







 本文介绍了一种基于TF-IDF的关键词提取方法,并通过实际案例展示了如何利用Jieba分词工具进行文本预处理,进一步应用TF-IDF算法提取关键词。此外,还介绍了如何构建基于词频和TF-IDF的文本向量,用于文档相似度衡量,并通过贝叶斯算法实现新闻分类任务。
本文介绍了一种基于TF-IDF的关键词提取方法,并通过实际案例展示了如何利用Jieba分词工具进行文本预处理,进一步应用TF-IDF算法提取关键词。此外,还介绍了如何构建基于词频和TF-IDF的文本向量,用于文档相似度衡量,并通过贝叶斯算法实现新闻分类任务。
书山有路勤为径,学海无涯苦作舟

一、数据及文本分析
1.1 数据内容
data: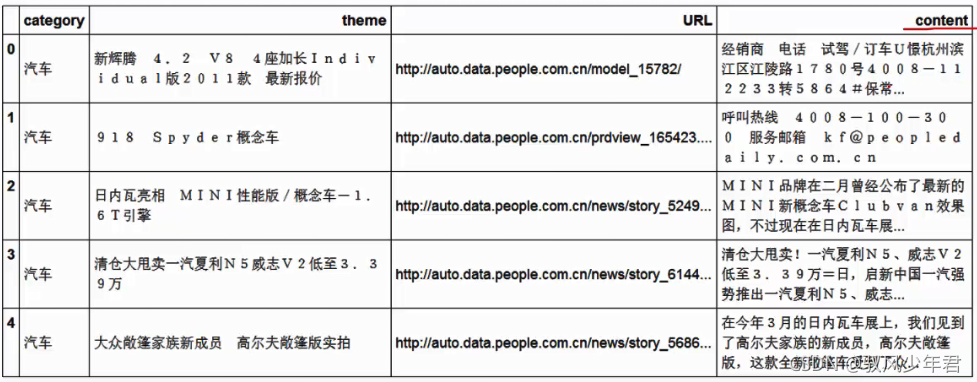
1.2 停用词
停用词
- 1.语料中大量出现
- ⒉没啥大用(不能体现文章内容,还增加了文本特征,干扰分析,删除了也不影响表现文章主要意思)
- 3.留着过年嘛?

1.3 TF-IDF:关键词提取
1.3.1 TF
《中国的蜜蜂养殖》∶进行词频(Term Frequency,缩写为TF)统计
出现次数最多的词是---- “的”、“是”、“在”----这一类最常用的词(停用词)
“中国”、“蜜蜂”、“养殖”这三个词的出现次数一样多,重要性是一样的?
"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见(所以文章的中心还是蜜蜂养殖)
1.3.2 “逆文档频率” ( Inverse Document Frequency,缩写为IDF)
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性正是我们所需要的关键词
公式如下:
TF = 该词在该文章里的出现次数 / 文章词所有词的计数总数

如果该词越稀有,IDF就会越高,越稀有并且在当前这篇文章中出现的次数越多,说明很可能是这篇文章的关键词。
1.3.3 关键词提取

《中国的蜜蜂养殖》︰假定该文长度为1000个词,“中国”.“蜜蜂”、“养殖"各出现20次,则这三个词的"词频”(TF)都为0.02
搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,
包含"养殖"的网页为0.973亿张

二、文档的相似度衡量
2.1 基于词频的文本向量的构建
- 将语料库的进行分词,语料清洗,(清洗去停用词,再筛选去特定环境下的没用对话,如:赞,楼主好人等)
- 将所有的语料库的词语的合集的构建出向量
- 将每个文本的词频作为值,构建每个文本的向量的合集(基于词频)
词频向量没有办法体现语义

三、新闻分类任务实战
3.1 数据载入
import pandas as pd
import jieba
df_news = pd.read_table('./data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()#去除空值数据
print(df_news.head())
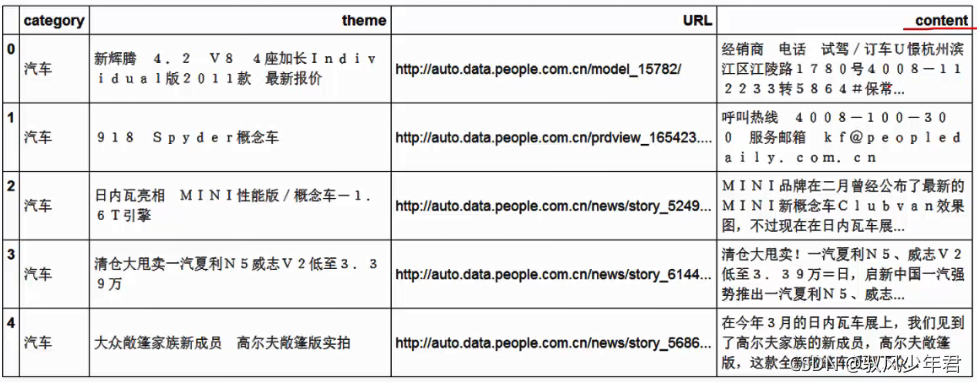
print(df_news.shape)
(5000,4)
3.2 Jieba分词
content = df_news.content.values.tolist()
print (content[1000])
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(C h i e f Da t a
of f i c e r ) ,阿里巴巴
B2B公司CEО陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>范t和6月初的首席风险官职务任命相同,首席数据官亦为阿里巴巴集团在完成与雅虎股权谈判,推进“o n e c o m p a n y ”目标后,在集团决策层面新增的管理岗位。016.镑团昨日表示,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
ontent_S = []
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != '\r\n': #换行符
content_S.append(current_segment)
print(content_S[1000]) #(list of list)
contern_S[1000]
部分输出结果:

转为DataFrame格式
df_content=pd.DataFrame({'content_S':content_S})
print(df_content.head())
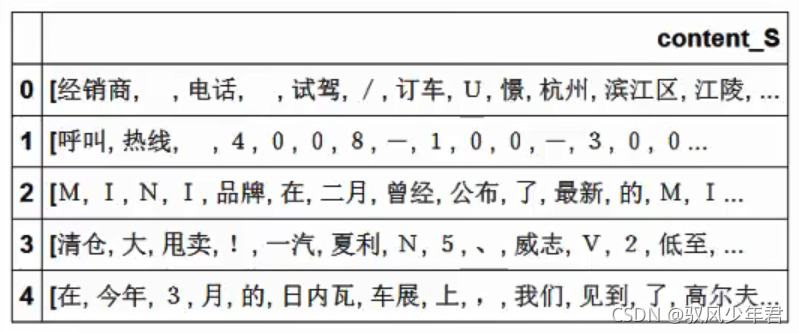
3.3 停用词清洗
停用词表

stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8') #list
print(stopwords.head(20))
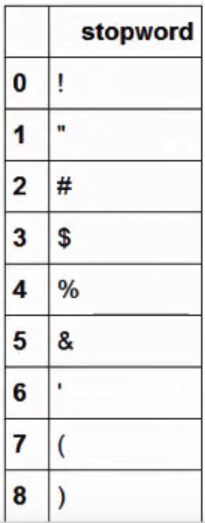
def drop_stopwords(contents, stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean, all_words
# print (contents_clean)
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean, all_words = drop_stopwords(contents, stopwords) ###使用停用词
df_content=pd.DataFrame({'contents_clean':contents_clean}) ##每一列的分词
print(df_content.head())
df_all_words=pd.DataFrame({'all_words':all_words}) ###所有词语
print(df_all_words.head())
df_all_words = pd.DataFrame({"all_words":all_words})
df_all_words.head()
groupby统计所有词中每个词的词频
import numpy
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({"count":numpy.size})##分组大小
print(words_count.head())
words_count=words_count.reset_index()
print(words_count.head())
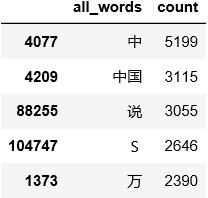
words_count=words_count.sort_values(by=["count"],ascending=False)##排序
print(words_count.head())
3.4 词云
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
plt.show()

3.5 基于Jieba的TFIDF关键词提取
import jieba.analyse
index = 500 #文本的位置索引
print (df_news['content'][index])
content_S_str = "".join(content_S[index])
print (" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))#3输出前五个关键词

3.6 LDA:主题模型
格式要求:list of list形式,分词好的的整个语料
3.6.1 建模
from gensim import corpora, models, similarities
import gensim
#做映射,相当于词袋
dictionary = corpora.Dictionary(contents_clean) ##格式要求:list of list形式,分词好的的整个语料
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean] #语料
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20) #类似Kmeans自己指定K值
print (lda.print_topic(1, topn=5)) ##第一个主题,关键词5个
输出:

3.6.2 输出20个主题的的关键词和权重
for topic in lda.print_topics(num_topics=20, num_words=5):
print (topic[1])
输出:
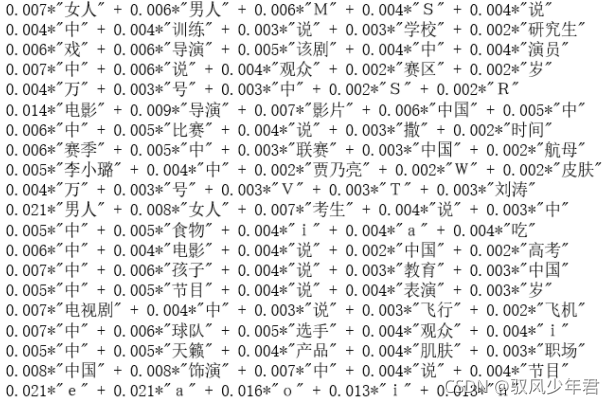
3.7 基于贝叶斯算法的新闻分类器
3.7.1 基于词袋模型的贝叶斯算新闻分类器
3.7.1.0 CounterVectorizer 构建文本向量案例
需要构建list中套着不同文本,逗号隔开传入
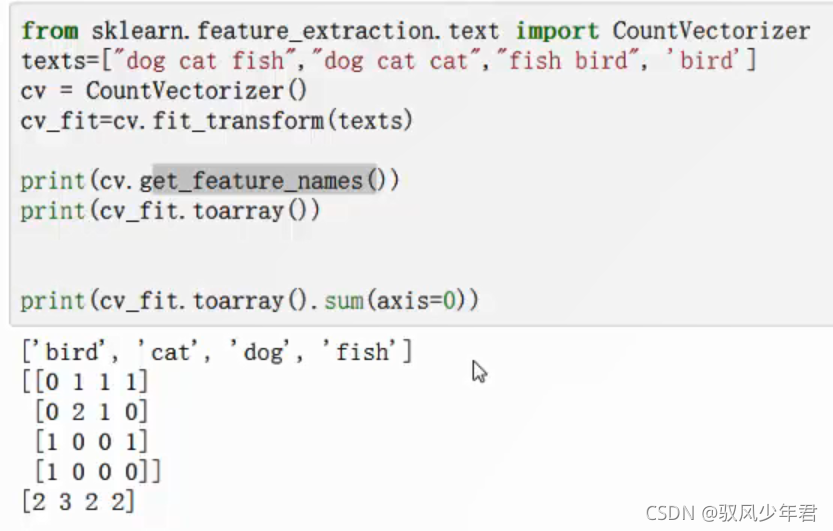
ngram_range参数
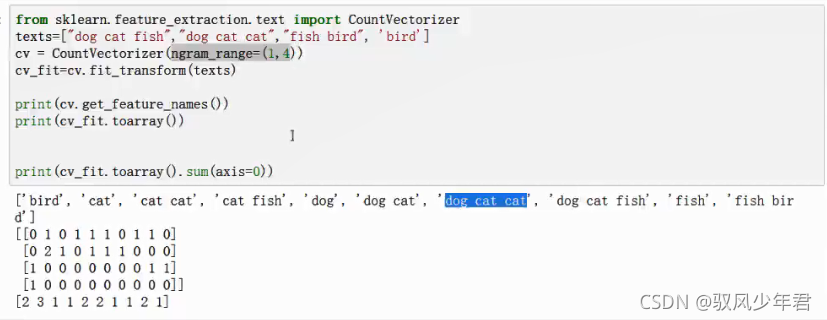
ngram_range参数可以丰富向量模型的维度,可以设置词与词之间的组合,作为一个新的维度,使得原有的维度更高
一般ngram = 2 就行,表示两个两个词之间的组合
3.7.1.1 转换标签数据,与标签编码
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
print(df_train.tail())
print(df_train.label.unique())

pandas中使用map函数转换标签编码
label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
df_train['label'] = df_train['label'].map(label_mapping) ##变换label
print(df_train.head())

3.7.1.2 数据集分割为训练集,测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values, random_state=1)
#print(x_train)
#print(x_train[0])
#x_train = x_train.flatten()
#-------------------------将数据转为CouterVector的要求的一个list中不同文档用“,”隔开的形式---------------
words = []
for line_index in range(len(x_train)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
words.append(' '.join(x_train[line_index]))
except:
print (line_index)
print(words[0])
print (len(words))

3.7.1.3 构建贝叶斯分类器
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
vec.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(words), y_train)
test_words = []
for line_index in range(len(x_test)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
test_words.append(' '.join(x_test[line_index]))
except:
print (line_index)
print('test_words[0]',test_words[0])
print('test_words_sorce',classifier.score(vec.transform(test_words), y_test))

3.7.2 基于TFIDF的新闻分类器
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False)
vectorizer.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vectorizer.transform(words), y_train)
print(classifier.score(vectorizer.transform(test_words), y_test))




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











