






 本文介绍使用Python Selenium模拟登录企查查网站,爬取并解析公司法律风险数据的全过程,包括裁判文书、开庭公告等,详细展示了数据抓取、解析及保存的代码实现。
本文介绍使用Python Selenium模拟登录企查查网站,爬取并解析公司法律风险数据的全过程,包括裁判文书、开庭公告等,详细展示了数据抓取、解析及保存的代码实现。
由于爬取数据涉及到网站会员,没有会员有需求的别多虑,找老板冲啊
读取已有json文件爬取对应公司的企业数据,保存
工具:
Chrome
点击下载chrome的webdriver: http://chromedriver.storage.googleapis.com/index.html
不同的Chrome的版本对应的chromedriver.exe 版本也不一样,下载时不要搞错了。如果是最新的Chrome, 下载最新的chromedriver.exe 就可以了。
把chromedriver的路径也加到环境变量里。
Xpath
helper Python爬虫工具谷歌浏览器插件: https://blog.csdn.net/xudailong_blog/article/details/78837538
第一步模拟登陆:
通过xpath定位账号密码框,过程中有个拖拽动作,拖拽完 调用打码平台输入验证码,点击提交
注意滑动需要计算网页滑动尺寸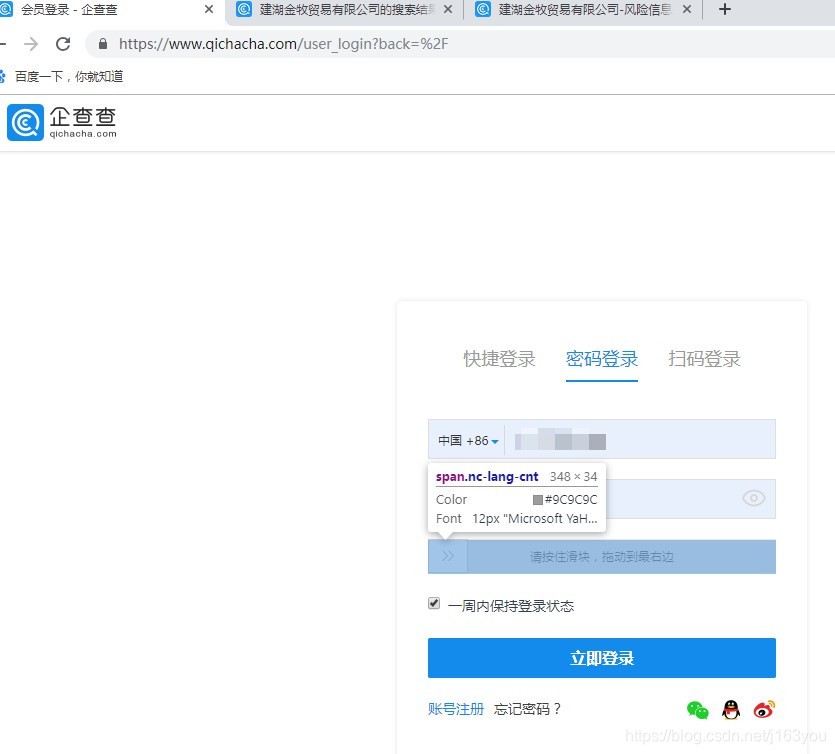
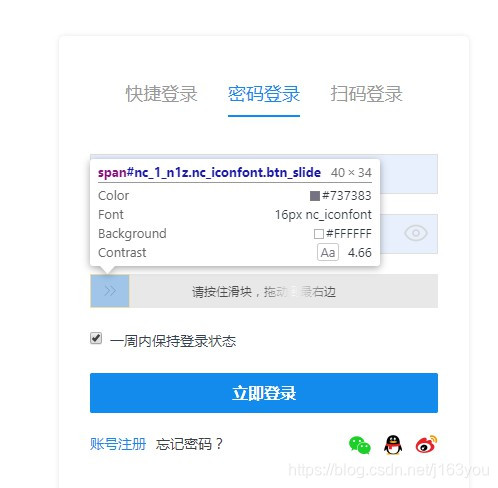
此处为拖拽代码,具体参数不清楚的自行百度 :
from selenium.webdriver import ActionChains
# 滑动条定位
start = driver.find_element_by_xpath('//div[@id="nc_1_n1t"]/span')
# 长按拖拽
action = ActionChains(driver)
# 长按
action.click_and_hold(start)
# 拉动
action.drag_and_drop_by_offset(start, 308, 0).perform()完整登录代码
def login_web():
# 打开企查查登录网页
driver.get("https://www.qichacha.com/user_login")
# 加载时间
# time.sleep(3)
# 点击密码登录
driver.find_element_by_xpath('//div[@class="login-panel-head clearfix"]/div[2]').click()
time.sleep(1)
# 找到账号输入框
driver.find_element_by_xpath('//div[@class="form-group"]/input[@id="nameNormal"]'). \
send_keys('******')
# 找到密码输入框
driver.find_element_by_xpath('//div[@class="form-group m-t-md"]/input[@id="pwdNormal"]'). \
send_keys('*****')
# 滑动条定位
start = driver.find_element_by_xpath('//div[@id="nc_1_n1t"]/span')
# 长按拖拽
action = ActionChains(driver)
# 长按
action.click_and_hold(start)
# 拉动
action.drag_and_drop_by_offset(start, 308, 0).perform()
time.sleep(1)
# 保存图片
save()
# 此处延时为了手动输入验证码(省钱。)
time.sleep(10)
# 超级鹰识别验证码
# ocr = chaoji()
# # 输入验证码
# driver.find_element_by_xpath('//div[@class="imgCaptcha_text"]/input').send_keys(ocr)
# # 点击提交
# driver.find_element_by_xpath('//div[@id="nc_1_scale_submit"]/span').click()
# 截图
driver.save_screenshot('web.png')
# 点击登录
driver.find_element_by_xpath('//form[@id="user_login_normal"]/button').click()
time.sleep(3)
# 关闭弹窗
driver.find_element_by_xpath('//div[@class="bindwx"]/button/span[1]').click()大致说一下代码逻辑,遍历公司,单个公司判断是否包含法律风险,判断数据源(企查查有三个数据大类,自身风险、关联风险、提示信息),单类数据判断分类(目前已知有十四种分类,代码中我都会贴出),每一类数据都需要判断条数,点开后弹框内的数据也需要判断条数,毕竟代码要灵活嘛,上面说的有些是需要会员账号才能看到的,需注意
好了,我累了,我上源码了
# -*- coding: UTF-8 -*-
import json
import random
import time
import csv
import urllib
from lxml import etree
from selenium import webdriver
from selenium.webdriver import ActionChains
from chaojiying import Chaojiying_Client
from openpyxl import load_workbook
import sys
reload(sys)
exec ("sys.setdefaultencoding('utf-8')")
driver = webdriver.ChromeOptions()
driver.add_argument('--headless') # 开启无界面模式
driver.add_argument('--disable-gpu') # 禁用gpu,解决一些莫名的问题
driver = webdriver.Chrome()
driver.maximize_window()
def save():
img = driver.find_element_by_xpath('//div[@class="imgCaptcha_img"]/img')
img_url = img.get_attribute("src")
data = urllib.urlopen(img_url).read()
f = open('a.jpg', 'wb')
f.write(data)
def chaoji():
chaojiying = Chaojiying_Client('账号', '密码', '899210') # 用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
datas = chaojiying.PostPic(im, 1902) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
ocr = datas['pic_str']
# print datas
print ocr
return ocr
def login_web():
# 打开企查查登录网页
driver.get("https://www.qichacha.com/user_login")
# 加载时间
# time.sleep(3)
# 点击密码登录
driver.find_element_by_xpath('//div[@class="login-panel-head clearfix"]/div[2]').click()
time.sleep(1)
# 找到账号输入框
driver.find_element_by_xpath('//div[@class="form-group"]/input[@id="nameNormal"]'). \
send_keys('')
# 找到密码输入框
driver.find_element_by_xpath('//div[@class="form-group m-t-md"]/input[@id="pwdNormal"]'). \
send_keys('')
# 滑动条定位
start = driver.find_element_by_xpath('//div[@id="nc_1_n1t"]/span')
# 长按拖拽
action = ActionChains(driver)
# 长按
action.click_and_hold(start)
# 拉动
action.drag_and_drop_by_offset(start, 308, 0).perform()
time.sleep(1)
# 保存图片
save()
# 此处延时为了手动输入验证码(省钱。)
time.sleep(10)
# 超级鹰识别验证码
# ocr = chaoji()
# # 输入验证码
# driver.find_element_by_xpath('//div[@class="imgCaptcha_text"]/input').send_keys(ocr)
# # 点击提交
# driver.find_element_by_xpath('//div[@id="nc_1_scale_submit"]/span').click()
# 截图
driver.save_screenshot('web.png')
# 点击登录
driver.find_element_by_xpath('//form[@id="user_login_normal"]/button').click()
time.sleep(3)
# 关闭弹窗
driver.find_element_by_xpath('//div[@class="bindwx"]/button/span[1]').click()
def run():
# 读取本地文件
with open('data.json', 'r') as f:
datas = json.load(f)
data_list = []
for i in datas:
data = i[u"企业名称"].encode('utf-8').decode('utf-8')
number = i[u"统一社会信用代码"].encode('utf-8')
# print data
# print type(data)
try:
# 输入公司名
driver.find_element_by_xpath('//div[@class="input-group"]/input[@name="key"]').send_keys(data)
time.sleep(1)
# 点击搜索
driver.find_element_by_xpath('//div[@class="input-group"]/span/input').click()
# time.sleep(random.randint(1, 5))
except Exception, e:
# 切换回原窗口
driver.switch_to.window(driver.window_handles[0])
time.sleep(1)
# 删除原公司名
driver.find_element_by_xpath('//div[@class="input-group"]/a').click()
# time.sleep(random.randint(1, 3))
# 输入下一个公司
driver.find_element_by_xpath('//div[@class="input-group"]/input[@name="key"]').send_keys(data)
time.sleep(1)
# 点击搜索
driver.find_element_by_xpath('//div[@class="input-group"]/span/button').click()
# print driver.title
# 点击第一条
driver.find_element_by_xpath('//table[@class="m_srchList"]/tbody[@id="search-result"]/tr[1]/td[3]/a').click()
# 获取当前窗体的列表
# print(driver.window_handles)
# 切换至第二个窗口
driver.switch_to.window(driver.window_handles[1])
# 此处做判断,输入公司是否包含法律风险
aaa = driver.find_element_by_xpath('//div[@class="risk-panel b-a"]/a[2]').click()
if aaa:
# 点击查看风险
driver.find_element_by_xpath('//div[@class="risk-panel b-a"]/a[2]').click()
time.sleep(1)
# 分析数据源
# 自身风险
url1 = driver.find_element_by_xpath('//div[@class="tab pull-left"]/a[1]').get_attribute('href')
# 关联风险
url2 = driver.find_element_by_xpath('//div[@class="tab pull-left"]/a[2]').get_attribute('href')
# 提示信息
url3 = driver.find_element_by_xpath('//div[@class="tab pull-left"]/a[3]').get_attribute('href')
if url1:
# ---------------------------------------------- 自身风险 ----------------------------------------------
# 点击界面
driver.find_element_by_xpath('//div[@class="tab pull-left"]/a[1]').click()
time.sleep(1)
print '{} 包含 自身风险 数据'.format(i[u"企业名称"].encode('utf-8'))
# 点击 裁判文书 id= judgementLis
judgementList = driver.find_elements_by_xpath('//div[@class="container"]/div[@id="judgementList"]/section/div')
ju = 0
# print type(books)
caipan_list = {}
if judgementList:
print '----------------------命中裁判文书----------------------'
for book in judgementList:
print ju + 1
time.sleep(1)
judgementList[ju].click()
# 此处必须加延时,等待网页JS渲染
time.sleep(1)
html_cai = etree.HTML(driver.page_source)
# print driver.page_source
# 弹窗内数据条数
caipan_len = driver.find_elements_by_xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr')
bananas = len(caipan_len)
print '裁判文书含有 {}条数据'.format(bananas - 1)
ban = 2
for banana in range(1, bananas):
try:
# 案件名称
titles_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[2]/a/text()'.format(ban))
titles_caipan = titles_caipan[0].strip()
print '案件名称:', titles_caipan
# 发布时间
time_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[3]/text()'.format(ban))
time_caipan = time_caipan[0].strip()
print '发布时间:', time_caipan
# 案件编号
num_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[4]/text()'.format(ban))
num_caipan = num_caipan[0].strip()
print '案件编号:', num_caipan
# 案件身份
id_caipan = html_cai.xpath('string(//table[@class="ntable ntable-odd"]/tbody/tr[{}]/td[5])'.format(ban))
# id_caipan = id_caipan[0].stirp()
print '案件身份:', id_caipan
# 执行法院
court_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[6]/text()'.format(ban))
court_caipan = court_caipan[0].strip()
print '执行法院:', court_caipan
ban += 1
except Exception, e:
# 案件名称
titles_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[2]/a/text()')
titles_caipan = titles_caipan[0].strip()
print '案件名称:', titles_caipan
# 发布时间
time_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[3]/text()')
time_caipan = time_caipan[0].strip()
print '发布时间:', time_caipan
# 案件编号
num_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[4]/text()')
num_caipan = num_caipan[0].strip()
print '案件编号:', num_caipan
# 案件身份
id_caipan = html_cai.xpath('string(//table[@class="ntable ntable-odd"]/tbody/tr[2]/td[5])')
id_caipan = id_caipan
print '案件身份:', id_caipan[0].strip()
# 执行法院
court_caipan = html_cai.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[6]/text()')
court_caipan = court_caipan[0].strip()
print '执行法院:', court_caipan
caipan_list['企业名称:'] = data
caipan_list['统一社会信用代码:'] = number
caipan_list['类型:'] = '法律风险'
caipan_list['标题:'] = titles_caipan
caipan_list['时间:'] = time_caipan
caipan_list['内容:'] = '案件名称:'+titles_caipan+'\n'+'发布时间:'+time_caipan+'\n'+'案件编号:'+num_caipan+'\n'+'案件身份:'+id_caipan+'\n'+'执行法院:'+court_caipan
data_list.append(caipan_list)
# print '\n'
# 关闭弹窗
driver.find_element_by_xpath('//div[@class="modal fade in"]/div/div[@class="modal-content risk-modal-list"]/div/button').click()
ju += 1
# 点击 开庭公告 class= panel m-b-xs
notices = driver.find_elements_by_xpath('//div[@class="container"]/section[@class="panel m-b-xs"]/div')
no = 0
kaiting_list = {}
if notices:
print '----------------------命中开庭公告----------------------'
for notice in notices:
print no + 1
time.sleep(1)
notices[no].click()
# 此处必须加延时,等待网页JS渲染
time.sleep(1)
html_gonggao = etree.HTML(driver.page_source)
# print driver.page_source
# 弹窗内数据条数
notice_len = driver.find_elements_by_xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr')
apples = len(notice_len)
print '开庭公告含有 {}条数据'.format(apples - 1)
app = 2
for apple in range(1, apples):
try:
# 案号
id_gongao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[2]/a/text()'.format(app))
id_gongao = id_gongao[0].strip()
print '案号:', id_gongao
# 开庭日期
time_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[3]/text()'.format(app))
time_gonggao = time_gonggao[0].strip()
print '开庭日期:', time_gonggao
# 案由
reason_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[4]/text()'.format(app))
reason_gonggao = reason_gonggao[0].strip()
print '案由:', reason_gonggao
# 公诉人/原告/上诉人/申请人
plaintiff_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[5]/text()'.format(app))
plaintiff_gonggao = plaintiff_gonggao[0].strip()
print '公诉人/原告/上诉人/申请人:', plaintiff_gonggao
# 被告人/被告/被上诉人/被申请人
accused_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[{}]/td[6]/text()'.format(app))
accused_gonggao = accused_gonggao[0].strip()
print '被告人/被告/被上诉人/被申请人:', accused_gonggao
app += 1
except Exception, e:
# 案号
id_gongao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[2]/a/text()')
id_gongao = id_gongao[0].strip()
print '案号:', id_gongao
# 开庭日期
time_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[3]/text()')
time_gonggao = time_gonggao[0].strip()
print '开庭日期:', time_gonggao
# 案由
reason_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[4]/text()')
reason_gonggao = reason_gonggao[0].strip()
print '案由:', reason_gonggao
# 公诉人/原告/上诉人/申请人
plaintiff_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[5]/text()')
plaintiff_gonggao = plaintiff_gonggao[0].strip()
print '公诉人/原告/上诉人/申请人:', plaintiff_gonggao
# 被告人/被告/被上诉人/被申请人
accused_gonggao = html_gonggao.xpath('//div[@class="modal-body"]/section/div[2]/table/tbody/tr[2]/td[6]/text()')
accused_gonggao = accused_gonggao[0].strip()
print '被告人/被告/被上诉人/被申请人:', accused_gonggao
kaiting_list['企业名称:'] = data
kaiting_list['统一社会信用代码:'] = number
kaiting_list['类型:'] = '法律风险'
kaiting_list['标题:'] = reason_gonggao
kaiting_list['时间:'] = time_gonggao
kaiting_list['内容:'] = '案号:'+id_gongao+'\n'+'开庭日期:'+time_gonggao+'\n'+'案由:'+reason_gonggao+'\n'+'公诉人/原告/上诉人/申请人:'+plaintiff_gonggao+'\n'+'被告人/被告/被上诉人/被申请人:'+accused_gonggao
data_list.append(kaiting_list)
# print '\n'
# 关闭弹窗
driver.find_element_by_xpath('//div[@class="modal fade in"]/div/div[@class="modal-content risk-modal-list"]/div/button').click()
no += 1
# 点击 行政处罚 id= apList
# 点击 税务行政处罚 id= tpList
time.sleep(random.randint(1, 3))
if url2:
print '{} 包含 关联风险 数据'.format(i[u"企业名称"].encode('utf-8'))
# 点击 股权出质 id= PledgeList
# 点击 法定代表人变更 id= OperList
# 点击 大股东变更 id= PartnerList
# 点击 严重违法 id= SeriousViolation
# 点击 经营异常 id= ExceptionList
# 点击 失信被执行人 id= shixinList
# 点击 被执行人 id= zhixingList
# 点击 限制消费 id= stList
time.sleep(random.randint(1, 3))
if url3:
print '{} 包含 提示信息 数据'.format(i[u"企业名称"].encode('utf-8'))
# 点击 法定代表人变更 section> class= panel m-b-xs
# 点击 大股东变更 section> class= panel m-b-xs
else:
print '{} 该公司没有风险提示'.format(i[u"企业名称"].encode('utf-8'))
# 关闭页面换家公司
driver.close()
# 切换回原窗口
driver.switch_to.window(driver.window_handles[0])
# time.sleep(random.randint(1, 5))
# 写入本地文件
with open('111.json', 'w') as f:
json.dump(data_list, f, ensure_ascii=False, indent=2)
# wb可以解决python2 没有newline='',否则数据出现每行空一行
with open('111.csv', 'wb') as f:
# 通过文件对象创建 csv 写入对象
csv_writer = csv.writer(f)
# 写入标题
csv_writer.writerow(data_list[0].keys())
# # 写入内容
for row in data_list:
csv_writer.writerow(row.values())
# l = [i.decode('utf8').encode('gbk') for i in row.values()]
# csv_writer.writerow(l)
f.close()
if __name__ == '__main__':
login_web()
run()
完整代码一千一百多行,,需要看关系私聊。。。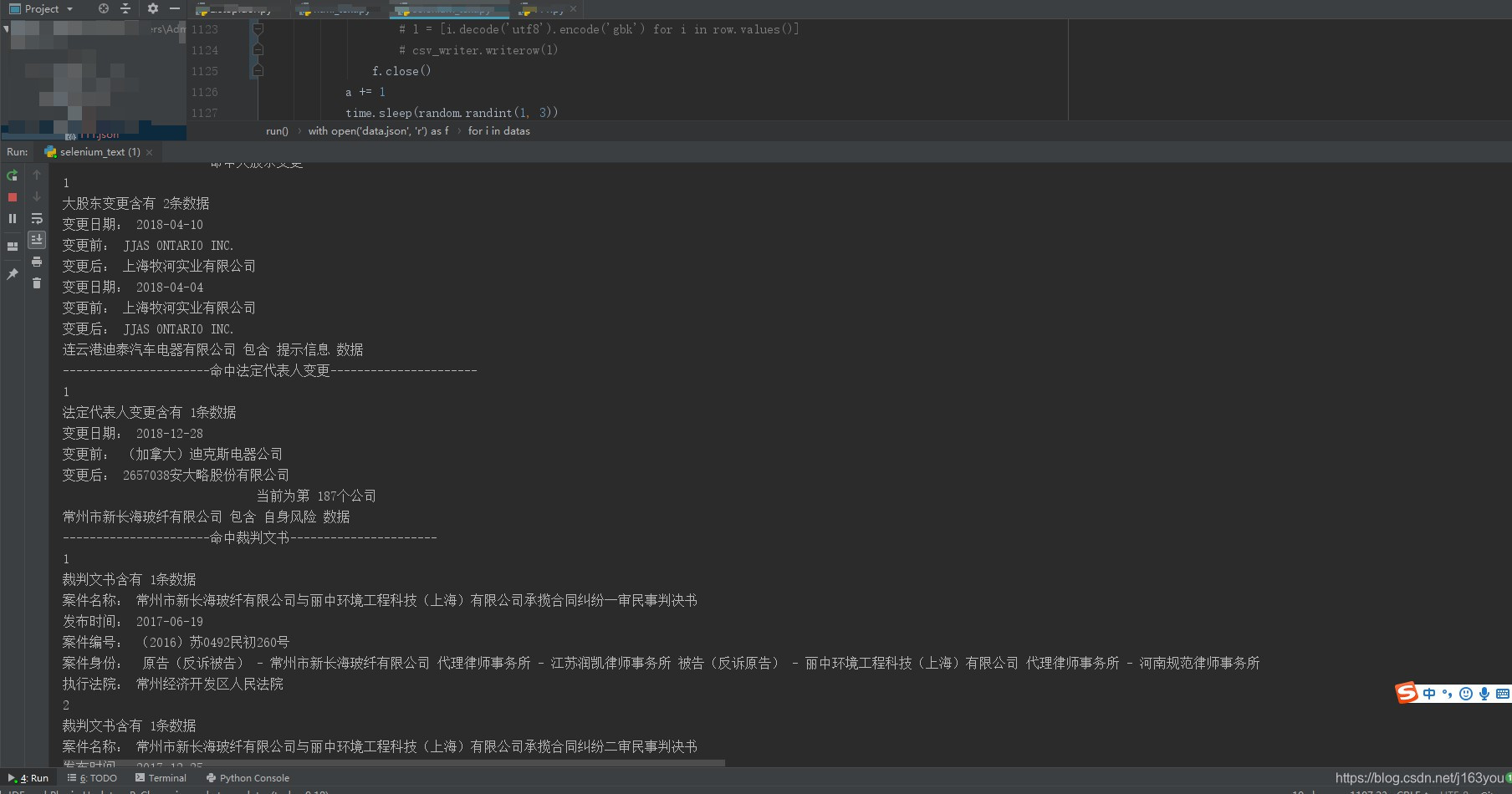
此贴终结~~~~~~~~~~(手动滑稽)
注明:转载需注明原贴链接,利用代码进行非法行为与本人无关

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









