






数据库优化遵循一个漏斗法则,如下图:
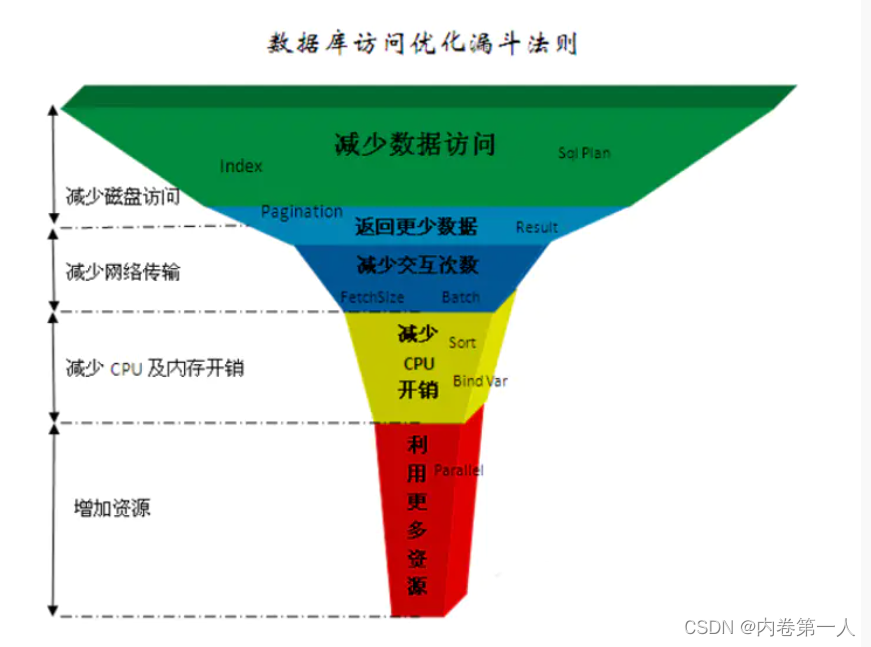
数据库优化的漏斗法则基本可分为5个层次:
- 减少数据访问(减少磁盘访问)
- 索引,减少全表扫描
- 返回更少数据(减少网络传输或磁盘访问)
- 根据实际业务需求返回所需数据
- 减少交互次数(减少网络传输)
- 缓存
- 存储过程
- 批量查询
- 减少服务器CPU开销(减少CPU几内存开销)
- 批量处理
- 在客户端处理大量负责运算
- 利用更多资源(增加资源)
-
硬件资源
-
针对上图我们研究了一个优化的方向:

PS:说一下实际开发中,基本就是sql优化,最多也就是数据库表结构优化(分库分表)
浅谈一下sql优化的思想:
首先当我们的sql语句执行时间达到了3s以上时,是无法接受的,通常都是毫秒级别的响应,我们需要先开启mysql数据库的慢查询日志(需要在mysql的配置文件中进行配置),定位到执行慢的sql语句后,我们针对这条语句使用explain关键字查看它的执行计划,分析一下是不是索引失效导致了全盘扫描。
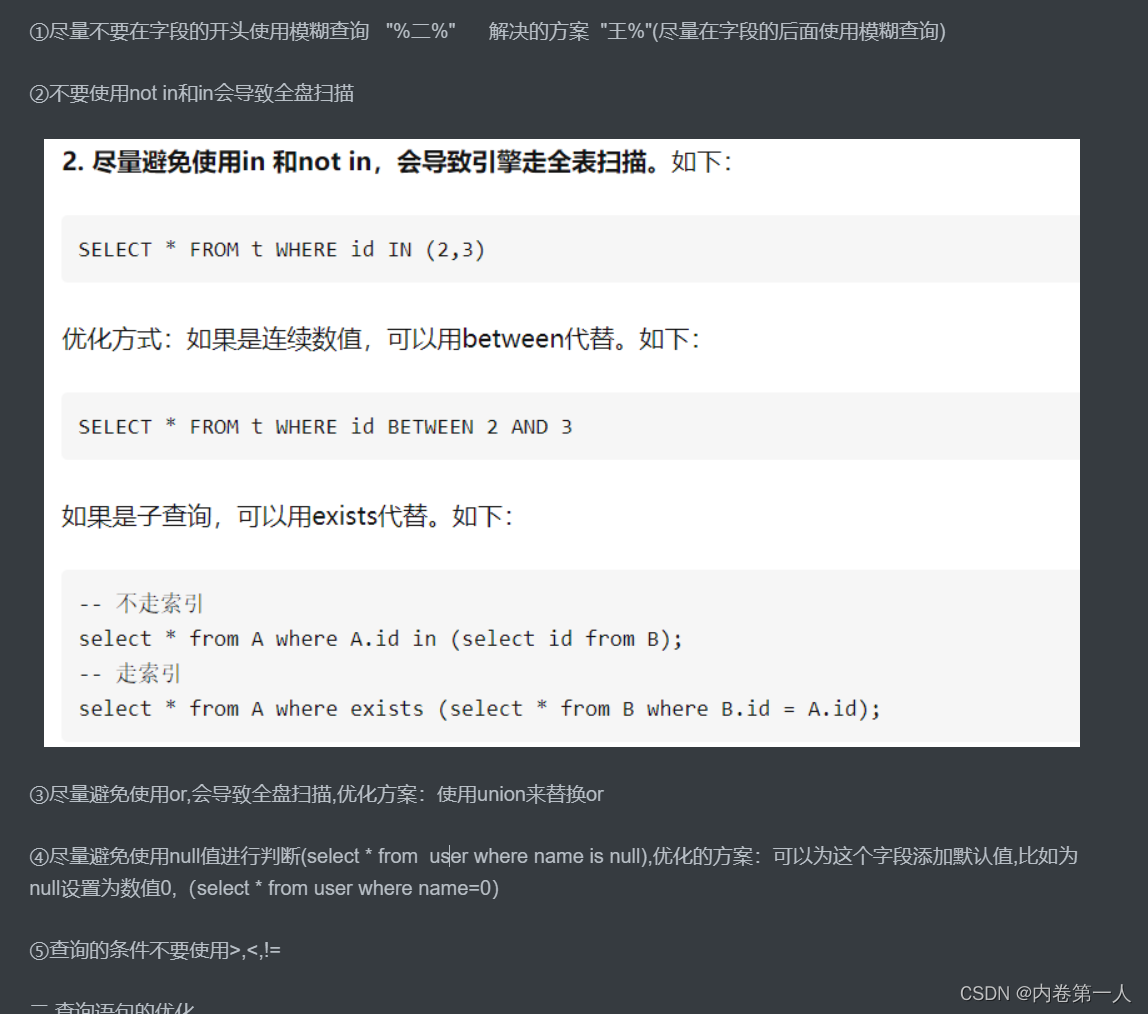
这里列举下常见的索引失效的情况:
再浅谈一下数据库表结构优化(也就是分库分表):
常见的拆分有水平拆分和垂直拆分,但是最多用到水平拆分,我目前没有接触过垂直拆分的情况,下面说一下水平拆分,比如一张订单表,每天都会有大量的数据插入,假设现在有一张表中的数据达到了1000万(理论上mysql单表大于500万条数据, 就需要考虑水平分表, 因为单表数据量越大查询越慢, 查询效率成指数级下降 ),我们将这张表水平拆分,那么就会有个问题就是如何知道自己要去哪一个库中去查数据。
我们使用hash分表的思想(前提需要保证主键为数字),假设将两张表分为100个hash槽,上表为0~49,下表为50~99,假设传入的id为50时,用50/100取余数为50,那么就到下表中去查。
我们也可以可以使用三方的插件,比如mycat,它只不过是帮我们集成了hash分表的思想。















 1527
1527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









