









目录
3. 自然变换(Natural transformation)
3.2 可表函子(Representable Functor)
1. 范畴论概览
引用Emily Riehl在Category Theory in Context中开篇的那一段来描述什么是范畴论:
阿蒂亚将数学描述为“类比的科学”。在这一领域,范畴论的视野是数学的类比。范畴论提供了一种跨学科的数学语言,旨在勾勒出一般现象,这使得思想可以从一个研究领域转移到另一个领域。范畴论的观点可以作为一个简化的抽象概念,它将那些出于形式原因成立的命题与那些需要特定数学学科的技术来证明的命题隔离开。微妙的视角转变使得数学内容可以用一种对考虑的对象种类相对漠不关心的语言来描述。范畴论的方法不是直接对对象进行刻画,而是强调同一通用类型的对象之间的变换。
范畴论是数学的一个跨学科的领域,它采用了一种新的视角来理解数学现象。与数学的大多数其他分支不同,范畴论对被考虑的对象本身不太感兴趣。相反,它专注于同一类型对象之间以及不同类型对象之间的关系。它的抽象性和广泛性使它能够触及并连接数学的几个不同分支:代数、几何、拓扑、分析等。
范畴论的一个中心主题是抽象,通过概括而不是单独关注它们来理解对象。与分类学类似,范畴论提供了一种将数学概念抽象和统一的方法。其中最重要的米田引理(Yoneda Lemma)使我们能够通过一个对象与其他对象的关系正式定义该对象,这是范畴论所采取的以关系为中心的视角的核心。而这不正就是attention is all you need的另一种诠释么?
接下来我们从定义范畴(Categories)/函子(Functors)和自然变换(Natural Transformations)开始逐渐介绍范畴论,然后展开给出一些有趣的实例,并探索非常重要的米田引理,从这个角度再来看基础大模型的Pre-train过程和后面一系列FineTune过程,最终得到一系列结论指导我们探索的方向。
1.1 范畴的定义
一个范畴由 a universe of objects , and morphisms between them, 注意故意用universe而不是 a set of objects的原因是为了避免罗素悖论,同时我们给出一个小范畴(small category)的定义:
A category is
smallif it has asmall setofobjectsand asmall setofmorphisms.
而这些对象(objects)和态射(morphisms)还需要满足如下条件
-
对于每个对象,存在唯一的恒等态射(identity morphism)
-
对于和,存在一个复合(Composition)
-
任意一个态射,
-
对于任意可复合 ,
Example.1 例如前文所述,“鱿,鲐,鲇,鲸,鲉,鲽” 作为对象,而带有鱼的偏旁部首作为关系构成态射:
-
对于鱿鲐 鲐鲽 ,存在复合 鱿鲽
-
任意一个态射,例如 鱿鲐, 鱿鱿 , 鲐鲐 , 则
-
对于任何Composable ,
因此,我们构造了一个带有鱼的偏旁部首作为关系的范畴,然后它的对象都是单个汉字可以构成一个集合,而所有的关系也可以构成一个集合,那么我们可以说这个鱼关系范畴是小的。
Example.2 如果Attention是一个态射(Morphism), 单词表构成一个对象集合,什么是范畴? Attention复合是否可以通过Transformer的结构定义?幻觉是否和Attention能否构成范畴有关?
问题 如果需要利用Transformer的结构构建成一个大模型范畴,如何对Transformer算子构建 Composable Attention? 这也是当下几乎所有大模型数学能力差的最关键的问题? OpenAI的Q* 算法做了什么?是否可以从范畴论的视角解释?后续的章节中会逐渐展开对这个问题的探讨
1.1.1 态射(Morphism)
对于一个态射,我们可以把它看作一个X到Y的箭头,并记(domain)和(codomain).对于两个对象,所有以X作为domain,Y作为codomain的态射构成
注意 并不一定是一个集合,当对任意,是一个集合时,我们称 is
locally small
既然有态射的domain和codomain,那么如果多个指向一个,或者一个指向多个怎么定义,逆箭头是否存在?自己指向自己呢?,对于这些类型做了如下定义:
同构(isomorphism):令,若存在态射 使得和成立,则称为一个同构态射,也称X与Y同构,记为
如果一个范畴的所有态射都是同构的,我们将它称为一个
Groupoid
Example.1例如Transformer中利用LoRA替代全连接层,如何保证两层之间的Morphism同构呢?
满同态(epimorphism):,如果对于所有的态射, 成立。 类似于函数定义的满射(surjective)
单同态(monomorphism):,如果对于所有(笔误,应该是Z->X)的态射, 成立。类似于函数定义的单射(injective)
自同态(endomorphism): ,即
自同构(automorphism):若一个自同态也是同构的,那么称之为自同构。
问题 一个有趣的话题,我们在谈论异构计算的时候,对应的同构表达是什么?各种异构硬件同构表达的IR层长成什么样?这个同构是在pytorch上模型结构的同构表达,还是张量计算这一层上,还是底层上?是否要兼容CUDA的重构?否则各个异构加速卡都有自己的框架,这样的异构是毫无意义的 另一个问题, 一些针对Transformer的稀疏性的优化是否可行?是否会破坏态射的状态?
1.2 对偶范畴(Opposite Category)
生活中有很多问题是存在对偶的,例如A是B的爸爸,那么B是A的儿子。对于对偶范畴(Opposite Category)也被称为反范畴
For a category , its opposite category is the category obtained by formally
reversingthedirectionofallitsmorphisms(while retaining their original composition law).
在范畴论中对偶(Duality)的定义:
In category theory,
dualityis a correspondence between the properties of a category C and thedualproperties of the opposite category .
Example.1关于对偶和对偶范畴一个典型的例子就是对偶学习[2]
深度学习通常需要大量的数据,有监督学习需要大量的带标注的数据集,但数据标注的成本很高。拿么充分的利用对偶结构来构造数据集成为一种选择

一个典型的对偶学习案例就是GAN(Generative Adversarial Nets),通过学习一个图像生成器和判别器的对偶来构建高质量的生成式图片。
当然对偶范畴在预层(presheaf)中的使用我们将在后面的章节详细叙述
1.3 Initial/Terminal和大模型基础模型
我们来看另一个对偶,对于一个给定的范畴,对于任意, 只包含一个元素,则称为Initial object,即A指向了其它所有对象.如同一个基础的大模型(Fundation Model)可以指向各种任务
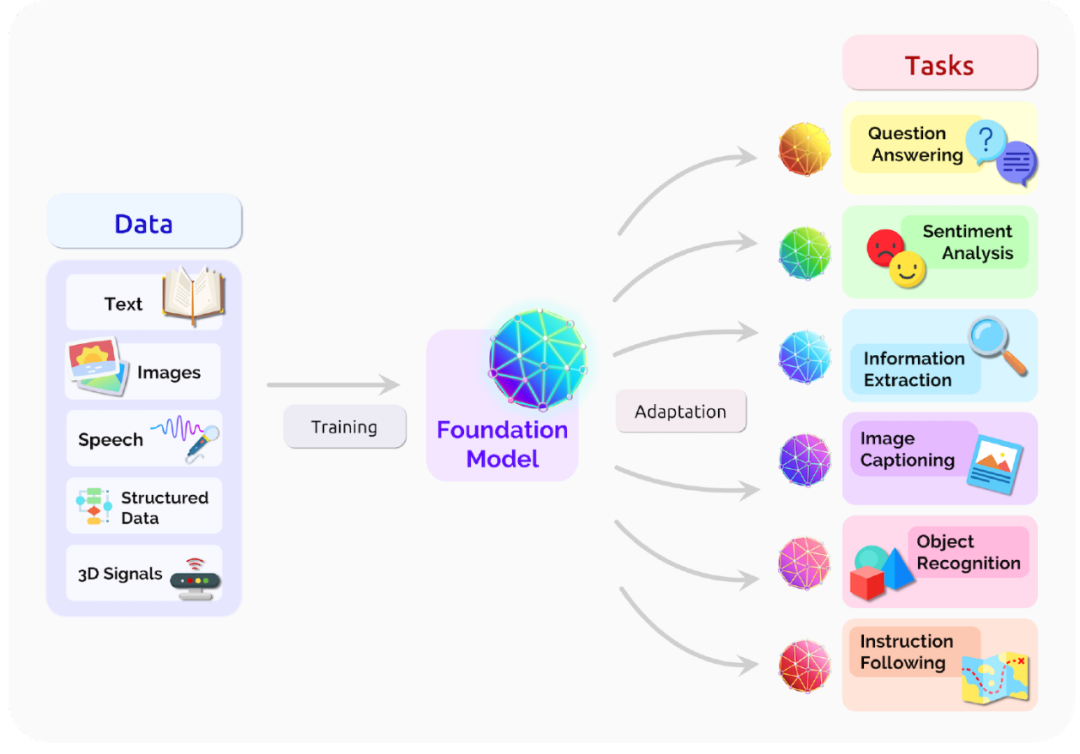
有始就有终,Inital Object的对偶是Terminal Object,Terminal的定义也就是说对于任意, 只包含一个元素。Initial指向所有对象,而Terminal所有对象指向它,本质上大模型的训练的视角来看就是Terminal,将所有的数据通过训练指向基础模型。
我们可以注意到基础模型既是Initial又是Terminal,并且我们可以把它当成一个只有唯一对象的一个范畴,结果如何?
问题 对于提升大模型数学能力,我们应该如何去做呢?对于函数式编程都会定义一个数据类型(),然后基础模型类通过训练构建有态射 Zero::()->Int , One::()->Int ,Two::()->Int ,即Zero()=0,One()=1,Two()=2.当然对于Q* 这类的算法,本质上是需要Transformer类算子是可复合的(Composable),然后就可以自动构造数据集进行自我强化训练了,同时通过A* 搜索Composable态射是否可行?
为什么在这里一再强调需要Compositionality,本质上是Non-Composable需要额外的数据注入
2. Functor(函子)
2.1 函子定义
设是两个范畴,一个函子(Functor) :
-
每个中对象,对应中有一个对象
-
每个中态射,对应中有一个态射
并且满足
-
对于中对象,
-
中任意态射,,有
Example1 在训练集中,训练数据和标签之间有一个态射f,我们期望机器学习模型能够在模型范畴构建态射,以很多语言模型为例,Tokenizer实际上就是一个函子。
Example2 以范畴轮的视角来看待监督学习,Backprop as Functor[3]

2.2 共变/反变函子
Covariant Functor:共变函子,,
Contravariant Functor:反变函子,,
2.3 Faithful/Full
Faithful: 对于每个, , 中文将Faithful翻译成忠实的,简单来说F诱导的映射是单射
Full:对于每个 ,存在,使得, 简单来说F诱导的映射是满射
Fully Faithful:其实就是一个F诱导的映射是双射,中文有个翻译叫完全忠实。
Example1:我们对基础模型的需求就是它和世界范畴的函子是完全忠实的,
2.4 遗忘/自由函子
forgetful functor,即遗忘掉范畴中的一些结构,例如,即一个有复杂代数结构的群范畴到集合范畴的函子.
free functor,一个遗忘函子的反向,我们可以将其定义为自由函子(free functor)例如
2.5 Hom函子
这是一个共变函子(Covariant Functor),它包含
-
范畴C中每个元素X的态射
-
对于每个态射, 则可视为一系列态射构成,其中为中的每个态射.
这是一个反变函子(contravariant Functor),它包含
-
范畴C中每个元素X的态射
-
对于每个态射, 则可视为一系列态射构成,其中为中的每个态射.
对, ,
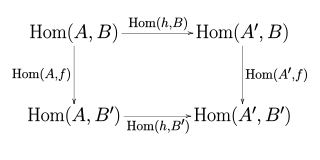
3. 自然变换(Natural transformation)
3.1 定义
设和是范畴,和是和之间的函子,一个从到的自然变换,对中每个对象,n能给出一个在D的对象间的态射,称为在X处的分量(component),使得对中每个态射都有:,用交换图表示为:
如果F和G是反变函子,则将图表中的水平箭头方向反转。若是到的自然变换,可记为或.
F和G之间的自然变换的集合被记为
3.2 可表函子(Representable Functor)
我们可以看到,选择C中的每一个对象,我们可以获得一个从C到Set的函子, 这种指向Set的保持结构的态射,通常被成为一个表示(representable).形式化的定义如下:
一个共变(或反变)函子, C is locally small category, 如果存在一个对象,使得和自然同构(如果F为反变函子,则为),则称函子F是可以被对象A表示的.
Example对于一个机器学习任务,我们通常可以将其看为 ,例如ChatGPT的训练过程来看,预训练就是一种对世界范畴构建可表函子的过程.
详细内容可以参考nLab[4]
3.2 函子范畴(Functor Category)
设和是范畴,的函子范畴的对象是,态射是所有这些函子的自然变换,复合律是基于Vertical composition,即假设Functor , , vertical composition即. 的函子范畴记为
3.4 Presheaf预层
函子范畴中最重要的一个例子就是预层(presheaf)范畴,记为, Presheaf是C上的一个函子, 上的所有presheaf构成的对象和presheaves之间的自然变换构成态射,这样的范畴被成为预层范畴。
Example 对于一个对象A,大模型的预训练过程实际上是通过尽量多的数据来构建A和其它对象的Attention的集合,实际上是,它是一个反变函子,也可记为,我们注意到 Presheaf是C上的一个函子。本质上大模型的预训练过程实际上就是需要构造一个预层范畴。
可能您读到这里感觉都是一些抽象的废话(Abstract nonsence),但这些内容都是为后面的米田引理做前置知识的铺垫
4. 米田引理
米田(Yoneda)引理得名于日本数学家兼计算机科学家米田信夫(Nobuo Yoneda).大白话来说如果能够理解:“人的本质是一切社会关系的总和”,大概就清楚了它的核心了
4.1 Yoneda Lemma
给定一个局部小范畴上的预层,对于C中的对象,有
4.2 Yoneda Embedding
对于一个局部小范畴,每个对象包含一个C上的预层:可表示的预层(representable presheaf),实际上也就构成了一个的函子,这些函子构成预层范畴。Yoneda Lemma 这些函子是完全忠实(Fully faithful)的,即任何局部小范畴中的对象都可被对应的预层范畴中的元素表示
问题 这不正是我们对基础大模型泛化的要求么? 大模型的预训练的本质不就是构建预层范畴么?
另一方面
而的函子完全忠实的,那么
于是, 当且仅当它们对应的Hom函子同构。而这个推论来看,我们可以说:"对象由它与其他对象之间的关系完全决定"
5. 小结
这一篇基本上是对范畴论for ML的一个科普性质的介绍,其中有很多不严谨的地方。但是作为一个大模型的从业人员,特别是数据科学家,AI Infra的建设者,掌握范畴论的知识,对于模型结构设计,基础设施优化方向的确定是很有帮助的。
例如在降低Transformer的计算量时,稀疏Transformer或者MoE是否会破坏态射结构? Transformer算子的可组合性如何设计?通过这样顶层的抽象视角会得出不少有价值的答案。当然还有很多范畴论的内容,例如limit/colimit,以及相应约束下的强化学习和基于Hom函子去构造数据,最终来提高大模型的逻辑推理能力,范畴论视角下函数式编程和大模型的融合,这些都是非常值得我们去深思的问题,或许这也部分回答了OpenAI Q* 的一些解法,我们拭目以待...
















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











