







书山有路勤为径,学海无涯苦作舟
一、语言模型
计算机只认识数值,需要将文本数据转为数值的向量矩阵。
比如现在有一句话:我今天下午打篮球。 这一句话具有逻辑性,词语之间具有联系。
先说“我”,在“我”的基础上,出现“今天”的概率,“下午”在"我今天"出现的概率,以此类推,计算出一个句子出现的概率。
每个词出现都与前面的词出现有关系

每个词都与前面的词有关系,但是长句子的话,数据就会更加稀疏。
最后一个词wi出现的概率 = 所有词概率 / 不包含wi的词条件概率

二、N-gram 模型(基于统计)
通常我们说的一个词,通常只与前一个词关系比较大,和前面是很多词关系不大
所以假设下一个词,只依赖其前面的一个词或者只依赖于前面的两个词
N-gram 模型,当指定N = 1,就是与前面的一个词相关,指定N=2就是与前面的两个词相关

计算每个词,和句子的慈祥概率

通常情况下,取得N=2或者N=3 比较常见,N值太大计算太复杂。

三、词向量模型
最简单的one-hot 构建词向量:
- 先构造所有词的集合的一个全为0的一维向量
- 当句子中出现这个词,就在这个词的对应的位置变为1
但是one-hot并不能表达出词之间语义的向量
我们希望构建出来的语言模型,可以表达出语义

我们希望构建出来的词向量模型,不同向量之间如果语义相同,那么这些向量之间的距离相近

我们希望可以寻找离某个词最近的词:

我们希望不同语言的建模下,词语词之间的距离还是相近的,并不与语言挂钩,只有语言逻辑环境相关。

四、基于神经网络模型训练词向量
4.1 词向量的神经网络模型
传统的神经网络只需要优化神经网络之间的参数,词向量的神经网络不仅需要优化参数,还需要优化输入的词向量
输入层:比如输入(我 / 今天 / 下午 ),对三个词进行随机初始化为一个向量的形式,预测下午后面接什么。
投影层: 将三个词输出词向量首尾相连拼接在一起,整体对待
隐藏层与输出同传统的神经网络

训练神经网络就是虚拟词与词之间的逻辑关系,训练样本是前N-1个词,预测第N个词是什么的概率。
所以训练样本就是前N-1个,且假设每个词的向量大小为m
输出:预测N词的概率

4.2 神经网络模型与传统统计模型的比较
统计下,相同含义的词,但是因为出现词频的不同,并不会得到相同的对待
但是神经网络模型,其计算的向量空间,发现,相同含义的词,虽然出现的词频不一样,但是他两的距离还是很近的。


4.3 Hierarchical Softmax(层次化Softmax)
CBOW 根据上下文预测某一个词
Skip-gram 根据一个词预测上下文

Continuous Bag-of-Words Model

4.3.1 哈夫曼树
给树赋予权值代表重要程度,(5,7,2,3)
带权长度 = 权重 * 路径步长
哈夫曼树:将权重最大的放在最前面,以此类推,权重小的放在后面。

比如语料库有1000个词,生活中有些词是常用的,有些词是不常用的。这些词不应该被同等对待,可以将赫夫曼树中的权重转为词的词频。
频率高的词就在哈夫曼树的前面,低频率的就在后面这就是分层的思想:
通过sigmoid函数实现二分类的问题

4.3.2 哈夫曼树的构造
ABCD四个词以及其词频,先将词频最低的两个词合并,再依次向上。
哈夫曼树通常需要判断是往左边还是往右边走的二分类问题,需要通过sigmoid函数进行判断。
哈夫曼树编码:
左边树为0,右边树为1:D(0),B(1,0),C(1,1,0),A(1,1,1,)

4.3.3 哈夫曼树的分类-逻辑回归(Logistic回归)
sigmoid的输入区间是R任意值,输出是0到1之间的值
Θ表示参数矩阵,x为输入。

Softmax是一个多分类的逻辑回归,将多个逻辑回归组合在一起
4.4 CBOW
4.4.1 CBOW的架构


假设往右走是正例,左边是负例。在数据的上下文的词的输出,最后输出要走到“足球“
最终结果的足球的是前面走过路径的累乘

4.4.2 CBOW的模型求解
参数Θ以及输入向量改变和传统的神经网络相同
走过路径的整体概率表达式
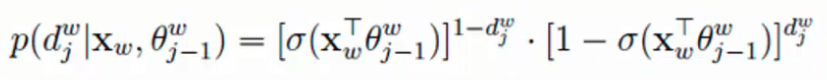
将其带入似然函数中求解
当传入w的上下文,预测值为w的概率值越大越好,传统的似然函数多次累乘不好求解,就将其转换成了一个对数似然函数。log放后面,乘方提前,累乘就变成了累加,
用dw来控制正负例
展开,相乘转为log相加,将次方提前

求L的概率值越大越好的极值点
4.4.3 梯度上升
找极值先求导
对θ求导:
-
合并同类项,得到求导最终结果
-
再梯度上升,在原始的基础上加上更新θ

输入向量X也需要更新,对投影层集合向量X进行求导,更新集合X向量

整体词向量的更新都应用到每个词向量上!
4.5 负采样(Negative Sampling)分类
当语料数据大的时候,利用哈夫曼树虽然常见的词在前,不常见的在后,但是还是很计算复杂还是很高





















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











