






自定义数据集训练
首先我们使用coco128数据集进行训练,如下图所示在官网下载数据集,可能要用账号注册后才能下载,因此我将数据集和之后需要创建并制作完成的datasets文件夹上传到GitHub上,需要的自取。
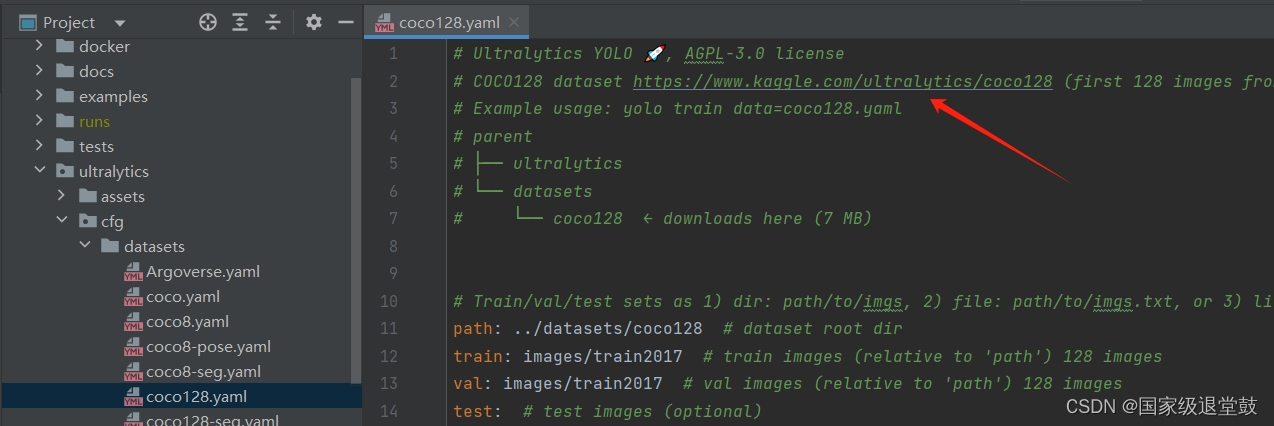
可以将git里的datasets文件复制到源码路径处,修改data.yalm里对应文件的文件路径即可可跳过下面的划分数据集,直接进行训练。
1-1 数据集制作
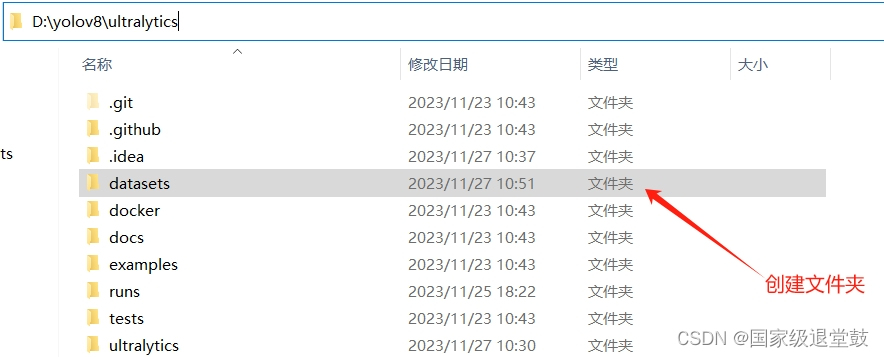
依次在datasets文件夹中创建若干文件,布局为
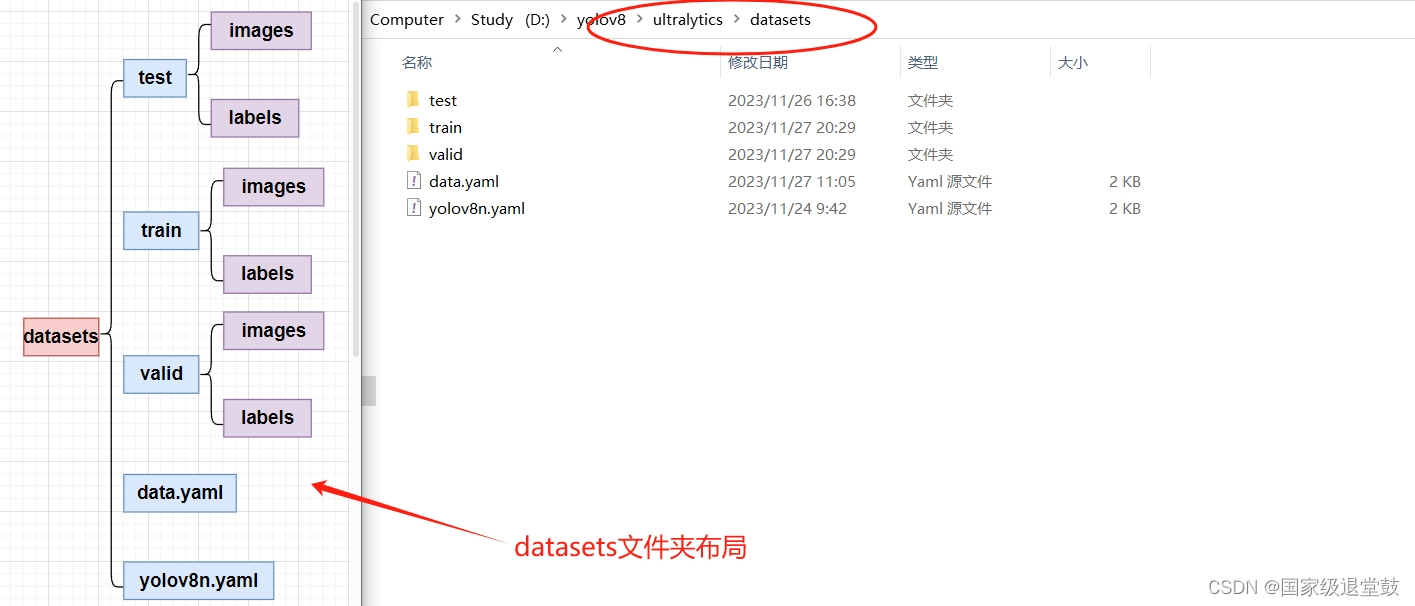
其中ylov8n.yaml文件复制下图路径下的yolov8.yaml即可

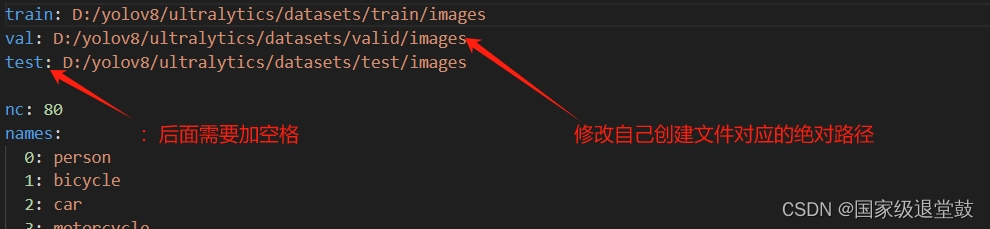
data.yaml里修改对应test、train、valid三个之前创建文件夹的绝对路径
nc为对应coco128.yaml的类别数,复制coco128.yaml的names:类别
最终为结果为
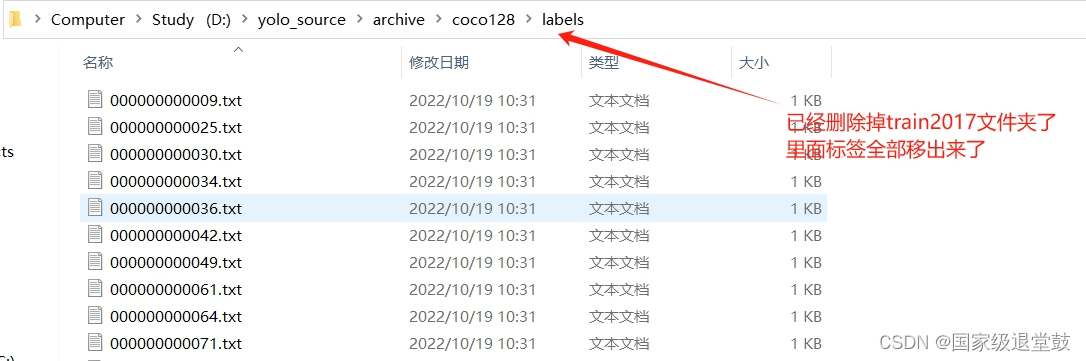
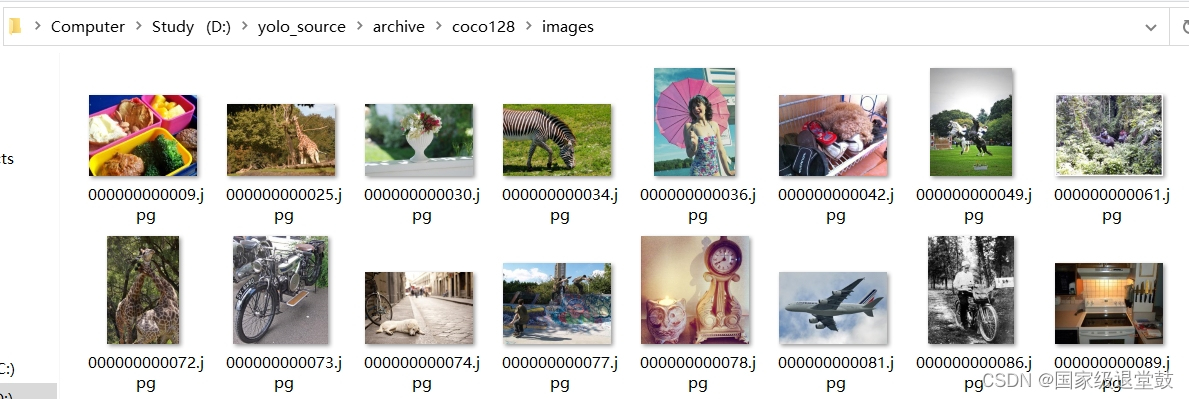
在对应coco数据集的文件中,先将2个文件删除。分别在images、labels文件夹中的train2017里的图片和标签拷贝(Ctrl+A 全选然后Ctrl+C复制)到和train2017文件名同一级目录,最后删除掉train2017文件夹。
效果如下图

1-2 划分数据集
这里借鉴了b站up主奥怪的代码进行python脚本划分数据集,网上大部分数据集划分脚本只能划分.jpg格式的图片,所以使用起来比较坑。
在源代码里创建一个py文件,并输入以下代码
import os
import random
from tqdm import tqdm
# 指定 images 文件夹路径
image_dir = "D:/yolov8/archive/coco128/images" #修改处1 修改对应数据集文件地址 注意路径是'/'
# 指定 labels 文件夹路径
label_dir = "D:/yolov8/archive/coco128/labels" #修改处2
# 创建一个空列表来存储有效图片的路径
valid_images = []
# 创建一个空列表来存储有效 label 的路径
valid_labels = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
# 获取图片的完整路径
image_path = os.path.join(image_dir, image_name)
# 获取图片文件的扩展名
ext = os.path.splitext(image_name)[-1]
# 根据扩展名替换成对应的 label 文件名
label_name = image_name.replace(ext, ".txt")
# 获取对应 label 的完整路径
label_path = os.path.join(label_dir, label_name)
# 判断 label 是否存在
if not os.path.exists(label_path):
# 删除图片
os.remove(image_path)
print("deleted:", image_path)
else:
# 将图片路径添加到列表中
valid_images.append(image_path)
# 将label路径添加到列表中
valid_labels.append(label_path)
# print("valid:", image_path, label_path)
# 遍历每个有效图片路径
for i in tqdm(range(len(valid_images))):
image_path = valid_images[i]
label_path = valid_labels[i]
# 随机生成一个概率
r = random.random()
# 判断图片应该移动到哪个文件夹
# train:valid:test = 7:2:1
if r < 0.1:
# 移动到 test 文件夹
destination = "D:/yolov8/ultralytics/datasets/test" #修改处3 制作的datasets的文件夹的路径
elif r < 0.2:
# 移动到 valid 文件夹
destination = "D:/yolov8/ultralytics/datasets/valid" #修改处4
else:
# 移动到 train 文件夹
destination = "D:/yolov8/ultralytics/datasets/train" #修改处5
# 生成目标文件夹中图片的新路径
image_destination_path = os.path.join(destination, "images", os.path.basename(image_path))
# 移动图片到目标文件夹
os.rename(image_path, image_destination_path)
# 生成目标文件夹中 label 的新路径
label_destination_path = os.path.join(destination, "labels", os.path.basename(label_path))
# 移动 label 到目标文件夹
os.rename(label_path, label_destination_path)
print("valid images:", valid_images)
# 输出有效label路径列表
print("valid labels:", valid_labels)
点击运行后,就可以在dataset文件夹的test、train、valid文件中得到按照一定比例划分的数据集和标签
1-3 数据集训练
在终端处输入训练命令,开始训练
yolo task=detect mode=train model=datasets/yolov8n.yaml data=datasets/data.yaml epochs=100 imgsz=640 resume=True workers=2

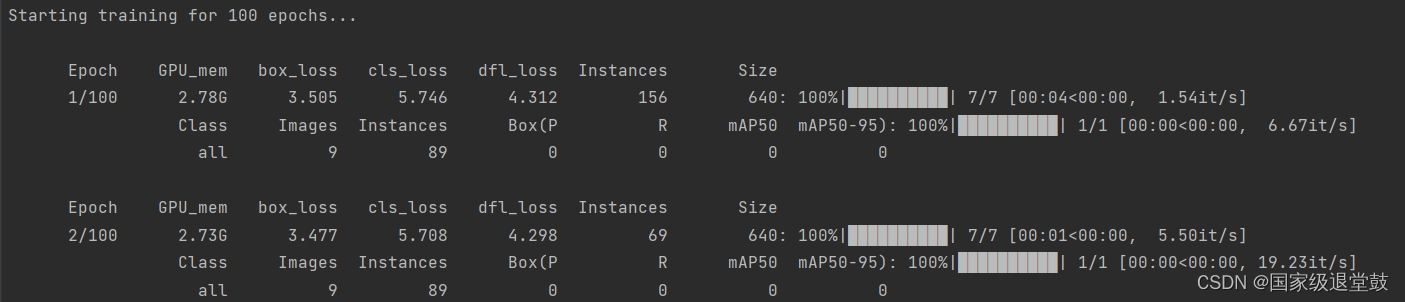
当我们选择resume=True时,可以在终端进行Ctrl+c暂停

当我们需要继续训练时,在run文件夹下找到最后一次训练的权重last.pt复制路径
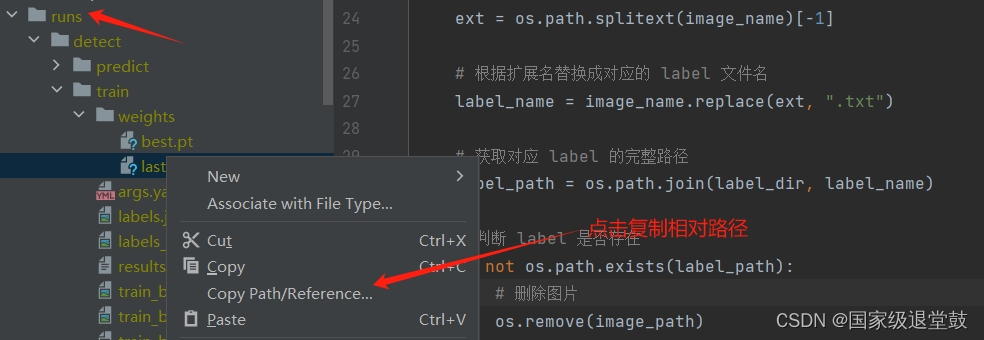
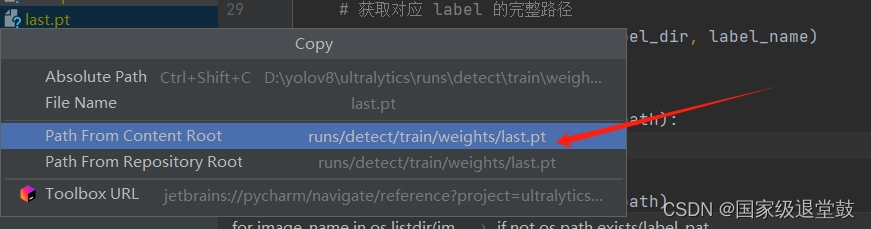
输入断训指令后,可继续训练
yolo task=detect mode=train model=runs/detect/train/weights/last.pt epochs=100 imgsz=640 resume=True workers=2

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









