







 本文介绍了Spark3.4的更新亮点,包括SQL功能增强、PySpark和Streaming的新特性,以及Databricks的社区活跃度和AI生态系统的发展。重点讲解了SQL的默认值设置、多种文件格式支持、内存优化和Python工具的改进等。
本文介绍了Spark3.4的更新亮点,包括SQL功能增强、PySpark和Streaming的新特性,以及Databricks的社区活跃度和AI生态系统的发展。重点讲解了SQL的默认值设置、多种文件格式支持、内存优化和Python工具的改进等。
目录
前言
首先介绍一下 Spark 的创始团队开创的公司 Databricks。

Databricks 是湖仓一体概念的提出者和先驱者。目前除了 Spark,开源的热门项目还有 Delta Lake 和 Mlflow,服务客户超过一万,在全球有非常高的投资和年收入。
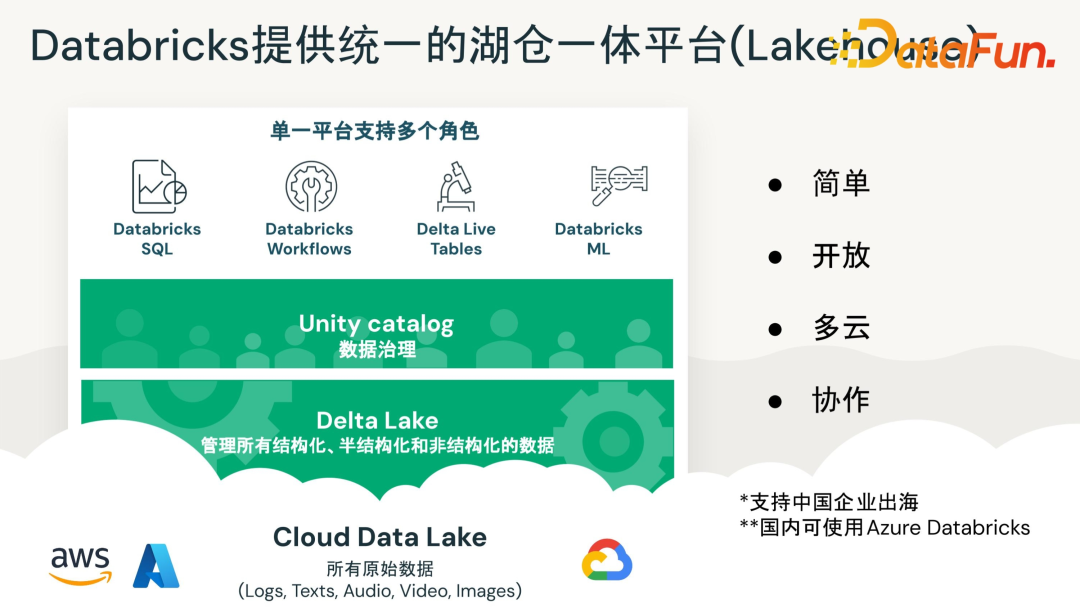
公司在大中华区开始开展业务。国内可通过 Azure Databricks 来使用公司的产品。Databricks 提供统一的湖仓一体平台(Lakehouse),可以支撑整个企业数据平台的使用,和一些AI相关的开发工作。

平台是非常通用的,可以涉及各行各业,目前已经服务的客户有医疗行业、制造业、娱乐业、金融行业等等。
接下来我们一起来看看 Spark 3.4 都有哪些有趣的新特性吧。
Community Updates
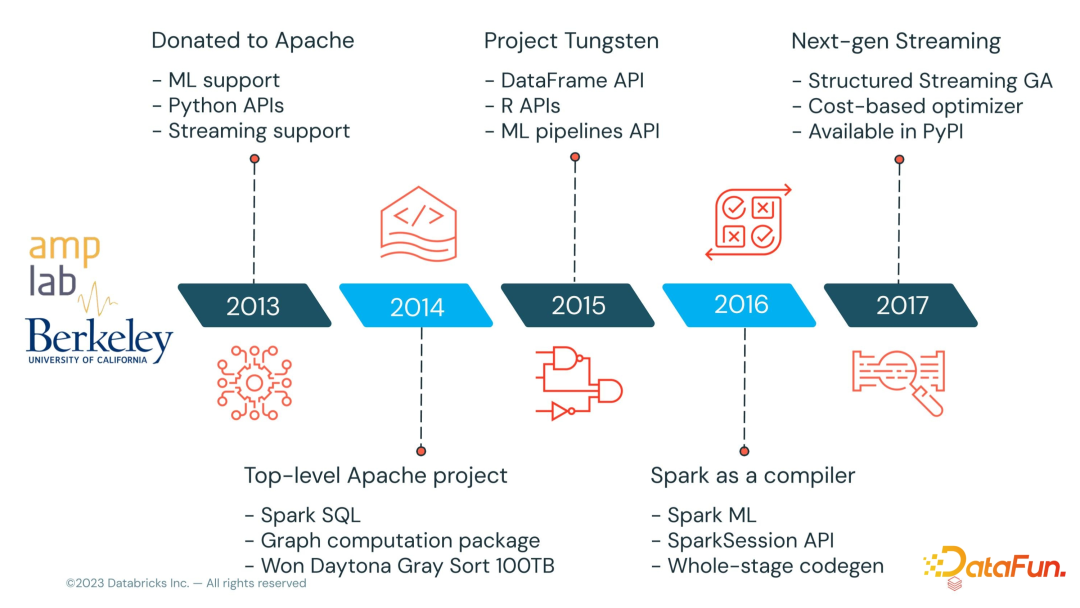
Spark 诞生于伯克利大学 AMPLab,属于伯克利大学的研究性项目,2013 年 Spark正式成为 Aparch 基金项目,到目前已经有十年时间。

这10年中 Spark 社区非常活跃,我们来看下当前Spark 社区的情况。
-
Maven各个渠道的下载量超过了 10 亿
-
Stack Overflow 上超过 10 万个问题
-
GitHub上贡献作者超过 3600 个
-
整个Spark 生态超过 100 个 Data Source
-
超过44 万个 commits
-
下载和使用覆盖全球200 多个国家
可以看到 Spark 整个社区还是非常活跃的,在整个开源大数据项目里面,Spark 的开发活跃度一直遥遥领先。
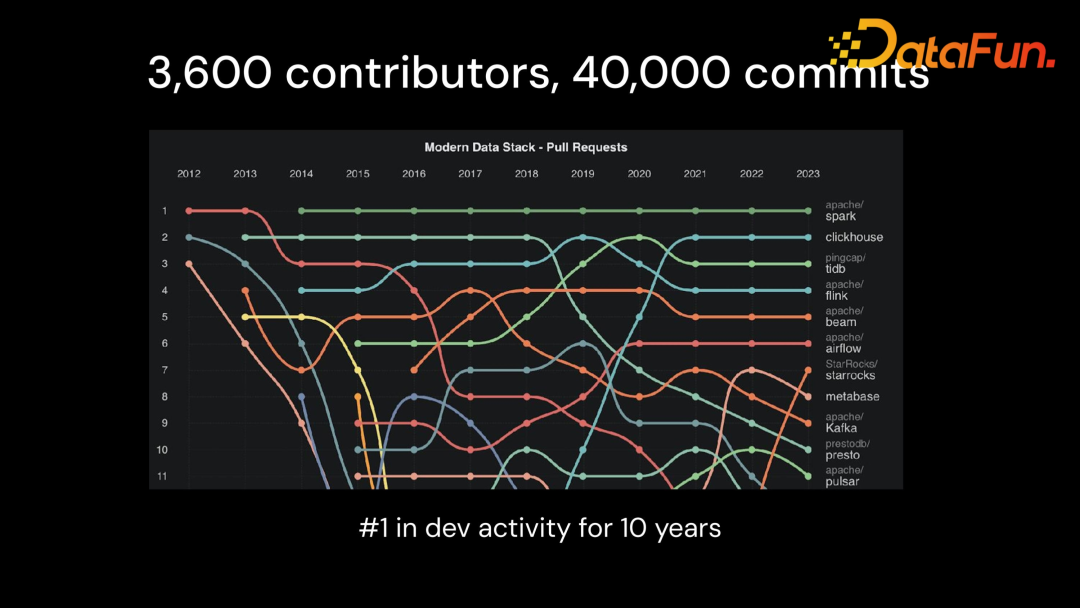
Spark 从创建后发展迅速,通过下图可以看到这10 年中,Spark 一直在创新的路上。比如 ML 支持,多语言丰富的 API,丰富的 data source 支持,较好的内存优化机制,且可使用 Spark SQL 进行流数据处理、离线数据处理,增加了ANSI SQL 使 Spark SQL 更加标准,方便大家从其他数据库的 SQL 脚本迁移到 Spark 上来。
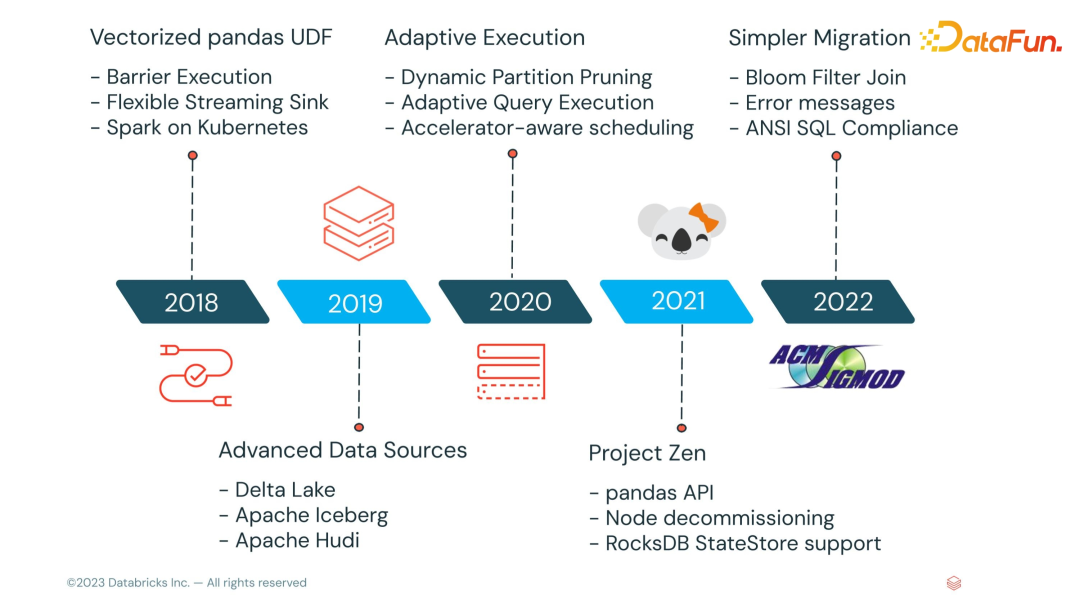
下面是 Spark 3.4 发布的一些新特性,接下来将挑选其中一些有意思的特性来分享。

SQL Features
Spark3.4 博采众长,参考了很多其他数据库里常见的函数,把它们内置到 Spark 里方便大家使用。

-
Set DEFAULT Values for Columns in Tables
我们在使用数据库的时候,可以在一个 value 上设置一个默认值,这样在插入数据时不需要每次指定一个值,而是让它提供一个默认值,如将一个ID、日期设置成默认填充。

-
Supported table formats include CSV, JSON, Orc, and Parquet.
支持多种文件格式

-
This works either at initial table creation table time, or afterwards.
针对表已存在,可以通过 alter table 去修改列默认值属性

下面来看看如何使用。
-
INSERT commands may then refer to any column’s default value using the DEFAULT keyword.
-
数据插入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











