






第三章:栈和队列
3.1 栈的基本概念
栈的定义
- 首先栈本身也是一种线性表
- 但是这种线性表规定了只能在某一端进行插入和删除操作
栈的特点
- 拥有栈顶和栈底
- 栈底是固定的,是不允许进行插入和删除的那一端
- 栈顶是变化的,是允许插入和删除的哪一端
- 栈是一种后进先出的线性表(也叫LIFO结构)\mathrm{C}_n^r
n个不同元素进栈,出栈不同排列的个数为:
(Catalan公式) 1 n + 1 C 2 n n \frac{1}{n+1}\mathrm{C}_{2n}^{n} n+11C2nn
3.2 栈的顺序存储结构
因为本身栈也是线性表的一种,所以当然也会有两种存储结构。
顺序栈的实现
规定:我们的栈顶指针永远指向栈顶元素的下一个位置上
#include <iostream> //C++头文件格式,如果需要可替换成C语言的头文件
using namespace std;
#define stack_init_size 100 //初始容量
#define stack_increment 10 //线性表存储空间
#define error -1
//因为C语言中没有true和false关键字,虽然C++里有但是这里还是额外定义一下
#define FALSE 0
#define TRUE 1
typedef int elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
typedef int status; //因为C语言编译器中一般不存在bool,所以这里的定义相当于C++的bool类型,代表函数返回的状态
typedef struct {
elemtype *base; //用来申请连续的空间的指针,该空间存放栈的数据
elemtype *top; //栈顶指针
int stacksize; //记录当前栈的空间大小,用来方便以后空间不足时申请更多的空间
}sqstack;
status init_stack(sqstack &s){
//初始化一个空栈
s.base=(elemtype *)malloc(stack_init_size * sizeof(elemtype));//申请一段连续的空间
if(!s.base) return(FALSE);//申请空间失败弹出错误信息
s.top=s.base;
s.stacksize=stack_init_size;
return TRUE;
}
status get_top(sqstack &s,elemtype &e){
//若栈不为空,则用e返回s的栈顶元素,并返回TRUE,否则返回FALSE
if (s.top==s.base) {
return FALSE;
}
e=*(s.top-1);//因为是连续的空间,所以栈顶指针所指向的数据地址-1即可得到我们的栈顶元素所在的地方
return TRUE;
}
status push(sqstack &s,elemtype e){
//插入元素e进入栈中,成为新的栈顶元素
if(s.top-s.base>=s.stacksize){
//s.top-s.bace即是栈现在已经存放有数据的空间量
//如果现在栈申请的空间已经不够继续存放数据了,就要重新申请更大的连续空间了
s.base=(elemtype*)realloc(s.base, (s.stacksize+stack_increment)*sizeof(elemtype));
if (!s.base) {
return FALSE;
}
s.top=s.base+s.stacksize; //因为重新申请更大空间后,栈的地址发生了改变,所以栈顶指针所指向的地址也要做相应的更改
s.stacksize+=stack_increment;
}
*s.top++=e; //先用后++
return TRUE;
}
status pop(sqstack &s,elemtype &e){
//如果栈不空,就删除s的栈顶元素,并用e返回栈顶元素的值
if (s.top==s.base) {
return FALSE;
}
e=*(--s.top);
return TRUE;
}
int main() {
sqstack s;
init_stack(s);
return 0;
}
共享栈的实现
共享栈:指的是两个顺序栈共享同一个连续空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸。

共享栈能让存储空间的利用率提高。其存储数据的时间复杂度均为O(1),所以对存取效率没影响。
#include <iostream> //C++头文件格式,如果需要可替换成C语言的头文件
using namespace std;
#define stack_init_size 100 //初始容量
#define error -1
//因为C语言中没有true和false关键字,虽然C++里有但是这里还是额外定义一下
#define FALSE 0
#define TRUE 1
typedef int elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
typedef int status; //因为C语言编译器中一般不存在bool,所以这里的定义相当于C++的bool类型,代表函数返回的状态
typedef struct {
elemtype *base;//用来申请数据空间的指针
elemtype *top[2];//两个共享栈的栈顶指针
int stacksize;
} sharestack;
status init_stack(sharestack &s){
//初始化一个空栈
s.base=(elemtype *)malloc(stack_init_size * sizeof(elemtype));//申请一段连续的空间
if(!s.base) return(FALSE);//申请空间失败弹出错误信息
s.top[0]=s.base;
s.stacksize=stack_init_size;
s.top[1]=s.base+s.stacksize-1;
return TRUE;
}
status get_top(sharestack &s,elemtype &e,int number){
//number是栈的编号,0号栈代表栈底在空间开头的栈,1号栈代表栈底在空间结尾的栈
//若栈不为空,则用e返回s的栈顶元素,并返回TRUE,否则返回FALSE
switch (number) {
case 0:
if (s.top[number]==s.base) {
//0号栈是空的
return FALSE;
}
e=*(s.top[number]-1);
break;
case 1:
if (s.top[number]==s.base+s.stacksize-1) {
//1号栈是空的
return FALSE;
}
e=*(s.top[number]+1);
break;
default:
printf("%s","编号错误,无法执行函数");
return FALSE;
break;
}
return TRUE;
}
status push(sharestack &s,elemtype e,int number){
//插入元素e进入栈中,成为新的栈顶元素
if(s.top[0]-s.top[1]==1){
//在这里注意我们的栈顶指针规定指向的是下一个空间,所以栈满的时候s[0]-s[1]=1
//如果现在栈申请的空间已经不够继续存放数据了,就要重新申请更大的连续空间了
//这里要注意不能像正常的顺序栈一样,直接用realloc增加空间,因为1号栈的数值不是简单的复制
//搬运时应该注意1号栈的栈底与多出的空间距离,将1号栈的所有数值集体挪动才行,在这里不再贴出代码
printf("%s","申请的栈空间不足");
return FALSE;
}
switch (number) {
case 0:
*(s.top[number]++)=e; //先用后++
break;
case 1:
*(s.top[number]--)=e;
break;
default:
printf("%s","编号错误,无法执行函数");
return FALSE;
break;
}
return TRUE;
}
status pop(sharestack &s,elemtype &e,int number){
//如果栈不空,就删除s的栈顶元素,并用e返回栈顶元素的值
switch (number) {
case 0:
if (s.top[number]==s.base) {
//0号栈是空的
return FALSE;
}
e=*(--s.top[number]);
break;
case 1:
if (s.top[number]==s.base+s.stacksize-1) {
//1号栈是空的
return FALSE;
}
e=*(++s.top[number]);
break;
default:
printf("%s","编号错误,无法执行函数");
return FALSE;
break;
}
return TRUE;
}
status stack_empty(sharestack s,int number){
//若栈S为空栈,返回TRUE,否则返回FALSE
switch (number) {
case 0:
if (s.top[number]==s.base) {
//0号栈是空的
return TRUE;
}
break;
case 1:
if (s.top[number]==s.base+s.stacksize-1) {
//1号栈是空的
return TRUE;
}
break;
default:
printf("%s","编号错误,无法执行函数");
return FALSE;
break;
}
return FALSE;
}
int main() {
sharestack s;
init_stack(s);
return 0;
}
3.3 栈的链式存储结构
链栈的实现
注意:因为栈的后进先出的特性,所以为了方便使用链栈和链表的起点指针有一点点不一样。
为了方便顺序读取数据,链表中的起点指针需要一直待在头结点。
而由于栈读取一般只能读栈顶,所以考虑到读取效率,链表的起点指针应该作为栈顶指针使用,也就是需要随着栈顶的位置变化而变化。

#include <iostream> //C++头文件格式,如果需要可替换成C语言的头文件
using namespace std;
#include <string.h>
#include <cstring>
#include <string>
#define stack_init_size 100 //初始容量
#define stack_increment 10 //线性表存储空间
#define error -1
//因为C语言中没有true和false关键字,虽然C++里有但是这里还是额外定义一下
#define FALSE 0
#define TRUE 1
typedef char elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
typedef int status; //因为C语言编译器中一般不存在bool,所以这里的定义相当于C++的bool类型,代表函数返回的状态
typedef struct stacknode{
elemtype data;//结点数据
struct stacknode *next;//记录下个结点地址的指针
} stacknode,*linkstack;
status init_stack(linkstack &s){
s=(linkstack)malloc(sizeof(stacknode));//申请头结点
s->next=NULL;
return TRUE;
}
status get_top(linkstack &s,elemtype &e){
//若栈不为空,则用e返回s的栈顶元素,并返回TRUE,否则返回FALSE
if (s->next==NULL) {
//s里面没有存放如何数据
return FALSE;
}
//注意i最好跳过头结点
e=s->data;
return TRUE;
}
status push(linkstack &s,elemtype e){
//插入元素e进入栈中,成为新的栈顶元素
stacknode *node=(linkstack)malloc(sizeof(stacknode));//申请一个新的结点
node->data=e;
node->next=s;
s=node;
return TRUE;
}
status pop(linkstack &s,elemtype &e){
//如果栈不空,就删除s的栈顶元素,并用e返回栈顶元素的值
if (s->next==NULL) {
//s里面没有存放如何数据
return FALSE;
}
e=s->data;
stacknode *t=s;
s=t->next;
free(t);
return TRUE;
}
status stack_empty(linkstack s){
if(s->next==NULL)
return TRUE;
else
return FALSE;
}
status destroy_stack(linkstack s){
stacknode *p=s;
while (p!=NULL) {
s=s->next;
free(p);
p=s;
}
return TRUE;
}
int main() {
linkstack s;
init_stack(s);
return 0;
}
3.4 队列的基本概念
队列的定义
- 队列也是一种操作受限的线性表
- 队列只允许在表的一端进行插入,而在表的另一端进行删除。
队列的特点
- 先进先出。
- 队头是允许删除的那一端,又称为队首
- 队尾是允许插入的一端。
3.5 队列的顺序存储结构
队列的顺序存储结构照例可以参照线性表的顺序存储结构,都是分配一块连续的存储单元来存放队列中的元素,不过多增加了两个指针:
队头指针front:指向队头元素
队尾指针rear:指向队尾元素的下一个位置
注意:在顺序队列中,一般我们都是讨论的顺序循环队列
原因:如下图,如果不做循环队列,会出现“上溢出”的情况

循环队列:把顺序队列在逻辑结构上构成一个环状的空间,以此来解决“上溢出”的问题。当队首指针q.front=maxsize-1后,再进一个位置就自动回0。如下图所示:

从上图也可以知道,循环队列虽然可以完美解决“上溢出”问题,但也衍生出了一个新问题,就是判断队空和队满的问题,为了解决这个问题,我们有三种处理方式:
1)牺牲一个单元来区分队空和队满,入队时少用一个队列单元,约定以“队头指针在队尾指针的下一个位置作为队满的标志”,这也是一个较为普遍的做法。
2)在结构体中增加一个表示元素个数的数据成员。
3)在结构体中增设tag数据成员,tag用来标记你上一次所进行的操作,如果tag==0,代表上一次的操作是删除,则这时候的q.front == q.rear所代表的就必是队空了。如果tag ==1,代表上一次的操作是插入,则这时候的q.front ==q.rear就必为队满。
顺序队列的实现(顺序循环队列)
#include <iostream> //C++头文件格式,如果需要可替换成C语言的头文件
using namespace std;
#define MAXQSIZE 10 //初始容量
#define error -1
//因为C语言中没有true和false关键字,虽然C++里有但是这里还是额外定义一下
#define FALSE 0
#define TRUE 1
typedef int elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
typedef int status; //因为C语言编译器中一般不存在bool,所以这里的定义相当于C++的bool类型,代表函数返回的状态
typedef struct {
elemtype *base;//用来申请数据空间的指针
int front;//指向队头元素的指针
int rear;//指向队尾元素的下一个位置
} SqQueue;
status init_queue(SqQueue &q){
//初始化一个空栈
q.base=(elemtype *)malloc(MAXQSIZE * sizeof(elemtype));//申请一段连续的空间
if(!q.base) return(FALSE);//申请空间失败弹出错误信息
q.front=q.rear=0;
return TRUE;
}
status queue_empty(SqQueue &q){
//判断队列是否为空,如果为空返回true,否则返回false
if(q.front==q.rear){
return true;
}
return false;
}
status enqueue(SqQueue &q,elemtype e){
//插入元素e为q的新的队列元素
if ((q.rear+1)%MAXQSIZE==q.front) {
//如果队满了
return error;
}
q.base[q.rear]=e;
q.rear=(q.rear+1)%MAXQSIZE;
return TRUE;
}
status dequeue(SqQueue &q,elemtype &e){
if (q.rear==q.front) {
//如果队空
return error;
}
e=q.base[q.front];
q.front=(q.front+1)%MAXQSIZE;
return TRUE;
}
int main() {
SqQueue q;
init_queue(q);
return 0;
}
3.6 队列的链式存储结构
链队列实际上是一个同时带有队头指针和队尾指针的单链表。头指针指向队头结点,不过尾指针和顺序队列有一点点不同,它直接指向队尾结点。
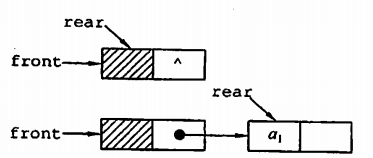
链队列的实现
主要我们在这里实现的链表都是带头结点的,为啥要带头结点可以看一下下面网友们的解释:
为何链表要有头结点?
#include <iostream> //C++头文件格式,如果需要可替换成C语言的头文件
using namespace std;
#define error -1
//因为C语言中没有true和false关键字,虽然C++里有但是这里还是额外定义一下
#define FALSE 0
#define TRUE 1
typedef int elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
typedef int status; //因为C语言编译器中一般不存在bool,所以这里的定义相当于C++的bool类型,代表函数返回的状态
typedef struct QNode{
elemtype data;
struct QNode *next;
} QNode,*QueuePtr;
typedef struct{
QueuePtr front,rear;
} LinkQueue;
status init_queue(LinkQueue &q){
//带头结点的初始化
q.front=q.rear=(QueuePtr)malloc(sizeof(sizeof(QNode)));
if (!q.front) {
return error;
}
q.front->next=NULL;
return TRUE;
}
status queue_empty(LinkQueue q){
if(q.front==q.rear){
return TRUE;
}
return FALSE;
}
status destroy_queue(LinkQueue &q){
//销毁队列
while (q.front) {
q.rear=q.front->next;
free(q.front);
q.front=q.rear;
}
return TRUE;
}
status enqueue(LinkQueue &q,elemtype e){
//插入元素e为q的新队尾元素
QNode *p=(QueuePtr)malloc(sizeof(QNode));
if(!p) return error;
p->next=NULL;
p->data=e;
q.rear->next=p;
q.rear=p;
return TRUE;
}
status dequeue(LinkQueue &q,elemtype &e){
//如果队列不空,则删除q的队头元素,用e返回其值
if (q.front==q.rear) {
//空队列
return error;
}
QNode *p=q.front->next;
e=p->data;
q.front->next=p->next;
if (q.rear==p) {
//如果要释放的是这个元素是队尾元素,还要额外的更改队尾指针;
q.rear=q.front;
}
free(p);
return TRUE;
}
int main() {
LinkQueue q;
init_queue(q);
return 0;
}
3.7 双端队列
双端队列:是指允许两端都可以进行入队和出队操作的队列,将队列的两端称为前端和后端。

输出受限的双端队列:允许在一端进行插入和删除,但在另一端只允许插入的双端队列称为输出受限的双端队列。

输入受限的双端队列:允许在一端进行插入和删除,但在另一端只允许删除的双端队列称为输入受限的双端队列。

这里是引用
3.8 栈和队列的应用
栈在括号匹配中的应用
假设表达式中允许包含两种括号:圆括号和方括号。现在将括号的左部和右部匹配起来。
考虑下列的括号序列:
| [ | ( | [ | ] | [ | ] | ) | ] |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
解决这个问题的思路是:
1)设置一个空栈,并开始按顺序遍历序列。
2)如果是左括号则直接入栈中。
3)如果是右括号,则检查栈顶的左括号是否匹配,如果不匹配则格式错误;如果匹配则,出栈一次;如果匹配到最后栈仍存在左括号,则格式出错。
具体代码如下:
status myfunction(string str){
//匹配输入的str中的括号
elemtype c,e;
linkstack s;
init_stack(s);
for (int i=0; i<str.length(); i++) {
c=str[i];
if (c=='['||c=='(') {
push(s, c);
}
if (c==']') {
get_top(s, e);
if(e!='['){
printf("格式错误!\n");
return error;
}
pop(s, e);
}
if (c==')') {
get_top(s, e);
if(e!='('){
printf("格式错误!\n");
return error;
}
pop(s, e);
}
}
if(stack_empty(s)){
destroy_stack(s);
printf("匹配成功!\n");
return TRUE;
}
else{
destroy_stack(s);
printf("匹配失败!\n");
return FALSE;
}
}
栈在表达式求值中的应用
用栈处理表达式求值问题。例如表达式:
(中缀表达式) 12 + 3 - 4 * ( ( 6 + 16 ) / 2 - 4 ) + 32
我们需要利用栈处理这个表达式获得求得其值。
思路如下:
我们需要将中缀表达式化成后缀表达式
(后缀表达式)12 3 + 4 6 16 + 2 / 4 - * - 32 +
我们仔细观察这个后缀表达式,发现顺序扫描后缀表达式的每一项:
1、如果该项是操作数,就将其压入栈中;
2、如果该项是操作符,就从栈中取出两个操作数,进行相应的运算后,将结果重新压入栈中。
3、最终结束,栈顶所存放的就是最后的计算结果。
现在还有一个问题,我们要怎么将这个中缀表达式转化成后缀表达式?
在这里我们要引入一张操作符优先级表,在读取到操作符时,我们需要查表,然后根据表的优先级序列,来进行入栈或者出栈输入的操作。
1、如果读取到操作符,我们需要将栈顶操作符和读取到的操作符优先级比较;
2、如果读取到操作数,直接输出,并读取下一个字符
优先级比较规则如下:
2、如果栈内的操作符优先级高,则直接输出栈内操作符,并退栈;
3、如果栈外的操作符优先级高,则将栈外操作符入栈,读取下一个字符;
4、如果优先级相等,则直接不输出,退栈并读取下一个字符;
在这里规定,表示式的输入由#号开始,#号结束
| 操作符 | # | ( | * , / | + , - | ) |
|---|---|---|---|---|---|
| isp(栈内优先级) | 0 | 1 | 5 | 3 | 6 |
| icp(栈外优先级) | 0 | 6 | 4 | 2 | 1 |
在这里的代码实现就不用真正的表达式了,因为带数字的字符串处理成数值还是有点麻烦的,用字母代替数字,并且在这里不在讨论从后缀表达式再转化到计算步骤,实现也比较简单,通过前文所讲到的思路实现即可。
status myfunction(string str){
//输入的中缀表达式str,输出后缀表达式
cout<<"后缀表达式:";
linkstack s;
init_stack(s);
push(s,str[0]);//把表达式开头的#号输入
for (int i=1; i<str.length(); ) {
int isp=-1;
int icp=-1;
elemtype c=str[i];
elemtype e=c;
for(int j=0;j<7;j++){
if (priority_sign[0][j]==c) {
//记录读取到的操作符的优先级
icp=priority_sign[2][j];
break;
}
}
if(icp==-1){
//如果读取到操作数,则直接输出
cout<<c;
i++;
continue;
}
get_top(s, e);
for(int j=0;j<7;j++){
if (priority_sign[0][j]==e) {
//记录栈顶的操作符的优先级
isp=priority_sign[1][j];
break;
}
}
if(isp>icp){
//栈内比栈外的优先级高,则输出栈内操作符
pop(s,e);
cout<<e;
//当前读取到的字符还需要进行一下轮的比较
}
else if(isp<icp){
//栈外比栈内的优先级高,则将读到的操作符入栈
push(s, c);
i++;
}
else{
//如果优先级相等,则直接不输出,退栈读取下一个字符
pop(s, e);
i++;
}
}
cout<<endl;
return TRUE;
}
栈在递归中的应用
总所周知,其实C语言中有函数调用函数的写法,其实就是系统开了一个栈来存放当前的函数A状态,然后在这个基础上新开一个函数B,等新开的函数B结束时,系统再读取栈中存放的函数A的状态,进行一个状态恢复,然后再继续执行函数A。
递归也是这样的。无非就是函数A和B都是同一套代码而已。所以我们在想要使用递归的思想,但又不想采用递归的算法,可以利用栈来实现非递归算法的转变,它的算法思想的实质其实也是保存当前函数状态。
值得注意的是由于递归算法的栈是由系统自己开的,所以会存下很多没有必要的状态,所以如果用自己开设的栈,将递归算法转成非递归算法,效率通常会高一些。
举个例题:利用栈来实现以下递归算法的非递归运算
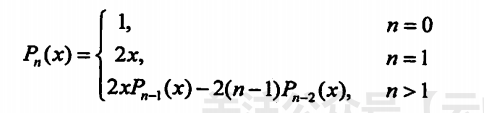
struct P{
int n;
double value;
};
typedef P elemtype; //定义数据元素类型,这样做的好处是想要修改类型时只需修改这句话就可以了
double Myfunction(double x,int n){
linkstack s;
init_stack(s);
for(int i=n;i-2>=0;i--)
{
elemtype e;
e.n=i;
push(s,e);//将需要递归出结果的Pn放入栈中
}
double val1,val2;
val2=2*x;
val1=1;
while(!stack_empty(s)){
//将递归最底层的Pn开始计算
elemtype e;
get_top(s, e);
val1=val1*2*(e.n-1);
val2=val2*2*x;
e.value=val2-val1;
val1=val2;//因为公式的第一项是需要二次使用的,逐一留值
val2=e.value;
pop(s,e);//将已经不需要使用的Pn剔除栈
}
if(n==0)return val1;
return val2;
}
int main() {
cout<<Myfunction(5, 3);
return 0;
}
队列在层次遍历中的应用
这在学到二叉树的时候再详细讨论。
队列在计算机系统中的应用
队列其实在计算机系统应用非常广泛,我们在这里举两个方面的例子:第一个方面是解决主机与外部设备之间速度不匹配的问题,第二个方面是解决由多用户引起得资源竞争问题。
这两个方面在以后学习计算机系统的时候会有详细解释,现在只是做一个提及。














 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









