的转换:一个人的声音转为另一个的声音;去除噪声等
噪声-生成器-生成样本 + 真实样本 进入 判别器 计算损失
基础的GAN效果并不是很好
可以试试DCGAN
"""
# 图像预处理
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # 转换为灰度图像
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 数据归一化(-1,1) 生成器激活函数tahn的范围为(-1,1)
])
# num_workers = 6
batch_size = 64
train_data = MnistDataset(data_dir='./dataset/mnist_train', transform=transform)
train_loader = DataLoader(train_data, batch_size=batch_size,
shuffle=True) # 增加shuffle减少过拟合
# 生成器定义 输入为噪声(长度为100,正态分布的随机数)
class Generator(nn.Module):
"""
输入:长度为100的噪声(正态分布随机数)
输出:(1,28,28)的图片
linear 1 : 100 --- 256
linear 2 : 256 --- 512
linear 3 : 512 --- 28*28
reshape : 28*28 --- 1,28,28
"""
def __init__(self):
super(Generator, self).__init__() # 继承父类的属性
self.gen = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28 * 28),
nn.Tanh() # 将输出规范到(-1,1)
)
def forward(self, x):
img = self.gen(x)
img = img.view(-1, 28, 28)
return img # 返回黑白图片
# 判别器定义
class Discriminator(nn.Module):
"""
输入:(1,28,28)的图片
输出:二分类的概率值,sigmoid激活(范围 0-1)
"""
def __init__(self):
super(Discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.LeakyReLU(), # 在负值的地方保留一些梯度,gan的训练技巧
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1),
nn.Sigmoid() # 将输出规范到(0,1)
)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.dis(x)
return x
# 初始化模型、优化器
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)
g_optim = torch.optim.Adam(gen.parameters(), lr=0.0001)
d_optim = torch.optim.Adam(dis.parameters(), lr=0.0001)
# 损失函数
loss_fn = nn.BCELoss() # 如果没有激活的话用nn.BCEWithLogitsLoss
test_input = torch.randn(16, 100, device=device)
def gen_img_plot(model, test_input):
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow((prediction[i] + 1) / 2)
plt.axis('off')
plt.show()
D_loss = []
G_loss = []
for epoch in range(20):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(train_loader)
for step, (img, _) in enumerate(train_loader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size, 100, device=device) # 随机噪声
# 判别器操作
d_optim.zero_grad()
real_output = dis(img) # 判别器输入真实图片,real_output对真实图片的预测结果
# 人为构造全1数组torch.ones_like(real_output)
d_real_loss = loss_fn(real_output,
torch.ones_like(real_output)) # 判别器在真实图像上的损失
d_real_loss.backward()
gen_img = gen(random_noise)
# detach() 截断梯度,得到没有梯度的tensor,为了优化判别器
fake_output = dis(gen_img.detach()) # 判别器输入生成图片,fake_output对生成图片的预测
# 人为构造全0数组torch.zeros_like(real_output)
d_fake_loss = loss_fn(fake_output,
torch.zeros_like(fake_output)) # 判别器在生成图像上的损失
d_fake_loss.backward()
# 总损失
d_loss = d_real_loss + d_fake_loss
d_optim.step()
# 生成器操作
g_optim.zero_grad()
# 将生成器图片放到判别器当中
fake_output = dis(gen_img)
# 对于生成器来说,希望生成图像被判别为1
g_loss = loss_fn(fake_output,
torch.ones_like(fake_output)) # 生成器的损失
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():
# 获得平均损失
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch)
print('D_loss:', d_epoch_loss) # 判别器损失
print('G_loss:', g_epoch_loss) # 生成器损失
gen_img_plot(gen, test_input)
if __name__ == '__main__':
imgs, _ = next(iter(train_loader))
print(imgs.shape) # torch.Size([64, 1, 28, 28])
结果图:
第20次

第1次

以上的模型只测试了20轮,效果并不是很好,可以试试在生成网络和判别网络中添加卷积或者测试多一点















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









