







目录
高并发场景分析
一般来说, 如果 10Wqps,或者20Wqps ,可使用分布式缓存来抗。
比如redis集群,6主6从:主 提供读写,从 作为备,从 不提供读写服务。
6主6从架构下,1台平均抗3w-4W并发,还可以抗住 18Wqps -24Wqps。
并且,如果QPS达到100w,通过增加redis集群中的机器数量,可以扩展缓存的容量和并发读写能力。6主6从的架构,可以扩容到 30主30从
同时,缓存数据对于应用来讲都是共享的,主从架构,实现高可用。
问题:如何解决缓存热点(热key)问题?
一旦出现缓存热点现象,例如有 10 w流量访问同一 Key,并集中于某一个 Redis 实例,可能会导致该实例的 CPU 负载过高。
这种情况下,即便增加 Redis 集群数量,也无法根本解决问题。那么解决热 key 问题的有效手段,到底是什么呢?非常有效的手段之一,本地缓存。其主要原因是:本地缓存避免了 Redis 单个缓存服务器的高负载。同时,本地内存缓存拥有更快的访问速度,因为数据直接存储在应用程序的内存中,无需通过网络传输数据。
本地缓存的实质:是多副本, 空间换时间。通过复制多份缓存副本,将请求分散,可以缓解由缓存热点引发的单个缓存服务器压力。
凡事,有利必有弊。
那么,引入本地缓存又会带来哪些问题呢?主要问题有:
-
数据一致性问题
-
本地缓存数据污染问题
咱们作为未来超级架构师,需要采蜜百家之长, 极度开阔自己的技术视野。
所以,这里基于《京东服务端应用多级缓存架构方案》,給大家再梳理一篇。原文的京东服务端应用多级缓存架构方案|京东云技术团队。
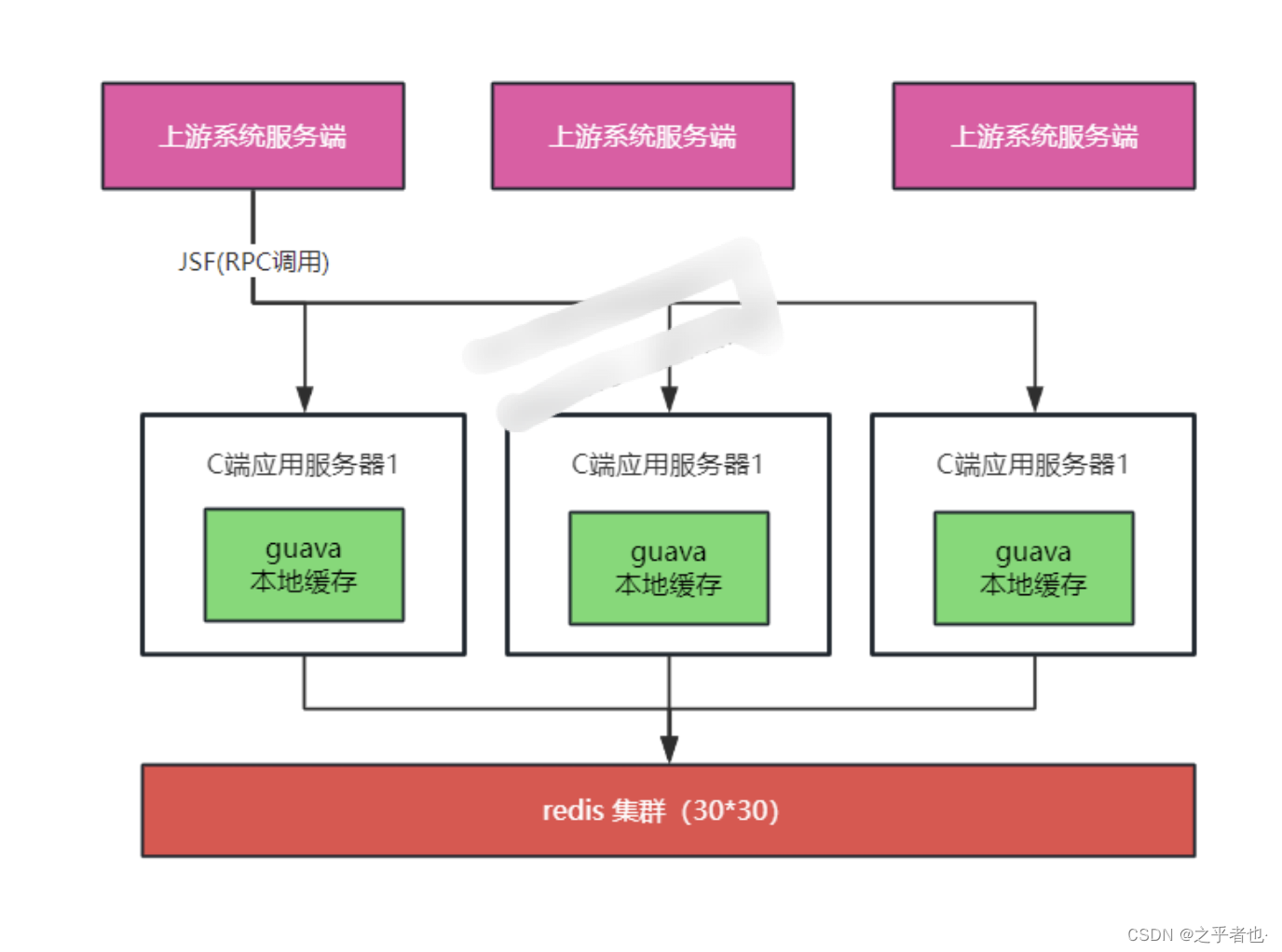
通用多级缓存方案
京东服务端应用多级缓存架构方案, 其实是一种常用的2级缓存的架构方案:
(1)L1一级缓存:本地缓存guava
(2)L2二级缓存:分布式缓存redis
2级缓存的架构方案的缓存访问流程:
-
请求优先打到应用本地缓存
-
本地缓存不存在,再去redis 集群拉取,同时缓存到本地
以上流程,类似于cache aside 旁路缓存模式。具体的缓存访问流程,大致如下:
多级缓存数据一致性问题
如何解决多级缓存数据一致性问题呢?主要是 多级缓存同。主要使用发布订阅模式、或者底层组件RPC通讯机制,完成本地cache与Redis缓存的数据同步。
-
京东采用的是 发布订阅模式
-
有赞采用的 底层组件RPC通讯机制
-
J2cache采用的是 发布订阅模式
首先看看 发布订阅, 深入下去,也有两种模式:
-
推送模式:每个频道都维护着一个客户端列表,当发送消息时,会遍历该列表并将消息推送给所有订阅者。
-
拉取模式:发送者将消息放入一个邮箱中,所有订阅该邮箱的客户端可以随时去收取。在确保所有客户端都成功收取完整邮件后,才会删除该邮件。
首先,来看看 京东的数据一致性问题:多级缓存同步方案
-
运营后台保存数据,写入Redis缓存,同时利用 Redis 的发布订阅功能发布信息。
-
业务应用集群作为消息订阅者,接受到运营数据消息后,删除本地缓存。
-
当 C 端流量请求到达时,若本地缓存不存在,则从 Redis 中加载缓存至本地缓存。
-
防止极端情况下,Redis缓存失效,通过定时任务,将数据重新加载到Redis缓存。
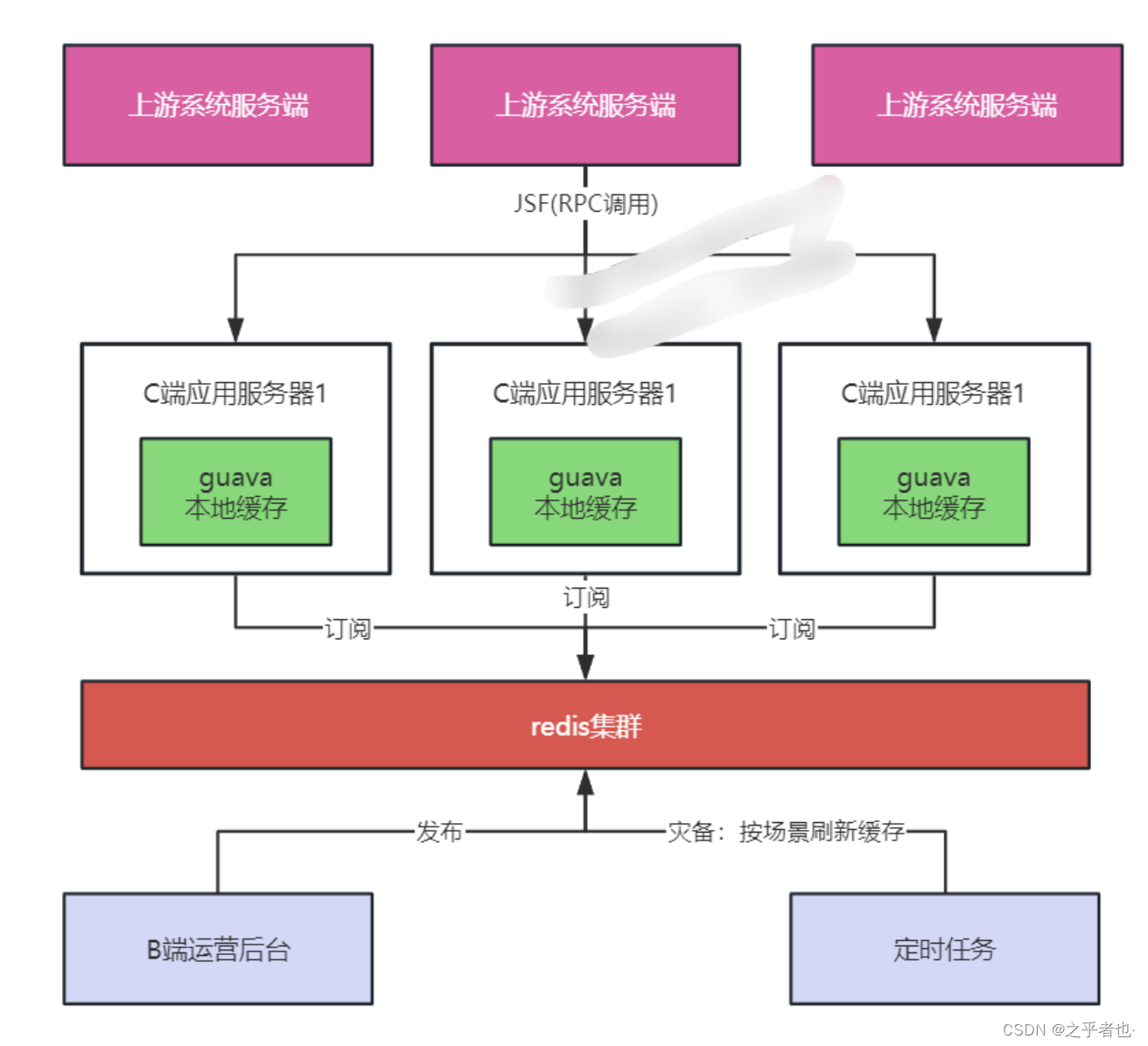
京东发布订阅缓存同步组件选型
京东使用redis的 channel(频道)机制,完成本地cache与Redis缓存的数据同步。在 Redis 的channel(频道)机制,发布订阅模式是一种推送模式。
-
通过使用 SUBSCRIBE 命令,可以订阅一个或多个频道,以便在相关频道发布消息时接收到通知。
-
PUBLISH 命令则用于向一个或多个频道发送消息。当某个频道有消息发布时,所有订阅该频道的客户端都会收到相应的通知。
另外,Redis 的发布订阅模式是异步的。当有消息发布到某个频道时,Redis 会异步地将消息推送给所有订阅该频道的客户端。这就意味着,客户端不会因为等待消息而阻塞,而是继续执行其他任务,仅在需要接收消息时才去获取。这种异步方式有助于提高系统的并发性和效率。
什么是缓存污染问题?
引入本地缓存又会带来哪些问题呢?主要问题有:
-
数据一致性问题
-
本地缓存数据污染问题
前面咱们看了 数据一致性问题。再来看看,缓存污染问题。
缓存污染问题指的是留存在缓存中的数据,实际不会再被访问了,但是又占据了缓存空间。
如果这样的数据体量很大,甚至占满了缓存,每次有新数据写入缓存时,还需要把这些数据逐步淘汰出缓存,就会增加缓存操作的时间开销。
因此,要解决缓存污染问题,最关键的技术就是能识别出这些只访问一次或是访问次数很少的数据,在淘汰数据时,优先把他们筛选出来淘汰掉。所以,解决缓存污染的核心策略,叫做
缓存中主要常用的缓存淘汰策略:
-
random 随机
-
lru
-
lfu
(1)random 随机:是随机选择数据进行淘汰 主要包括volatile-random和allkeys-random。随机淘汰,比如volatile-random和allkeys-random ,无法把不再访问的数据筛选出来,可能会造成缓存污染。
(2)LRU:LRU算法的基本思想是,当缓存空间不足时,要淘汰最近最少使用的缓存项,即淘汰访问时间最长的数据项。这样可以保证最常用的数据项始终保留在缓存中,从而提高系统的响应速度和吞吐量。由于LRU策略只考虑数据的访问时效,对于只访问一次的数据来说,LRU策略无法很快将其筛选出来。
(3)LFU策略再LRU策略基础上进行了优化,在筛选数据时,首先会筛选并淘汰访问次数少的数据,然后针对访问次数相同的数据,再筛选并淘汰访问时间最久的数据。
在实际业务应用中,LRU和LFU两个策略都有应用。
LRU和LFU两种策略关注的数据访问特征各有侧重,LRU策略更加关注数据的时效性,而LFU策略更加关注数据的访问频次。
通常情况下,实际应用的负载具有较好的时间局部性,所以LRU策略的应用会更加广泛。
但是,在扫描式查询的应用场景中,LFU策略就可以很好地应对缓存污染问题了,建议你优先使用。
京东本地缓存用的是guava,那么策略是LRU,LRU策略更加关注数据的时效性, 具有较好的时间局部性,使用于大部分数据场景。
大部分本地缓存用的建议使用caffeine,那么策略是LRU+LFU,既 具有较好的时间局部性,使用于大部分数据场景。也具有关注数据的访问频次, 避免扫描式查询的应用场景中数据污染问题。
多级缓存架构的注意事项
-
由于本地缓存会占用 Java 进程的 JVM 内存空间,因此不适合存储大量数据,需要对缓存大小进行评估。
-
如果业务能够接受短时间内的数据不一致,那么本地缓存更适用于读取场景。
-
在缓存更新策略中,无论是主动更新还是被动更新,本地缓存都应设置有效期。
-
考虑设置定时任务来同步缓存,以防止极端情况下数据丢失。
-
在 RPC 调用中,需要避免本地缓存被污染,可以通过合理的缓存淘汰策略,来解决这个问题。
-
当应用重启时,本地缓存会失效,因此需要注意加载分布式缓存的时机。
-
通过发布/订阅解决数据一致性问题时,如果发布/订阅模式不持久化消息数据,如果消息丢失,本地缓存就会删除失败。所以,要解决发布订阅消息的高可用问题。
-
当本地缓存失效时,需要使用 synchronized 进行加锁,确保由一个线程加载 Redis 缓存,避免并发更新。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











