









目录
引言
Flink可以说是当下最流行的分布式流数据处理引擎。但我最近在尝试基于Flink实现数据的“微批处理”的过程中却屡屡碰壁,结果并不完美,但也对于Flink的keyBy,snapshot等机制有了更进一步的的体会,聊以记录下。
背景
需要优化的流处理作业(下称作业)中的消息处理需要满足以下几点:
-
至少一次(at least once)的处理语义;
-
按key保序;
-
秒级时延。
第一点基于Flink的checkpoint机制和kafka可设置消费offset的特性即可实现。而作业处理的消息可被看作<key, value>的二元组,(如下图所示)其中按key保序体现在两个环节:
-
在kafka的源topic中,相同key的消息是保存在同一个partition中;
-
在作业处理完相同key的消息发送到下游topic后,需要保持在源topic中的相对顺序。
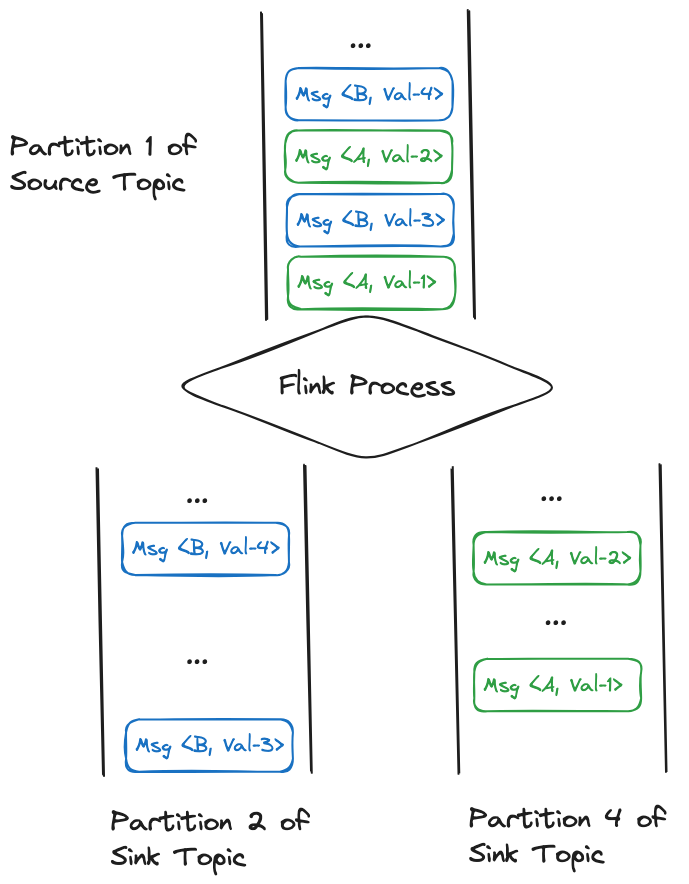
而想要把消息,比如以list的形式聚合在一起进行“微批”处理的原因是因为在与外部存储(如Hbase)的交互中,批量更新接口的执行效率通常都优于单条更新,进而能够提升作业的吞吐量。
显然,我们可以简单的基于keyBy + (time) window + aggregate的常规方式将一段时间内相同key的消息聚合到一起后,进行后续的处理同时也能保持它们的相对顺序。
但在第三点,即秒级时延的限制条件下,作业往往聚合不了多条消息,因为Flink的keyed state(可以暂时理解为是一个Map)是基于key来区分保存数据的,而短时间内相同key的消息大概率只有一条。
实现
方法一 Virtual Key
虽然keyBy后的每个subtask内,相同key的消息的聚合量少,但属于该subtask的整体消息量是很大的。因而一个直觉的想法是:如果保持消息被分配到的subtask相同,但是所有同属于该subtask的消息传递给Flink一个相同的virtual key,就能让分散的消息聚合起来了。
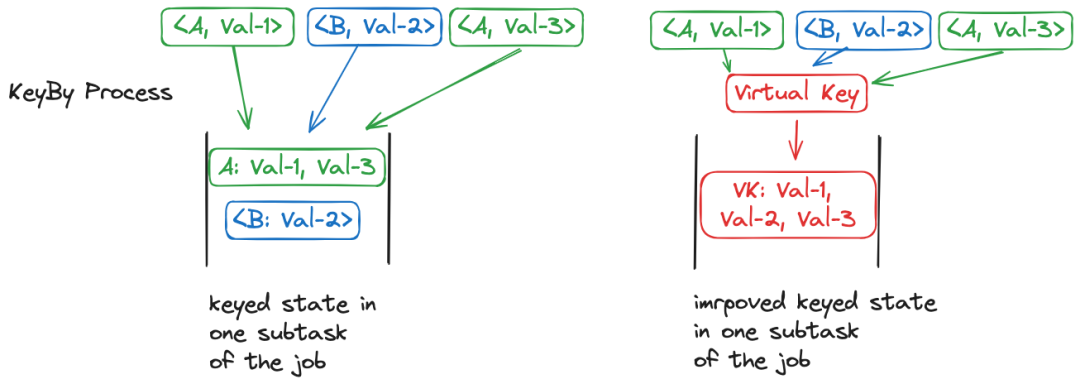
达成上图所示的效果需要做到两点:
-
对于每个subtask,事先计算出一个能够使得消息被分配到该subtask的virtual key;
-
对于每个消息,计算出(original) key对应的subtask,并将该subtask对应的virtual key作为KeySelector接口getKey方法的返回结果。
我们直接看最终的KeySelector代码实现:
/**
* 生成 virtualKey 的 KeySelector
*/
public static class VirtualKeySelector implements KeySelector<Object, Integer> {
/**
* 当前keyBy算子的并行度
*/
private final int operatorParallelism;
/**
* 数组下表为subtaskIndex,即virtualKeys[i]为第i个subtask的 virtualKey
*/
private final Integer[] virtualKeys;
public VirtualKeySelector(int localParallelism) {
this.operatorParallelism = localParallelism;
// 在构造函数中生成所有 subtask 对应的 virtualKey
virtualKeys = createVirtualKeys(localParallelism);
}
/**
* 事先计算出一个能够使得消息被分配到该 subtask 的 virtualKey
*
* @param parallelism 当前keyBy算子的并行度
* @return 需要进入第i个 subtask 所对应的 virtualKey
*/
private static Integer[] createVirtualKeys(int parallelism) {
// subtaskIndex --> 合法的 virtualKey 集合
HashMap<Integer, LinkedHashSet<Integer>> candidateVirtualKeySet = new HashMap<>();
// 直接用Flink API计算max parallelism
int maxParallelism = KeyGroupRangeAssignment.computeDefaultMaxParallelism(parallelism);
// 0 ~ maxRandomKey 是 virtualKey 取值的范围
// 从中一定能找到所有 subtask 对应的 virtualKey
int maxRandomKey = parallelism * 12;
for (int virtualKey = 0; virtualKey < maxRandomKey; virtualKey++) {
int subtaskIndex = KeyGroupRangeAssignment.assignKeyToParallelOperator(virtualKey, maxParallelism, parallelism);
LinkedHashSet<Integer> candidateKeys = candidateVirtualKeySet.computeIfAbsent(subtaskIndex, k -> new LinkedHashSet<>());
candidateKeys.add(virtualKey);
}
Integer[] localVirtualKeys = new Integer[parallelism];
for (int i = 0; i < parallelism; i++) {
LinkedHashSet<Integer> virtualKeySet = candidateVirtualKeySet.get(i);
if (virtualKeySet == null || virtualKeySet.isEmpty()) {
throw new IllegalArgumentException("create rebalanceKeys failed");
} else {
// 任意取一个满足的 virtualKey
localVirtualKeys[i] = virtualKeySet.stream().findFirst().get();
}
}
return localVirtualKeys;
}
/**
* 基于每个message的originalKey
* 返回对应的virtualKey
*/
@Override
public Integer getKey(Object message) {
// 自行基于murmurHash确定每个message所属的subtask
int selfComputedSubtaskIndex = Math.abs(MathUtils.murmurHash(message.getKey().hashCode())) % operatorParallelism;
return virtualKeys[selfComputedSubtaskIndex];
}
}其中createVirtualKeys方法是照抄网上的,因此为什么在0~maxRandomKey的范围内一定能找到parallelism个subtask对应的virtualKey我到现在也没搞懂(囧)。而第35行则是Flink框架内部计算key所属subtaskIndex的方法。
值得注意的是,在getKey中我们只需要自行确定每个消息对应的subtask即可,不必与Flink内部的计算逻辑一致。因为我们只关注相同key消息的相对顺序,只需要保证相同key的消息按顺序分配到同一个subtask即可。
而作业的算子处理逻辑如下:
DataStream<ArrayList<Object>> messageList = message
.keyBy(new VirtualKeySelector(jobParallelism))
// countWindow + 复合Trigger的组合使得作业
// 可以在 消息个数达到maxBatchSize 或 等待超过maxWaitInterval时间
// 这两个条件之一满足时触发进行后续处理
.countWindow(maxBatchSize)
.trigger(PurgingTrigger.of(ProcessingTimeoutTrigger.of(CountTrigger.of(maxBatchSize), Duration.ofMillis(maxWaitInterval))))
.aggregate(new MessageAggregator());算子处理代码中的一个细节是只设定聚合的上限等待时间是不够的,如果消息量多大的话会导致聚合的list规模过大甚至造成内存问题。因此还需要额外设定消息的聚合个数上限,作为触发的另一个条件。
看起来方法一很棒,我们用上了keyed state,这使得Flink可以自动帮我们完成算子状态的持久化,从而轻松地完成至少一次的语义。另外,触发条件也基于window + trigger实现,减少了开发的成本。
但方法一存在一个重大缺陷,就是修改并行度(rescaling)后会导致消息保序的要求可能被破坏。
Flink中基于checkpoint,检查点机制来达成运行时的容错机制以及作业的备份迁移等功能。假设当前作业的吞吐量偏低,我们想进行扩容,那就可以先触发一次savepoint(savepoint基于checkpoint),将当前作业的状态持久化到文件中。然后修改并行度后再基于文件恢复就可以保持至少一次的处理语义,因为Flink内部会自行将保存的keyed state进行重新分配。
虽然可能不用掌握keyed state的重分配机制也能理解方法一存在的缺陷,但我们还是展开聊聊这个点。刚刚提到,在内存中keyed state可以理解为Map的数据结构,如果采用最直观的方式将KV顺序的写到文件中,在状态恢复的时候就会导致大量的读IO。因为每个subtask都需要读取全量文件并从中过滤出属于自身的keyed state。如下方(借用)的图所示,保存状态时只是简单的将每个subtask的状态顺序持久化,则当并行度从3增大的4之后,新的subtask对应的keyed state是随机分布的。
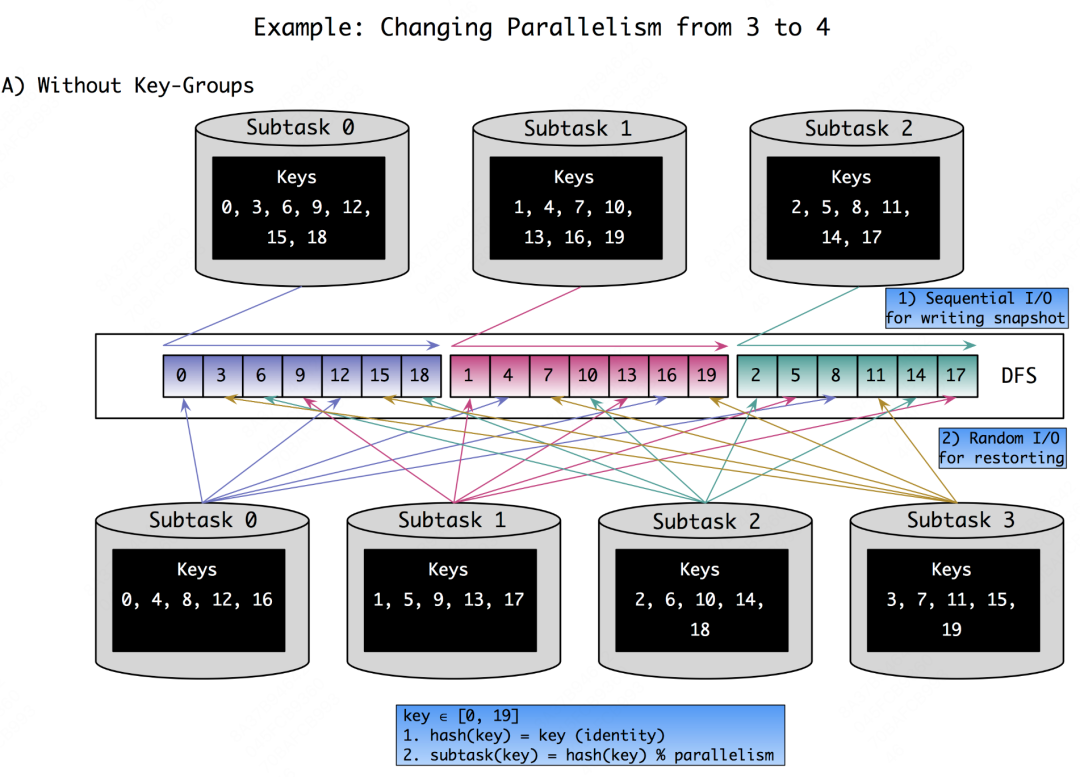
因此,Flink引入了key-group的概念,自认为这和一致性Hash(consistent-hashing)的设计思想非常相近,即目的都是减少rescaling时发生过多的数据迁移。key-group替代细粒度的实际数据KV,成为Flink中状态分配的最小单元。key-group的数量必须在Flink作业启动之前指定,且一旦指定后将无法再做更改。作为keyed state和task之间的“桥梁”,每个消息首先被计算映射到指定的key-group,这一步就是普通的随机shuffle。但key-group与task之间就是“有序”分配了,这样的好处是减少rescaling时状态恢复的成本。具体可以参看下图:
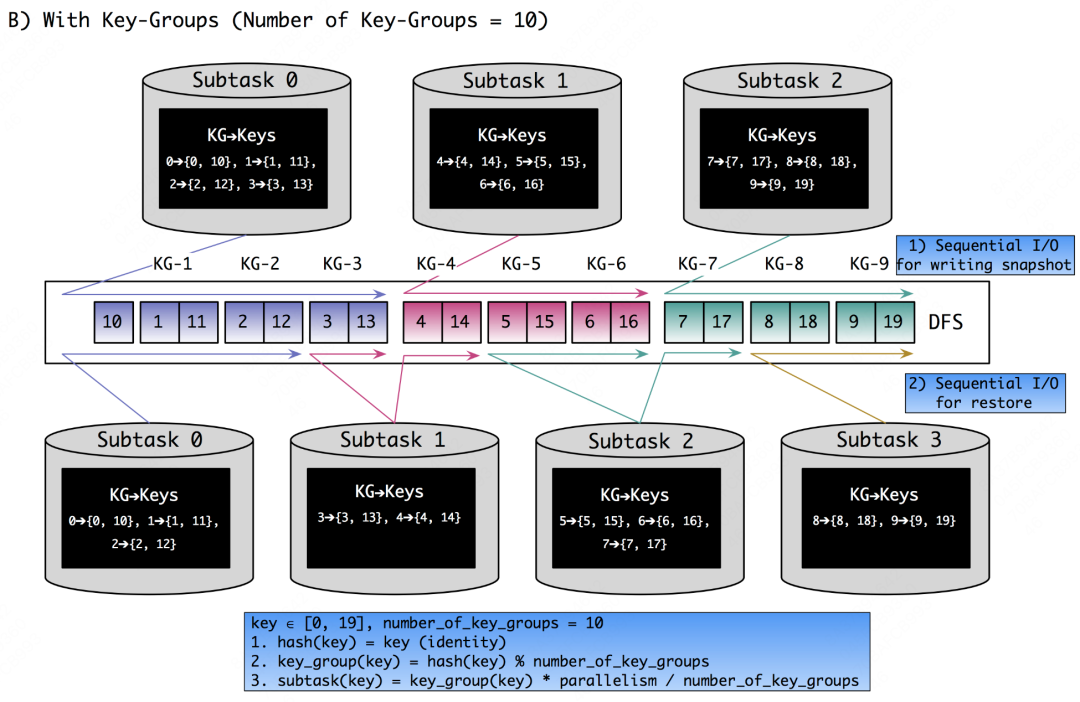
铺垫了这么多,再回头看方法一,就很容易理解其中隐藏的缺陷了。如下图所示,key为A和B的三条消息目前正以虚拟键VK2暂存在内存的keyed state中,并属于KG2和subtask1。在扩容后,KG2被分配到subtask2。由于发生扩容,A和B对应的消息可能被计算后分配到不同的KG,从而属于不同的subtask,结果就是无法保证相同key消息的相对处理顺序了。
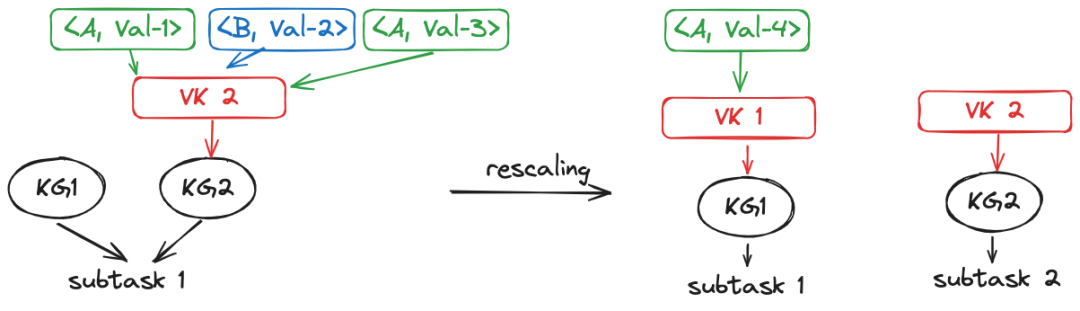
简单一句话总结就是由于keyed state和单独消息在rescaling后对应的subtask不一致所导致的。
那么似乎我们设计一种方式保证单独消息继续和keyed state同属于一个subtask就好?但这样就意味着必然有扩容后的subtask没有数据可处理,相当于没有扩容,显然是不符合预期的。
方法二 算子状态
在想了很久后,我觉得operator state能解决rescaling导致的消息分配问题,当时的大致想法基于两点:
-
算子状态没有了key的束缚,可以直接在subtask的粒度聚合。且getUnionListState方法可以令每个subtask获取完整的持久化的operator state,这样就可以自定义分配状态至每个subtask;
-
同时Flink提供了partitionCustom算子令用户可以自定义消息的shuffle方式,这样在恢复算子状态时只需要保持与partitionCustom一致的消息分配方式就能保证消息的相对顺序。
同样,配合着代码可能更加容易理解些:
(作业算子的处理逻辑)
.partitionCustom(new KeySelectorAndPartitioner(), new KeySelectorAndPartitioner()).process(new MessageAggregator(maxBatchSize, maxWaitInterval))
Partitioner和KeySelector接口的实现:
/**
* 同时实现KeySelector和Partitioner
*/
public class KeySelectorAndPartitioner implements KeySelector<Message, Integer>, Partitioner<Integer> {
/**
* 确定消息的key
*/
@Override
public Integer getKey(Message message) {
return message.getKey().hashCode();
}
/**
* 计算subtask index
*/
@Override
public int partition(Integer key, int numPartitions) {
return Math.abs(MathUtils.murmurHash(key)) % numPartitions;
}
/**
* 判断消息是否属于该分区
*
* @param msg 消息
* @param subtaskIndex subtask index
* @param parallelism 算子并行度
*/
public boolean belongDesignatedTask(Message msg, int subtaskIndex, int parallelism) {
return partition(getKey(msg), parallelism) == subtaskIndex;
}
}ProcessFunction接口的实现:
/**
* 支持扩缩容的批聚合
*/
public class MessageAggregator extends ProcessFunction<Message, List<Message>> implements CheckpointedFunction {
/**
* 持久化的StateDescriptor
*/
private static final ListStateDescriptor<Message> msgListStateDescriptor =
new ListStateDescriptor<>(
"msgListStateDescriptor",
TypeInformation.of(new TypeHint<Message>() {
})
);
/**
* operator state
*/
private transient ListState<Message> checkpointState;
/**
* job运行时消息的聚合buffer
*/
private final LinkedList<Message> bufferedElements;
/**
* 当前缓存的消息个数
*/
private long elementCount;
public MessageAggregator() {
this.bufferedElements = new LinkedList<>();
this.elementCount = 0;
}
/**
* 持久化当前缓存的消息:
* 把buffer中的消息保存到算子状态即可 后续Flink会对于算子状态自行持久化
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointState.clear();
for (Message msg : bufferedElements) {
checkpointState.add(msg);
}
}
/**
* 恢复状态
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// 获取[当前subtask的index]和[算子的并行度]
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
int parallelism = getRuntimeContext().getNumberOfParallelSubtasks();
// 使用和 partitionCustom 相同的shuffle方式
KeySelectorAndPartitioner keySelectorAndPartitioner = new KeySelectorAndPartitioner();
// 基于getUnionListState API获取所有状态
// 基于和前一步的partitionCustom相同的key获取及计算分区方式
checkpointState = context.getOperatorStateStore().getUnionListState(msgListStateDescriptor);
// 如果是基于snapshot重启
if (context.isRestored()) {
// 遍历所有状态 找到属于当前subtask的状态
for (Message msg : checkpointState.get()) {
if (keySelectorAndPartitioner.belongDesignatedTask(msg, subtaskIndex, parallelism)) {
addElement(msg);
}
}
}
}
/**
* 封装添加元素操作
*/
public void addElement(Message msg) {
this.elementCount += 1;
this.bufferedElements.add(msg);
}
}完成上述代码后觉得自己终于找到了一种优雅的方式解决了这个问题(汗),但其他尚未实现的部分却让我发现如此实现甚至不如方法一:
-
由于不是对应keyedStream,在ProcessFunction中无法使用Flink框架提供的定时器服务。当然,这还算小问题,因为对于processingTime,Flink内部也是基于ScheduledThreadPoolExecutor实现的定时器服务。不过,自行实现一个类似Flink中的定时器基本就需要额外开启一个线程,引入的作业不稳定性及代码的复杂度也着实令人抓狂了。
-
更重要的是,我们需要基于ProcessFunction接口的processElement方法来处理元素。而processElement的方法声明长下面这样,我们只需重点关注out变量。Flink框架的意思是对于每个消息,我都会调用一下用户实现的processElement方法,用户想要输出消息就调用out的collect方法。那么,这会导致一个什么样的问题呢?考虑这样一个场景,作业扩容后恢复状态了,但迟迟没有新的消息,那么被恢复的消息就会一直发送不出去(因为Flink一次也没调用processElement方法)。那在作业恢复的时候立马发送持久化的消息不就好了嘛?可惜还是不行,因为out变量只是processElement方法的一个参数😂,Flink不调用processElement方法的话我们就拿不到它,意味着我们无法输出任何消息。
@Overridepublic void processElement(Message value, Context ctx, Collector<List<Message>> out)
方法三 无状态的snapshot
所以,我们真的没有办法在Flink中实现上述功能嘛?办法总比困难多,但不过是无奈的妥协罢了:就是我们不持久化消息了。不持久化消息的好处有二:
-
解决了方法二中状态恢复后的消息滞留无法发送问题,因为没有消息了;
-
也不用担心方法一中状态和新消息被分配到不同subtask而导致的消息保序的问题了,因为没有状态会被分配了。
实现的方式也很简单,就是在snapshot方法中直接把缓存在buffer的消息聚合到list后直接输出给下游。那此时out会不会获取不到呢,即潜在的NPE问题?并不会。因为如果调用snapshotState的时候elementCount大于1,则意味着肯定有元素触发过processElement了,那么我们肯定已经拿到了out引用关联的Flink对象了。
/**
* 清空缓存元素
*/
@Override
public void snapshotState(FunctionSnapshotContext context) {
trigger(1);
assert bufferedElements.isEmpty() && elementCount == 0;
}
/**
* Nothing
*/
@Override
public void initializeState(FunctionInitializationContext context) {}
/**
* 处理元素
*/
@Override
public void processElement(Message value, Context ctx, Collector<List<Message>> out) throws Exception {
// 把方法参数的out赋值给实例变量
this.out = out;
addElement(value);
// batchSize是设定的聚合消息个数上限
// 如果大于batchSize则直接触发一次
trigger(batchSize);
}
/**
* 如果大于给定threshold 则触发一次
*
* @param threshold 1表示必须触发 除非为空
*/
public void trigger(long threshold) {
if (elementCount >= threshold) {
List<Message> temp = new ArrayList<>();
// batchSize是设定的聚合消息个数上限
long toBeDeletedCount = Math.min(elementCount, batchSize);
for (int i = 0; i < toBeDeletedCount; i++) {
temp.add(deleteElement());
}
out.collect(temp);
}
}最后一个问题便是这样的实现方式能否保证至少一次的语义呢?我们不妨看看Flink内部对于checkpoint的实现方式(以下段落大多借鉴《Flink内核原理与实现》)。
快照一般用于作业的快速恢复。而对于Flink这样的流处理引擎来说,分布式快照最关键的是能够将数据流切分。Flink中使用Barrier(屏障)来切分数据流。Barrier会周期性地注入数据流中, 作为数据流的一部分,从上游到下游被算子处理。Barriers会严格保证顺序,不会超过其前边的数据。Barrier将记录分割成记录集,两个Barrier之间的数据流中的数据隶属于同一个检查点。每一个Barrier 都携带一个其所属快照的ID编号。Barrier随着数据向下流动,不会打断数据流,因此非常轻量。在一个数据流中,可能会存在多个隶属于不同快照的Barrier,并发异步地执行分布式快照,如下图所示:
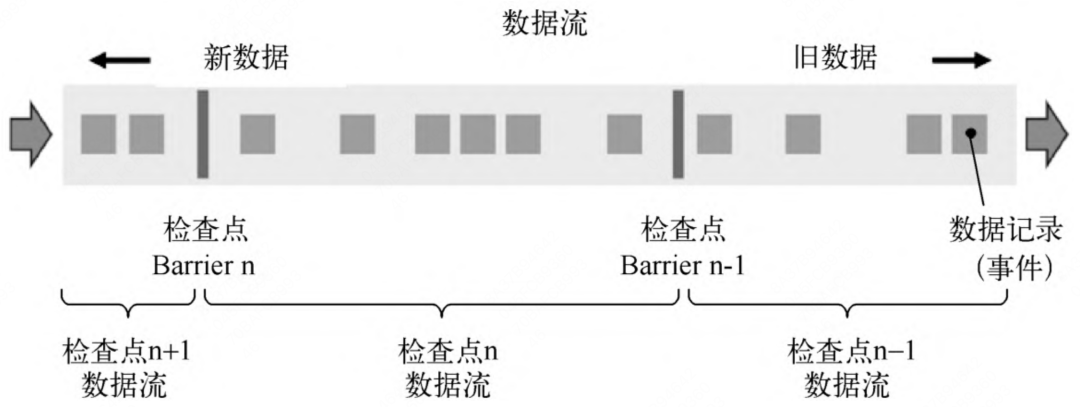
Barrier会在数据流源头被注入并行数据流中。每个Barrier所在的位置就是恢复时数据重新处理的起始位置。Barrier接着向下游传递。当一个非数据源算子从所有的输入流中收到了快照n的Barrier时(并不一定,牵涉到Barrier对齐),该算子就会对自己的State保存快照,并向自己的下游广播送快照n的Barrier。
从作业的角度看,checkpoint的执行流程如下图:
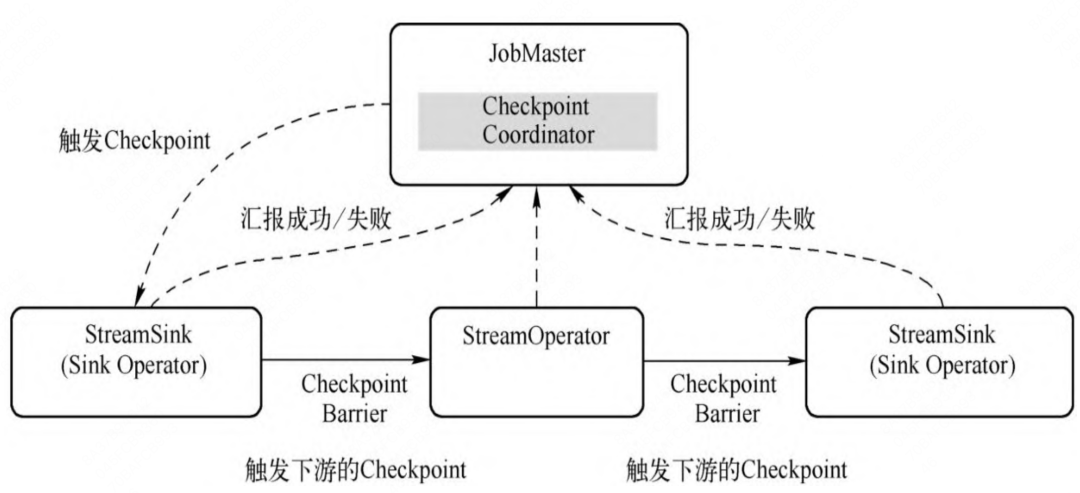
在JobMaster端会远程触发Task的检查点,但Task执行检查点时会区分StreamTask类型。其中SourceStreamTask(数据源)是检查点的触发点,产生CheckpointBarrier并向下游广播,下游的StreamTask(普通的处理算子)根据CheckpointBarrier触发检查点。
令人崩溃的来了,下方代码是Flink框架中StreamTask执行检查点的核心逻辑:
private boolean performCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetrics checkpointMetrics,
boolean advanceToEndOfTime) throws Exception {
final long checkpointId = checkpointMetaData.getCheckpointId();
if (isRunning) {
actionExecutor.runThrowing(() -> {
//...
// All of the following steps happen as an atomic step from the perspective of barriers and
// records/watermarks/timers/callbacks.
// We generally try to emit the checkpoint barrier as soon as possible to not affect downstream
// checkpoint alignments
// Step (1): Prepare the checkpoint, allow operators to do some pre-barrier work.
// The pre-barrier work should be nothing or minimal in the common case.
operatorChain.prepareSnapshotPreBarrier(checkpointId);
// Step (2): Send the checkpoint barrier downstream
operatorChain.broadcastCheckpointBarrier(
checkpointId,
checkpointMetaData.getTimestamp(),
checkpointOptions);
// Step (3): Take the state snapshot. This should be largely asynchronous, to not
// impact progress of the streaming topology
checkpointState(checkpointMetaData, checkpointOptions, checkpointMetrics);
});
return true;
}
}可以看到checkpoint的核心逻辑分为三个step,源码里就有详细的注释对应,分别是:准备工作;向下游广播Barrier;快照当前算子的状态。
为了加快checkpoint的制作时间,Flink内部会先往下游发送Barrier,然后再处理当前算子的状态。而我们在处理算子状态这一步,即snapshotState方法中所做的是继续输出消息。这会导致发送的缓存消息落后于Barrier,导致Flink认为这些消息属于下一个checkpoint了。假设下游算子在收到Barrier后处理完毕,并向JobMaster报告成功之后,还没有处理完这些“落后的消息”的某个时刻宕机了,就会导致一个不正确的checkpoint被制作成功,至少一次的语义被违背了。
发生这个问题的原因是我们的做法违背了Flink的设计思想,snapshotState方法中只能做持久化状态的相关工作。因为Flink假设在Barrier之前的消息不是已经被发送到下游就是被保存在状态里了。
当然,如果作业正常,比如没有反压等情况,则发生丢消息的概率很小。比如我们每10分钟制作一次checkpoint,而作业需要1秒来处理这些滞后的消息,那么只有机器在1/(10 * 60)的时间内宕机才会导致这种情况。















 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











