









目录
一、基础操作
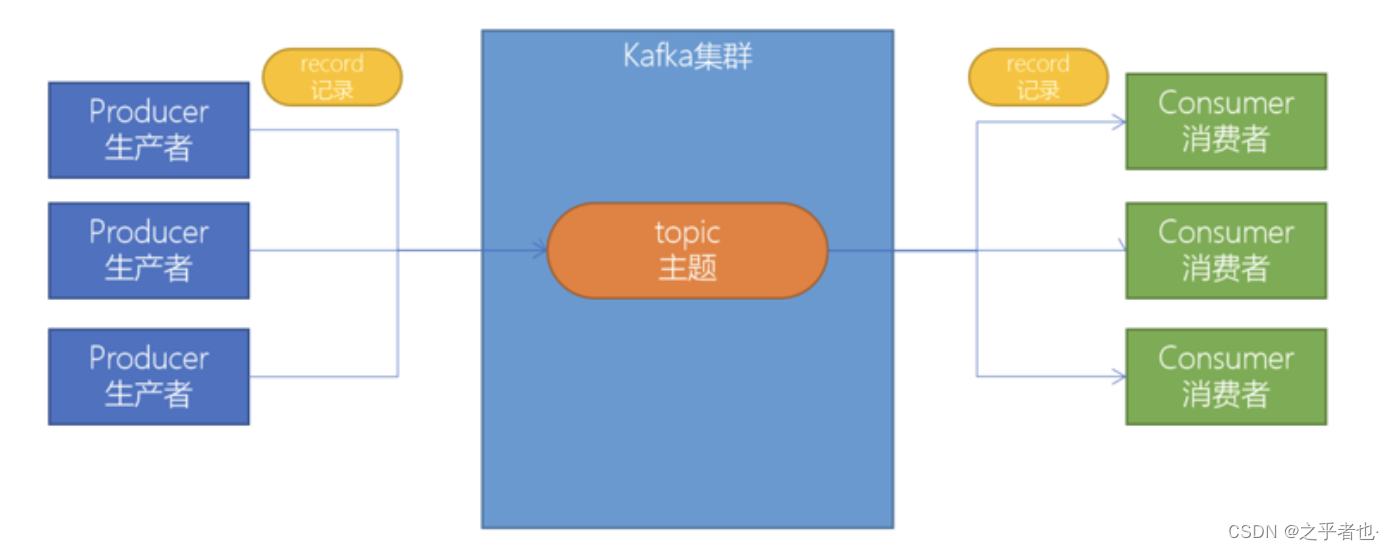
1.1、创建topic
创建一个topic(主题)。Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server node1.angyan.cn:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server node1.angyan.cn:9092
1.2、生产消息到Kafka
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中。
bin/kafka-console-producer.sh --broker-list node1.angyan.cn:9092 --topic test
1.3、从Kafka消费消息
使用下面的命令来消费 test 主题中的消息。
bin/kafka-console-consumer.sh --bootstrap-server node1.angyan.cn:9092 --topic test --from-beginning
1.4、使用Kafka Tools操作Kafka
- 安装Kafka集群,可以测试以下
- 创建一个topic主题(消息都是存放在topic中,类似mysql建表的过程)
- 基于kafka的内置测试生产者脚本来读取标准输入(键盘输入)的数据,并放入到topic中
- 基于kafka的内置测试消费者脚本来消费topic中的数据
- 推荐大家开发的使用Kafka Tool
- 浏览Kafka集群节点、多少个topic、多少个分区
- 创建topic/删除topic
- 浏览ZooKeeper中的数据
二、Kafka基准测试
2.1、基准测试
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。我们可以通过基准测试,了解到软件、硬件的性能水平。主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
2.1.1、基于1个分区1个副本的基准测试
测试步骤:
- 启动Kafka集群
- 创建一个1个分区1个副本的topic: benchmark
- 同时运行生产者、消费者基准测试程序
- 观察结果
2.1.1.1、创建topic
bin/kafka-topics.sh --zookeeper node1.angyan.cn:2181 --create --topic benchmark --partitions 1 --replication-factor 1
2.1.1.2、生产消息基准测试
在生产环境中,推荐使用生产5000W消息,这样会性能数据会更准确些。为了方便测试,课程上演示测试500W的消息作为基准测试。
bin/kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1.angyan.cn:9092,node2.angyan.cn:9092,node3.angyan.cn:9092 acks=1
bin/kafka-producer-perf-test.sh
--topic topic的名字
--num-records 总共指定生产数据量(默认5000W)
--throughput 指定吞吐量——限流(-1不指定)
--record-size record数据大小(字节)
--producer-props bootstrap.servers=192.168.1.20:9092,192.168.1.21:9092,192.168.1.22:9092 acks=1 指定Kafka集群地址,ACK模式
2.1.1.3、消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list node1.angyan.cn:9092,node2.angyan.cn:9092,node3.angyan.cn:9092 --topic benchmark --fetch-size 1048576 --messages 5000000
bin/kafka-consumer-perf-test.sh
--broker-list 指定kafka集群地址
--topic 指定topic的名称
--fetch-size 每次拉取的数据大小
--messages 总共要消费的消息个数
三、Java编程操作Kafka
3.1、同步生产消息到Kafka中
3.1.1、需求
接下来,我们将编写Java程序,将1-100的数字消息写入到Kafka中。
3.1.2、准备工作
3.1.2.1、导入Maven Kafka POM依赖
<repositories><!-- 代码库 -->
<repository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- kafka客户端工具 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<!-- SLF桥接LOG4J日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.6</version>
</dependency>
<!-- SLOG4J日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
3.1.2.2、导入log4j.properties
将log4j.properties配置文件放入到resources文件夹中
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
3.1.2.3、创建包和类
创建包cn.angyan.kafka,并创建KafkaProducerTest类。
3.1.3、开发步骤
- 创建用于连接Kafka的Properties配置
- 创建一个生产者对象KafkaProducer
- 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
- 再调用一个Future.get()方法等待响应
- 关闭生产者
3.1.4、代码开发
必要参数配置
public static Properties initConfig() {
Properties props = new Properties();
// 该属性指定 brokers 的地址清单,格式为 host:port。清单里不需要包含所有的 broker地址,
// 生产者会从给定的 broker 里查找到其它 broker 的信息。——建议至少提供两个 broker的信息,因为一旦其中一个宕机,生产者仍然能够连接到集群上。
props.put("bootstrap.servers", brokerList);
// 将 key 转换为字节数组的配置,必须设定为一个实现了org.apache.kafka.common.serialization.Serializer 接口的类,
// 生产者会用这个类把键对象序列化为字节数组。
// ——kafka 默认提供了 StringSerializer和 IntegerSerializer、ByteArraySerializer。当然也可以自定义序列化器。
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 和 key.serializer 一样,用于 value 的序列化
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 内容形式如:"producer-1"
props.put("client.id", "producer.client.id.demo");
return props;
}
public class KafkaProducerTest {
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.88.100:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for(int i = 0; i < 100; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("test", null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 5. 关闭生产者
producer.close();
}
}
3.1.5、序列化器
消息要到网络上进行传输,必须进行序列化,而序列化器的作用就是如此。
Kafka 提供了默认的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer),
还有整型(IntegerSerializer)和字节数组(BytesSerializer)序列化器,这些序列化器都实现了接口(org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
3.1.6、自定义序列化器
/**
* 自定义序列化器
*/
public class CompanySerializer implements Serializer<Company> {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, Company data) {
if (data == null) {
return null;
}
byte[] name, address;
try {
if (data.getName() != null) {
name = data.getName().getBytes("UTF-8");
} else {
name = new byte[0];
}
if (data.getAddress() != null) {
address = data.getAddress().getBytes("UTF-8");
} else {
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close() {
}
}
使用自定义的序列化器
public class ProducerDefineSerializer {
public static final String brokerList = "localhost:9092";
public static final String topic = "angyan";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, CompanySerializer.class.getName());
// properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,ProtostuffSerializer.class.getName());
properties.put("bootstrap.servers", brokerList);
KafkaProducer<String, Company> producer =new KafkaProducer<>(properties);
Company company = Company.builder().name("kafka").address("北京").build();
// Company company = Company.builder().name("hiddenkafka").address("China").telphone("13000000000").build();
ProducerRecord<String, Company> record =new ProducerRecord<>(topic, company);
producer.send(record).get();
}
}
3.1.7、分区器
本身kafka有自己的分区策略的,如果未指定,就会使用默认的分区策略:
Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions。如果Key相同的话,那么就会分配到统一分区。
实现自定义分区器需要通过配置参数ProducerConfig.PARTITIONER_CLASS_CONFIG来实现
// 自定义分区器的使用
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,DefinePartitioner.class.getName());
3.1.8、拦截器
Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
生产者拦截器可以用在消息发送前做一些准备工作。
使用场景
1、按照某个规则过滤掉不符合要求的消息
2、修改消息的内容
3、统计类需求
实现自定义拦截器之后需要在配置参数中指定这个拦截器,此参数的默认值为空,如下:
// 自定义拦截器使用
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,ProducerDefineSerializer.class.getName());
3.1.9、retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况下,如果达到了 retires 设置的次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms,可以通过 retry.backoff.ms 参数来修改这个时间间隔。
3.1.10、batch.size
当有多个消息要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算,而不是消息个数。当批次被填满,批次里的所有消息会被发送出去。不过生产者并不一定都会等到批次被填满才发送,半满的批次,甚至只包含一个消息的批次也可能被发送。所以就算把 batch.size 设置的很大,也不会造成延迟,只会占用更多的内存而已,如果设置的太小,生产者会因为频繁发送消息而增加一些额外的开销。
3.1.11、max.request.size
该参数用于控制生产者发送的请求大小,它可以指定能发送的单个消息的最大值,也可以指单个请求里所有消息的总大小。 broker 对可接收的消息最大值也有自己的限制( message.max.size ),所以两边的配置最好匹配,避免生产者发送的消息被 broker 拒绝。
3.2、从Kafka的topic中消费消息
3.2.1、需求
从 test topic中,将消息都消费,并将记录的offset、key、value打印出来
3.2.2、准备工作
在cn.test.kafka包下创建KafkaConsumerTest类
3.2.3、开发步骤
- 创建Kafka消费者配置
- 创建Kafka消费者
- 订阅要消费的主题
- 使用一个while循环,不断从Kafka的topic中拉取消息
- 将将记录(record)的offset、key、value都打印出来
3.2.4、参考代码
必要参数设置
public static final String brokerList = "localhost:9092";
public static final String groupId = "group.angyan";
public static Properties initConfig() {
Properties props = new Properties();
// 与KafkaProducer中设置保持一致
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 必填参数,该参数和KafkaProducer中的相同,制定连接Kafka集群所需的broker地址清单,可以设置一个或者多个
props.put("bootstrap.servers", brokerList);
// 消费者隶属于的消费组,默认为空,如果设置为空,则会抛出异常,这个参数要设置成具有一定业务含义的名称
props.put("group.id", groupId);
// 指定KafkaConsumer对应的客户端ID,默认为空,如果不设置KafkaConsumer会自动生成一个非空字符串
props.put("client.id", "consumer.client.id.demo");
// 指定消费者拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,ConsumerInterceptorTTL.class.getName());
return props;
}
public class KafkaProducerTest {
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.angyan.cn:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for(int i = 0; i < 100; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("test", null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 5. 关闭生产者
producer.close();
}
}
3.3、异步使用带有回调函数方法生产消息
如果我们想获取生产者消息是否成功,或者成功生产消息到Kafka中后,执行一些其他动作。此时,可以很方便地使用带有回调函数来发送消息。
需求:
- 在发送消息出现异常时,能够及时打印出异常信息
- 在发送消息成功时,打印Kafka的topic名字、分区id、offset
public class KafkaProducerTest {
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.angyan.cn:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for(int i = 0; i < 100; ++i) {
// 一、同步方式
// 获取返回值Future,该对象封装了返回值
// Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("test", null, i + ""));
// 调用一个Future.get()方法等待响应
// future.get();
// 二、带回调函数异步方式
producer.send(new ProducerRecord<String, String>("test", null, i + ""), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null) {
System.out.println("发送消息出现异常");
}
else {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
System.out.println("发送消息到Kafka中的名字为" + topic + "的主题,第" + partition + "分区,第" + offset + "条数据成功!");
}
}
});
}
// 5. 关闭生产者
producer.close();
}
}
3.4、服务端常用参数配置
参数配置:config/server.properties
broker.id=0
listeners=PLAINTEXT://:9092
# it uses the value for "listeners" if configured. Otherwise, it will use the value
#advertised.listeners=PLAINTEXT://your.host.name:9092
#log.dirs=/tmp/kafka-logs
log.dirs=/tmp/kafka/log
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
-
zookeeper.connect
- 指明Zookeeper主机地址,如果zookeeper是集群则以逗号隔开,如172.6.14.61:2181,172.6.14.62:2181,172.6.14.63:2181
-
listeners
- 监听列表,broker对外提供服务时绑定的IP和端口。多个以逗号隔开,如果监听器名称不是一个安全的协议, listener.security.protocol.map也必须设置。主机名称设置0.0.0.0绑定所有的接口,主机名称为空则绑定默认的接口。如:PLAINTEXT://myhost:9092,SSL://:9091,CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093
-
broker.id
- broker的唯一标识符,如果不配置则自动生成,建议配置且一定要保证集群中必须唯一,默认-1
-
log.dirs
- 日志数据存放的目录,如果没有配置则使用log.dir,建议此项配置。
-
message.max.bytes
- 服务器接受单个消息的最大大小,默认1000012 约等于976.6KB。
















 1296
1296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











