







一、因子信号的获取
极值处理与标准化:去除极值,降低极值对于数据的影响
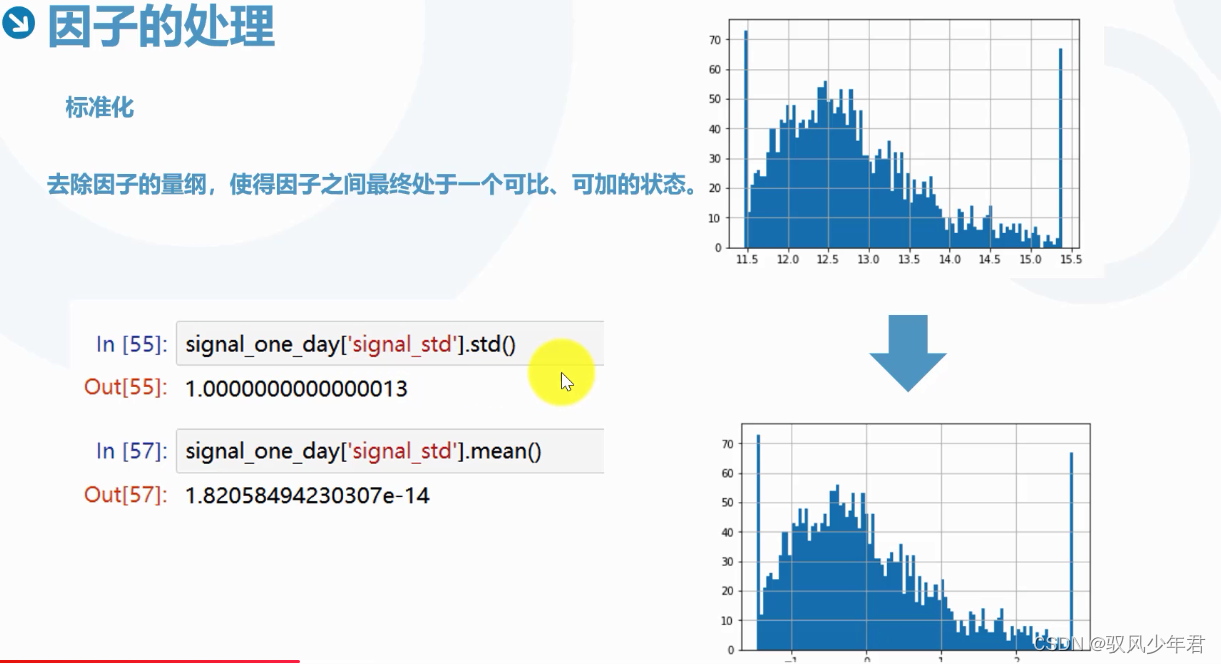
标准化:对不同数据进行同一处理的时候需要同一量纲。这样因子与因子就可以进行计算
极值处理:Triming和Winsorizing,一般因子如果极值是不对的原因造成,这样的因子就不能使用了,就Triming,去除这些不用的因子。Winsorizing:当数据中有因子的极值,这样的因子不是错误的,所以只要Winsorizing,对数据进行压缩一下。
中心化:类似于提纯,取出一个因子中不同因素的影响,对因子进行提纯。
行业中性:提出行业的区别,不局限与行业的影响。

1.1 第一个因子市值原始信号
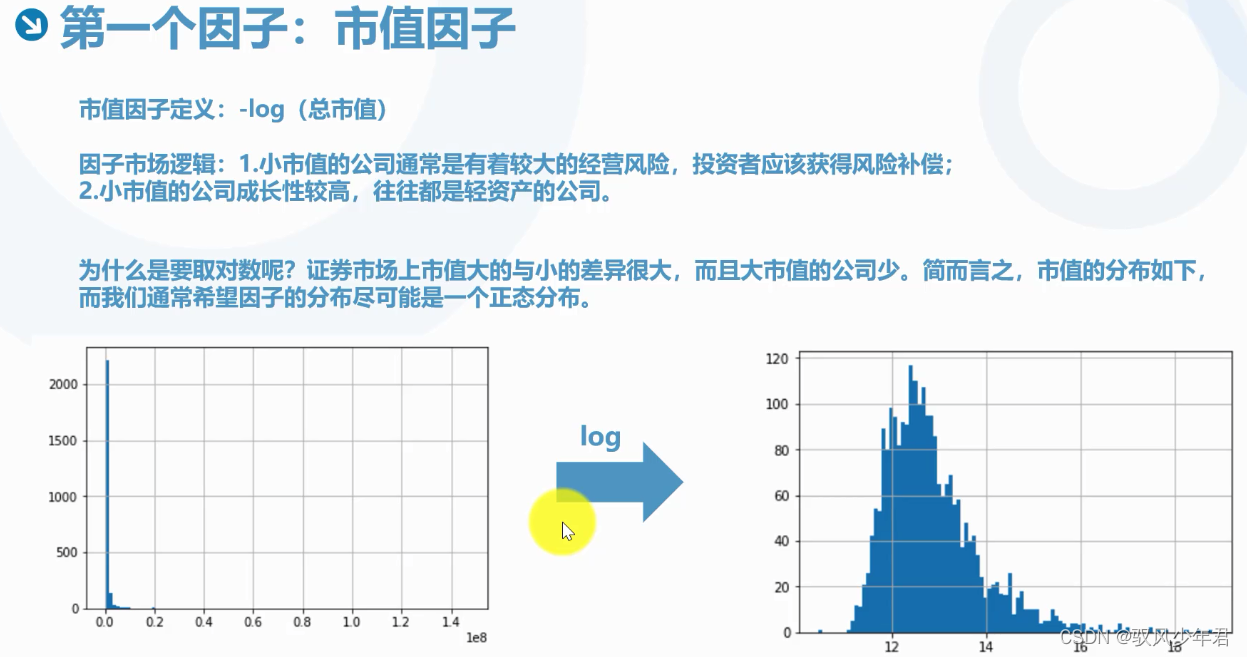
市值因子需要取负的log:
因子市场逻辑: 1.小市值的公司通常是有着较大的经营风险,投资者应该获得风险补偿;
2.小市值的公司成长性较高,往往都是轻资产的公司。
取对数,会使得对数的值越小会越大,所以需要还取一个log。
为什么是要取对数呢?证券市场上市值大的与小的差异很大,而且大市值的公司少。简而言之,市值的分布如下,而我们通常希望因子的分布尽可能是一个正态分布。
1.2 市值因子信号的计算
import pandas as pd
import numpy as np
%matplotlib inline
size_data = pd.read_hdf('../data/demo_tpd.h5')

取出1月22号的所有股票,再取出其市值,再取-log变换。
size_data_one_day = size_data[size_data['data_date'] == '2013-01-22']
size_data_one_day.head()
size_data_one_day['mv'].hist(bins=100)
#取-log变换
size_data['signal_raw'] = -np.log(size_data['mv'])
size_data_one_day = size_data[size_data['data_date'] == '2013-01-22']
size_data_one_day['signal_raw'].hist(bins=100)


保存转换后-log后的市值数据到本地
size_data[['data_date', 'secucode', 'signal_raw']].to_hdf('size_signal_raw.h5', key='data')

二、 因子预处理
2.1 极值处理

windsorized data
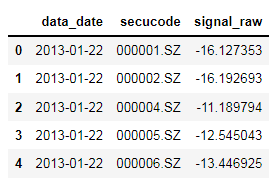
signal = pd.read_hdf('size_signal_raw.h5',key='data')
signal.head()
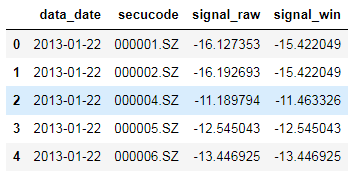
取一天的数据实验一下
signal_one_day = signal[signal['data_date'] == '2013-01-28']
signal_one_day.signal_raw.hist(bins=100)

ceiling = signal_one_day['signal_raw'].quantile(0.975)
floor = signal_one_day['signal_raw'].quantile(0.025)
# 最低的赋值,最高的赋值
signal_one_day['signal_raw'].apply(lambda x:ceiling if x >ceiling else (floor if x < floor else x)).hist(bins = 100)

将上述的过程绘制成函数,对每一天都进行win操作
def winsor(signal_one_day):
ceiling = signal_one_day['signal_raw'].quantile(0.975)
floor = signal_one_day['signal_raw'].quantile(0.025)
signal_one_day.loc[signal_one_day['signal_raw'] >ceiling,'signal_raw'] =ceilling
signal_one_day.loc[signal_one_day['signal_raw'] < floor,'signal_raw'] = floor
return signal_one_day['signal_raw']
signal.sort_values(['data_date','secucode'],inplace=True)
signal['signal_win'] = signal.groupby('data_date').apply(winsor).values
2.2 标准化处理
定义标准化函数
def std(ser):
return (ser - ser.mean())/ser.std()
应用函数标准化数据
signal.sort_values(['data_date','secucode'],inplace=True)
signal['signal_std'] = signal.groupby('data_date')['signal_win'].apply(std)
取出某一天的数据观察标准化情况
signal_one_day = signal[signal['data_date'] == '2013-01-22']
signal_one_day['signal_std'].hist(bins = 100)

signal_one_day['signal_std'].std()
signal_one_day['signal_std'].mean()
0.9999999999999996
-1.9805185359970363e-14
保存计算后的结果
signal[['data_date','secucode','signal_std']].to_hdf('size_signal_final.h5',key='data')















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











