









目录
Type Conversion Functions 类型转换函数
函数概述
如同RDBMS中标准SQL语法一样,Hive SQL也内建了不少函数,满足于用户在不同场合下的数据分析需求,提高开发SQL数据分析的效率。
可以使用show functions查看当下版本支持的函数,并且可以通过describe function extended funcname来查看函数的使用方式和方法。
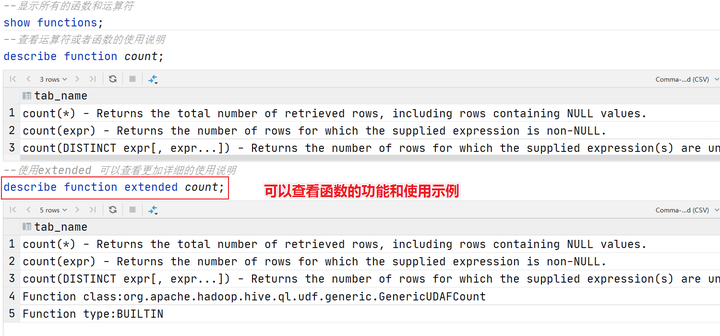
函数分类概述
Hive的函数很多,除了自己内置所支持的函数之外,还支持用户自己定义开发函数。
针对内置的函数,可以根据函数的应用类型进行归纳分类,比如:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
针对用户自定义函数,可以根据函数的输入输出行数进行分类,比如:UDF、UDAF、UDTF。
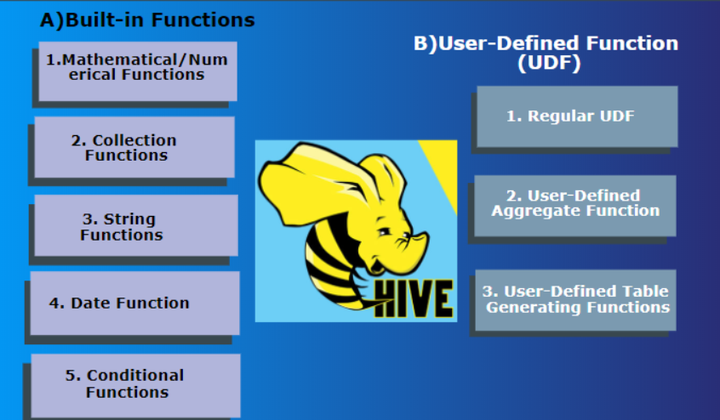
内置函数分类
所谓的内置函数(buildin)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
内置函数根据应用归类整体可以分为以下8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细讲解。
String Functions 字符串函数
主要针对字符串数据类型进行操作,比如下面这些:
•字符串长度函数:length
•字符串反转函数:reverse
•字符串连接函数:concat
•带分隔符字符串连接函数:concat_ws
•字符串截取函数:substr,substring
•字符串转大写函数:upper,ucase
•字符串转小写函数:lower,lcase
•去空格函数:trim
•左边去空格函数:ltrim
•右边去空格函数:rtrim
•正则表达式替换函数:regexp_replace
•正则表达式解析函数:regexp_extract
•URL解析函数:parse_url
•json解析函数:get_json_object
•空格字符串函数:space
•重复字符串函数:repeat
•首字符ascii函数:ascii
•左补足函数:lpad
•右补足函数:rpad
•分割字符串函数: split
•集合查找函数: find_in_set
------------String Functions 字符串函数------------
describe function extended find_in_set;
--字符串长度函数:length(str | binary)
select length("angelababy");
--字符串反转函数:reverse
select reverse("angelababy");
--字符串连接函数:concat(str1, str2, ... strN)
select concat("angela","baby");
--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));
--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy",2,2);
--字符串转大写函数:upper,ucase
select upper("angelababy");
select ucase("angelababy");
--字符串转小写函数:lower,lcase
select lower("ANGELABABY");
select lcase("ANGELABABY");
--去空格函数:trim 去除左右两边的空格
select trim(" angelababy ");
--左边去空格函数:ltrim
select ltrim(" angelababy ");
--右边去空格函数:rtrim
select rtrim(" angelababy ");
--正则表达式替换函数:regexp_replace(str, regexp, rep)
select regexp_replace('100-200', '(\\d+)', 'num');
--正则表达式解析函数:regexp_extract(str, regexp[, idx]) 提取正则匹配到的指定组内容
select regexp_extract('100-200', '(\\d+)-(\\d+)', 2);
--URL解析函数:parse_url 注意要想一次解析出多个 可以使用parse_url_tuple这个UDTF函数
select parse_url('http://www.itcast.cn/path/p1.php?query=1', 'HOST');
--json解析函数:get_json_object
--空格字符串函数:space(n) 返回指定个数空格
select space(4);
--重复字符串函数:repeat(str, n) 重复str字符串n次
select repeat("angela",2);
--首字符ascii函数:ascii
select ascii("angela"); --a对应ASCII 97
--左补足函数:lpad
select lpad('hi', 5, '??'); --???hi
select lpad('hi', 1, '??'); --h
--右补足函数:rpad
select rpad('hi', 5, '??');
--分割字符串函数: split(str, regex)
select split('apache hive', '\\s+');
--集合查找函数: find_in_set(str,str_array)
select find_in_set('a','abc,b,ab,c,def');
Date Functions 日期函数
主要针对时间、日期数据类型进行操作,比如下面这些:
•获取当前日期: current_date
•获取当前时间戳: current_timestamp
•UNIX时间戳转日期函数: from_unixtime
•获取当前UNIX时间戳函数: unix_timestamp
•日期转UNIX时间戳函数: unix_timestamp
•指定格式日期转UNIX时间戳函数: unix_timestamp
•抽取日期函数: to_date
•日期转年函数: year
•日期转月函数: month
•日期转天函数: day
•日期转小时函数: hour
•日期转分钟函数: minute
•日期转秒函数: second
•日期转周函数: weekofyear
•日期比较函数: datediff
•日期增加函数: date_add
•日期减少函数: date_sub
--获取当前日期: current_date
select current_date();
--获取当前时间戳: current_timestamp
--同一查询中对current_timestamp的所有调用均返回相同的值。
select current_timestamp();
--获取当前UNIX时间戳函数: unix_timestamp
select unix_timestamp();
--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
--抽取日期函数: to_date
select to_date('2009-07-30 04:17:52');
--日期转年函数: year
select year('2009-07-30 04:17:52');
--日期转月函数: month
select month('2009-07-30 04:17:52');
--日期转天函数: day
select day('2009-07-30 04:17:52');
--日期转小时函数: hour
select hour('2009-07-30 04:17:52');
--日期转分钟函数: minute
select minute('2009-07-30 04:17:52');
--日期转秒函数: second
select second('2009-07-30 04:17:52');
--日期转周函数: weekofyear 返回指定日期所示年份第几周
select weekofyear('2009-07-30 04:17:52');
--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09');
--日期增加函数: date_add
select date_add('2012-02-28',10);
--日期减少函数: date_sub
select date_sub('2012-01-1',10);
Mathematical Functions 数学函数
主要针对数值类型的数据进行数学计算,比如下面这些:
•取整函数: round
•指定精度取整函数: round
•向下取整函数: floor
•向上取整函数: ceil
•取随机数函数: rand
•二进制函数: bin
•进制转换函数: conv
•绝对值函数: abs
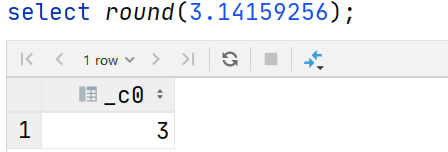
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
--向下取整函数: floor
select floor(3.1415926);
select floor(-3.1415926);
--向上取整函数: ceil
select ceil(3.1415926);
select ceil(-3.1415926);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(2);
--二进制函数: bin(BIGINT a)
select bin(18);
--进制转换函数: conv(BIGINT num, int from_base, int to_base)
select conv(17,10,16);
--绝对值函数: abs
select abs(-3.9);
Collection Functions 集合函数
主要针对集合这样的复杂数据类型进行操作,比如下面这些:
•集合元素size函数: size(Map<K.V>) size(Array<T>)
•取map集合keys函数: map_keys(Map<K.V>)
•取map集合values函数: map_values(Map<K.V>)
•判断数组是否包含指定元素: array_contains(Array<T>, value)
•数组排序函数:sort_array(Array<T>)
--集合元素size函数: size(Map<K.V>) size(Array<T>)
select size(`array`(11,22,33));
select size(`map`("id",10086,"name","zhangsan","age",18));
--取map集合keys函数: map_keys(Map<K.V>)
select map_keys(`map`("id",10086,"name","zhangsan","age",18));
--取map集合values函数: map_values(Map<K.V>)
select map_values(`map`("id",10086,"name","zhangsan","age",18));
--判断数组是否包含指定元素: array_contains(Array<T>, value)
select array_contains(`array`(11,22,33),11);
select array_contains(`array`(11,22,33),66);
--数组排序函数:sort_array(Array<T>)
select sort_array(`array`(12,2,32));
Conditional Functions 条件函数
主要用于条件判断、逻辑判断转换这样的场合,比如:
•if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
•空判断函数: isnull( a )
•非空判断函数: isnotnull ( a )
•空值转换函数: nvl(T value, T default_value)
•非空查找函数: COALESCE(T v1, T v2, ...)
•条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
•nullif( a, b ): 如果a = b,则返回NULL;否则返回NULL。否则返回一个
•assert_true: 如果'condition'不为真,则引发异常,否则返回null
--使用之前课程创建好的student表数据
select * from student limit 3;
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex ='男','M','W') from student limit 3;
--空判断函数: isnull( a )
select isnull("allen");
select isnull(null);
--非空判断函数: isnotnull ( a )
select isnotnull("allen");
select isnotnull(null);
--空值转换函数: nvl(T value, T default_value)
select nvl("allen","itcast");
select nvl(null,"itcast");
--非空查找函数: COALESCE(T v1, T v2, ...)
--返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
select COALESCE(null,11,22,33);
select COALESCE(null,null,null,33);
select COALESCE(null,null,null);
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'man' else 'women' end from student limit 3;
--nullif( a, b ):
-- 果a = b,则返回NULL;否则返回NULL。否则返回一个
select nullif(11,11);
select nullif(11,12);
--assert_true(condition)
--如果'condition'不为真,则引发异常,否则返回null
SELECT assert_true(11 >= 0);
SELECT assert_true(-1 >= 0);
Type Conversion Functions 类型转换函数
主要用于显式的数据类型转换,有下面两种函数:
•任意数据类型之间转换:cast
--任意数据类型之间转换:cast
select cast(12.14 as bigint);
select cast(12.14 as string);
Data Masking Functions 数据脱敏函数
主要完成对数据脱敏转换功能,屏蔽原始数据,主要如下:
•mask
•mask_first_n(string str[, int n]
•mask_last_n(string str[, int n])
•mask_show_first_n(string str[, int n])
•mask_show_last_n(string str[, int n])
•mask_hash(string|char|varchar str)
--mask
--将查询回的数据,大写字母转换为X,小写字母转换为x,数字转换为n。
select mask("abc123DEF");
select mask("abc123DEF",'-','.','^'); --自定义替换的字母
--mask_first_n(string str[, int n]
--对前n个进行脱敏替换
select mask_first_n("abc123DEF",4);
--mask_last_n(string str[, int n])
select mask_last_n("abc123DEF",4);
--mask_show_first_n(string str[, int n])
--除了前n个字符,其余进行掩码处理
select mask_show_first_n("abc123DEF",4);
--mask_show_last_n(string str[, int n])
select mask_show_last_n("abc123DEF",4);
--mask_hash(string|char|varchar str)
--返回字符串的hash编码。
select mask_hash("abc123DEF");
Misc. Functions 其他杂项函数
•hive调用java方法: java_method(class, method[, arg1[, arg2..]])
•反射函数: reflect(class, method[, arg1[, arg2..]])
•取哈希值函数:hash
•current_user()、logged_in_user()、current_database()、version()
•SHA-1加密: sha1(string/binary)
•SHA-2家族算法加密:sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)
•crc32加密:
•MD5加密: md5(string/binary)
--hive调用java方法: java_method(class, method[, arg1[, arg2..]])
select java_method("java.lang.Math","max",11,22);
--反射函数: reflect(class, method[, arg1[, arg2..]])
select reflect("java.lang.Math","max",11,22);
--取哈希值函数:hash
select hash("allen");
--current_user()、logged_in_user()、current_database()、version()
--SHA-1加密: sha1(string/binary)
select sha1("allen");
--SHA-2家族算法加密:sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)
select sha2("allen",224);
select sha2("allen",512);
--crc32加密:
select crc32("allen");
--MD5加密: md5(string/binary)
select md5("allen");
用户自定义函数分类
虽然说Hive内置了很多函数,但是不见得一定可以满足于用户各种各样的分析需求场景。为了解决这个问题,Hive推出来用户自定义函数功能,让用户实现自己希望实现的功能函数。
用户自定义函数简称UDF,源自于英文user-defined function。自定义函数总共有3类,是根据函数输入输出的行数来区分的,分别是:
UDF(User-Defined-Function)普通函数,一进一出
UDAF(User-Defined Aggregation Function)聚合函数,多进一出
UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
UDF分类标准扩大化
虽然说UDF叫做用户自定义函数,其分类标准主要针对的是用户编写开发的函数。
但是这套UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和自定义函数。因为不管是什么类型的行数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何毛病。千万不要被UD(User-Defined)这两个字母所迷惑,照成视野的狭隘。
比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型。

UDF 普通函数
UDF函数通常把它叫做普通函数,最大的特点是一进一出,也就是输入一行输出一行。比如round这样的取整函数,接收一行数据,输出的还是一行数据。
UDAF 聚合函数
UDAF函数通常把它叫做聚合函数,A所代表的单词就是Aggregation聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。比如count、sum这样的函数。
•count:统计检索到的总行数。
•sum:求和
•avg:求平均
•min:最小值
•max:最大值
•数据收集函数(去重): collect_set(col)
•数据收集函数(不去重): collect_list(col)
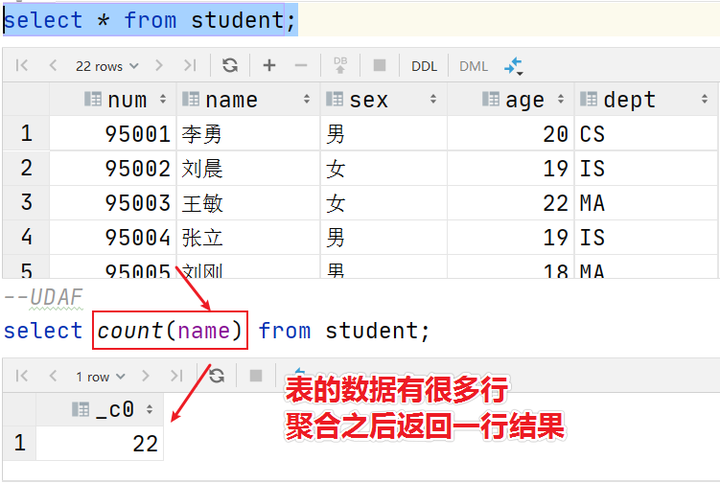
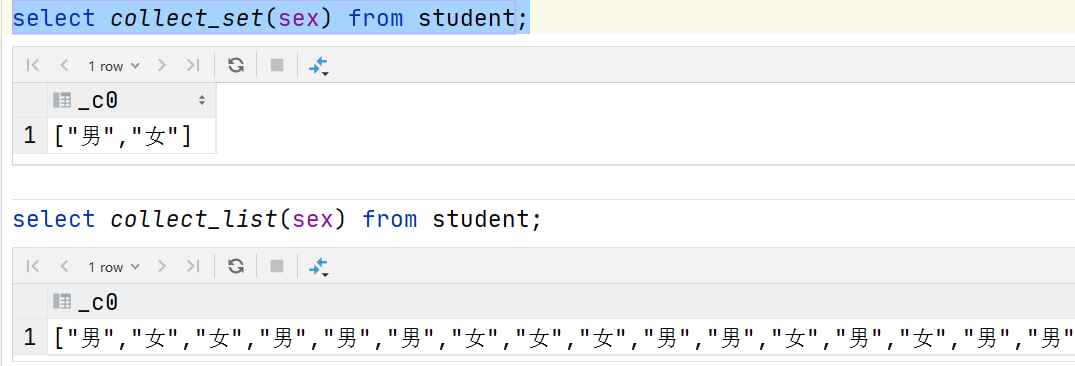
select sex from student;
select collect_set(sex) from student;
select collect_list(sex) from student;
UDTF 表生成函数
UDTF函数通常把它叫做表生成函数,T所代表的单词是Table-Generating表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。
之所以叫做表生成函数,原因在于这类型的函数作用返回的结果类似于表(多行数据嘛),同时,UDTF函数也是我们接触比较少的函数,陌生。比如explode函数。
















 4679
4679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











