







目录
快手SQL on Hadoop智能引擎架构
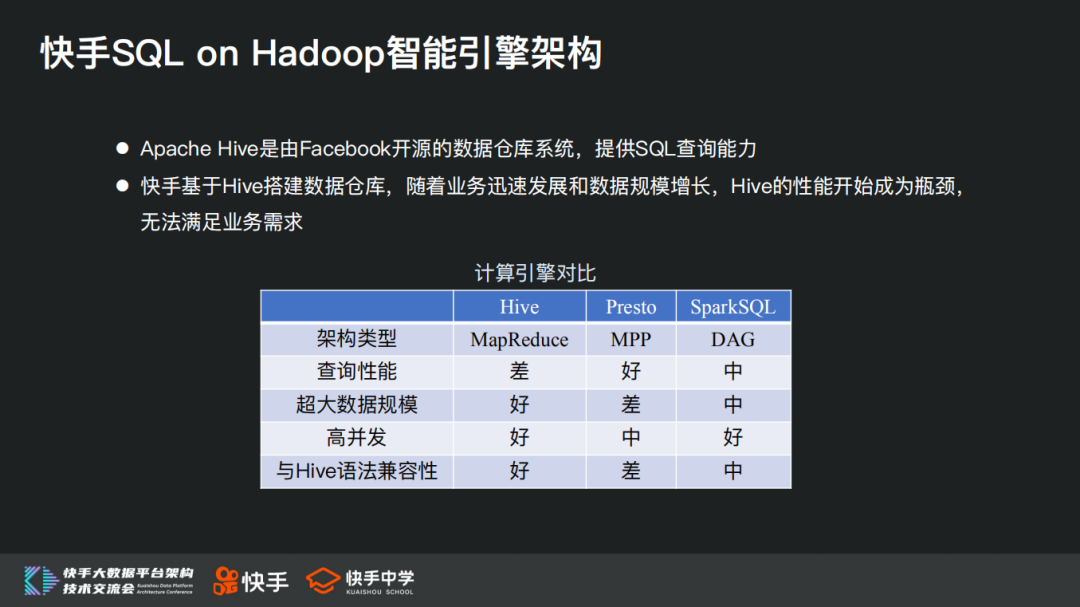
Apache Hive是由Facebook开源的数据仓库系统,提供SQL查询能力,快手基于Hive搭建数据仓库,随着业务迅速发展和数据规模增长,Hive的性能开始成为瓶颈,无法满足业务需求。
Hive把用户SQL通过解释器转换为一系列MR作业提交到hadoop环境中运行,MR存在作业启动、调度开销大、落盘多磁盘IO重的问题,这导致其性能注定无法太好,针对Hive查询速度慢的问题,业界先后推出了包括presto/impala/spark等查询引擎,在实现和适用场景上各有优缺点。
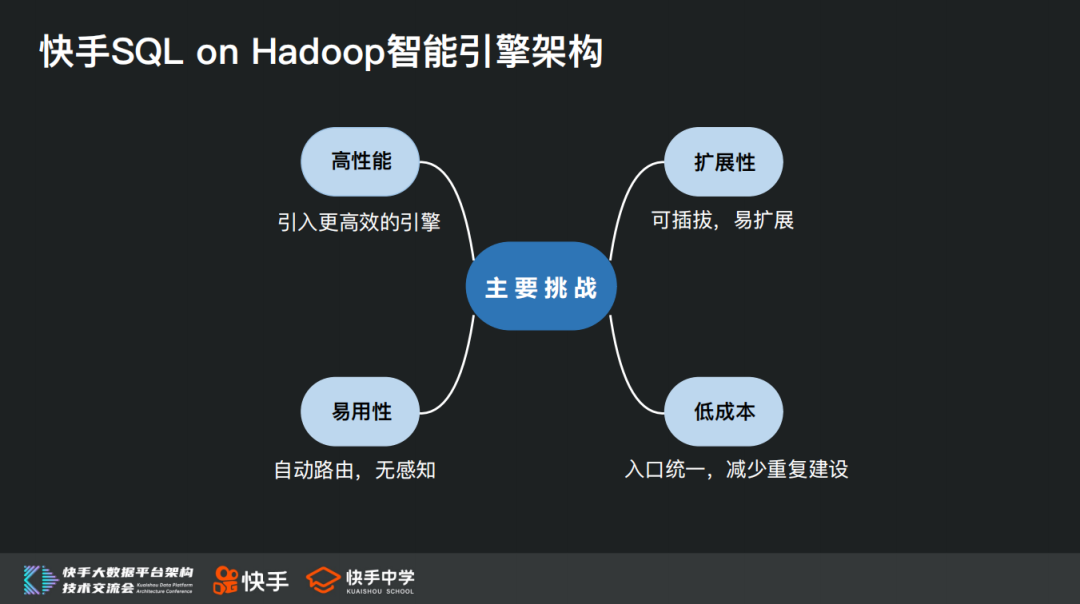
在计算引擎层面我们所面临的几个挑战是:
-
高性能:业务要求更高的查询性能,需要引入更高效的计算引擎
-
易用性:由于不同引擎在语法以及适用场景上各有优缺点,对于业务来说存在学习和使用门槛,需要通过技术手段来降低或者消除这种门槛
-
扩展性:技术是发展非常快的,未来随着技术发展可能还会有其他更高效的引擎不断出现,我们在架构设计上需要能够考虑到很好地扩展性支持这些新的计算引擎,需要做到计算引擎的可插拔、易扩展
-
低成本:围绕Hive我们构建了大量周边工具及服务,包括资源管理、血缘管理、权限控制等各个方面。如果每引入一个引擎都再各自开发一套周边工具及服务的建设会是一个非常昂贵的事,所以这一块需要做到低成本接入
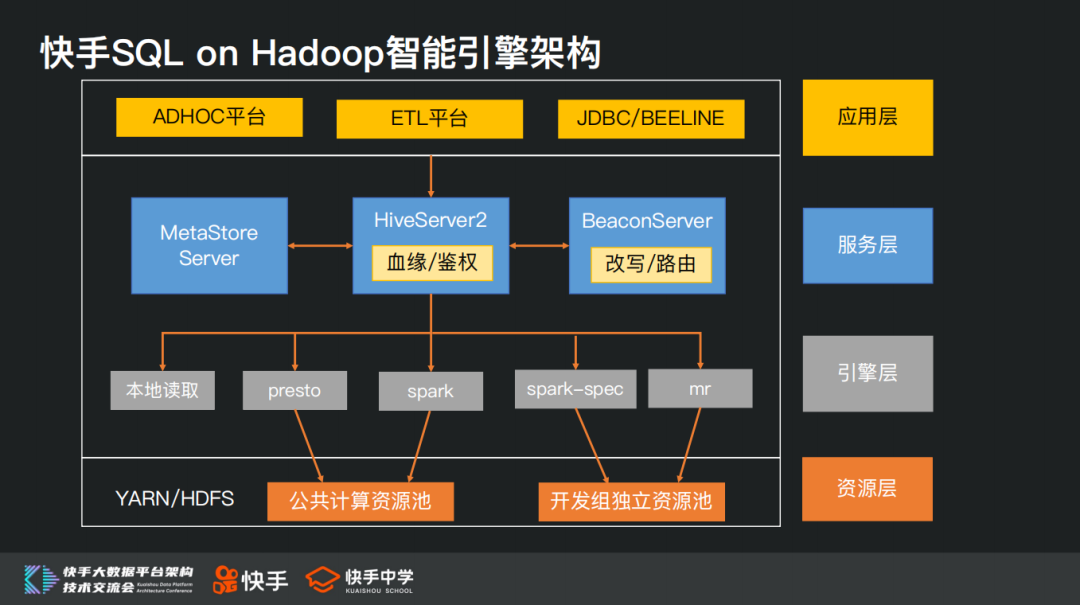
基于上述考虑,我们最终基于HiveServer本身的Hook架构,实现一个BeaconServer。所有的查询仍然以HiveServer作为统一入口,从而解决易用性和低成本的问题。
BeaconServer作为后端Hook Server服务,配合HS2中的Hook,在HS2 服务之外实现了所需的功能,包括根据一定规则路由SQL到适当的引擎,从而起到查询加速的效果。当前支持的模块包括路由、审计、SQL 重写、错误分析、优化建议等。
BeaconSer
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











