







目录
随着 AI 和 HPC 数据集的大小不断增加,为给定应用程序加载数据所花费的时间开始对整个应用程序的性能造成压力。 在考虑端到端应用程序性能时,快速的 GPU 通过缓慢的 I/O 将显著降低GPU的利用率。
I/O 是将数据从存储加载到 GPU 进行处理的过程,历来由 CPU 控制。 随着计算从较慢的 CPU 转移到更快的 GPU,I/O 越来越成为整体应用程序性能的瓶颈。
正如 GPUDirect RDMA(远程直接内存地址)在网络接口卡 (NIC) 和 GPU 内存之间直接移动数据时改善了带宽和延迟一样,一种名为 GPUDirect Storage 的新技术支持本地或远程存储(例如:NVMe 或 NVMe over Fabric (NVMe-oF))与GPU 内存之间的直接移动数据。
本文将针对硬盘的发展、NVMe的技术原理以及NVMe在AI服务器及DeepSpeed框架中的应用进行详细的介绍。
衡量硬盘传输速度的三大要素
要知道一块硬盘真正的性能,就要知道如何衡量一块硬盘速度?通常情况下,我们从以下三个方面进行评估:通讯协议(总线)、物理接口标准、传输通道。
传输通道/总线
总线是计算机系统内部各个组件之间传输数据的通道。硬盘通过总线与其他系统组件(如主板、内存等)进行通信。总线的速度直接影响着硬盘的数据传输速度。
常见的总线/通道类型包括SATA(Serial ATA)和PCI Express。SATA是较为常见的硬盘连接总线,而PCI Express则通常用于更高性能的存储解决方案。其他的通道有SAS通道(企业级别硬盘用的通道)、FC通道(光纤通道)等。
通讯协议
协议定义了数据在总线上的传输方式和规则。其内容主要包括设备间如何相互识别、如何建立链接、使用的讯号类型、数据的编码解码方式、数据传输的类型、数据传 输的方式以及物理层面上的电压、电流、保持时间和截止时间等。
只有当两个设备之间的协议相同或者相容时,才可以正常进行通讯。不同协议能够支持的最大传输速率也不同。
常见的通信协议如下:
| 协议名称 | 应用场合 | 说明 |
|---|---|---|
| IDE | 民用 | 机械硬盘时代,用于数据操作,传输的协议。目前已被淘汰。 |
| AHCI | 民用 | 仍然是机械硬盘时代的主流数据传输协议。但SATA固态硬盘和极少数PCIe固态硬盘可以使用此协议,用SATA通道优化后的效率相比IDE提升10-30%。 |
| NVMe | 民用 | 由于机械硬盘和固态硬盘的工作模式发生巨大变化,需要一种全新的针对固态的传输层协议,NVMe 应运而生。NVMe协议相比传统的AHCI协议具有更低的延迟和更高的数据传输速度,适用于高性能要求的应用。 |
| SCSI | 服务器 | SCSI(Small Computer System Interface)协议是一种通用的存储协议,最初是一种并行接口,后来也演变为串行接口(SAS,Serial Attached SCSI)。 常见于企业级固态硬盘,消费级市场不常见。但其设计并非专门针对固态硬盘,可能在利用硬件特性方面不如NVMe。 |
不同的硬盘可以采用不同的数据传输协议。例如,SATA 上的硬盘通常使用AHCI(Advanced Host Controller Interface)协议,而PCIe(PCI Express)上的硬盘可能使用NVMe(Non-Volatile Memory Express)协议。
物理接口
接口是硬盘与计算机或其他设备之间物理连接的方式。硬盘接口通常是指连接到主板的插槽或端口。常见的硬盘接口包括 M.2、SATA、PCI Express等。
不同的接口也会影响硬盘的数据传输速度,因为不同接口支持的总线和协议可能有所不同。
常见的硬盘接口类型:
-
PCI Express(PCIe): PCI Express接口用于连接高性能固态硬盘(NVMe SSD)和一些扩展卡。NVMe(Non-Volatile Memory Express)是一种用于固态存储的高效协议,通常与PCI Express接口结合使用,提供更高的传输速度和更低的延迟。
-
M.2(NGFF): M.2是一种小型、高密度的接口,用于连接固态硬盘和一些无线通信设备。M.2接口通常支持AHCI协议(走SATA通道)和NVMe协议(走PCI Express通道),适用于轻薄型笔记本电脑和台式机。
-
SATA(Serial ATA): SATA是目前最为普遍的硬盘接口之一,用于连接传统的机械硬盘(HDD)和固态硬盘(SSD)。它是一种串行数据传输接口,提供了不同版本,如:SATA I(1.5 Gbit/s)、SATA II(3 Gbit/s)、SATA III(6 Gbit/s)等。
-
SAS(Serial Attached SCSI): SAS是一种用于连接企业级硬盘的接口,提供了更高的性能和可靠性。SAS接口通常用于服务器和存储系统,支持更高的数据传输速度和更多的同时连接。
-
mSATA: mSATA是一种用于连接小型存储设备的接口,通常用于一些较老的笔记本电脑和嵌入式系统。它支持SATA。
-
IDE(PATA): IDE(Integrated Drive Electronics)是一种较老的硬盘接口,也称为PATA(Parallel ATA)。这种接口用于连接传统的机械硬盘和光盘驱动器,已经逐渐被SATA接口所取代。
-
SCSI:SCSI是一种用于连接计算机和外部设备的通用接口标准,也用于连接一些服务器和存储设备上的硬盘。SCSI有多个版本,包括并行SCSI和串行SCSI。
总之,硬盘接口技术在不断进化革新,从早期的IDE、SCSI接口到主流的SATA、SAS接口,再到M.2、PCIe接口。
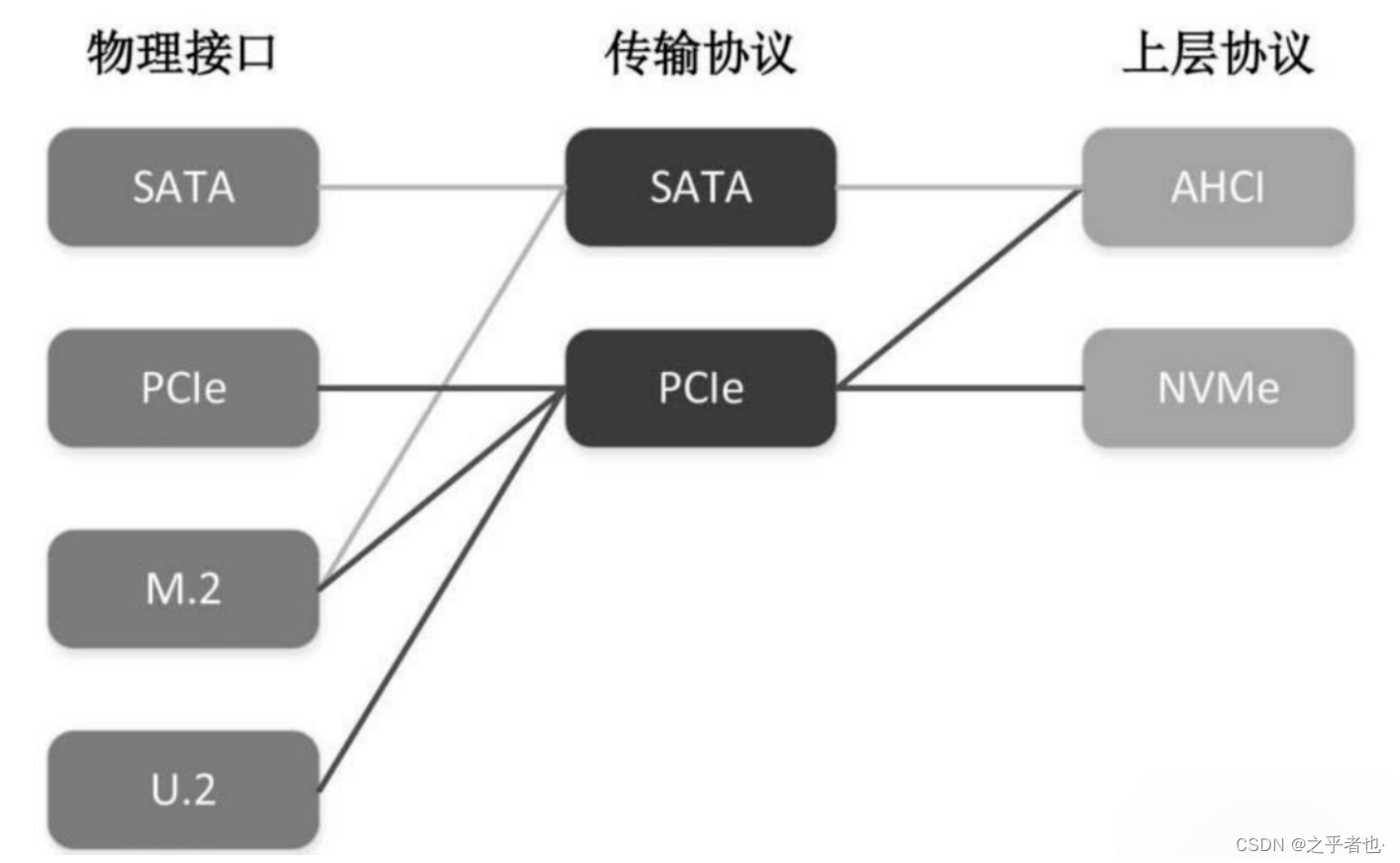
可以看到,SATA、PCIe 即是一种物理接口标准,也是总线(通道)标准,其中,SATA接口使用AHCI通讯协议;PCIe接口通常使用NVMe通讯协议,也可以使用AHCI通讯协议。
硬盘
机械硬盘
机械硬盘(HDD)是一种带有机械马达结构的存储装置,主要带有马达、盘片、磁头、缓存。
固态硬盘
固态硬盘(SSD)是一种不带有机械马达结构的存储装置,主要带有闪存、主控芯片、缓存。
固态硬盘外形尺寸
固态硬盘存在多种外形和尺寸,如:2.5 英寸、M.2、mSATA 和 U.2。
**2.5"(2.5 英寸)**:最常见的固态硬盘类型,适用于多数笔记本电脑或台式机。其外形类似传统机械硬盘 (HDD) 并通过 SATA 线缆连接,因此使用起来与众多现有产品非常类似。
M.2:另一种外形尺寸, M.2 已变成纤薄便携式计算机和笔记本电脑的标配存储类型。这种小巧的外形尺寸常常类似于一片口香糖,在多数情况下可轻松安装到主板上。它具备各种不同长度,可实现不同的固态硬盘存储容量;硬盘越长,可搭载的 NAND 闪存芯片越多,从而实现更高存储容量。
mSATA:mSATA 或 mini-SATA 是全尺寸 SATA 固态硬盘的缩小版。它像 M.2 一样使用紧凑的外形尺寸,但两者不可互换。M.2 硬盘支持 SATA 和 PCIe 两种接口选项,而 mSATA 仅支持 SATA。这种外形尺寸专为空间受限的小型系统设计。
U.2 :它看起来像 2.5 英寸硬盘,但略微厚一点。它使用不同的连接方式,并通过 PCIe 接口发送数据。U.2 固态硬盘技术通常用于需要更大存储容量的高端工作站、服务器和企业应用。它支持更高工作温度,比 M.2 外形尺寸更利于散热。
固态硬盘接口类型
常见的固态硬盘接口类型:
-
SATA(Serial ATA): SATA接口是一种常见的硬盘接口,广泛用于连接传统的机械硬盘和固态硬盘。SATA接口有不同的版本,包括:SATA I(1.5 Gbit/s)、SATA II(3 Gbit/s)、SATA III(6 Gbit/s)等。
-
PCI Express(PCIe): PCI Express接口是一种高速串行总线,用于连接固态硬盘和其他高性能设备。通过PCIe接口连接的固态硬盘通常使用NVMe(Non-Volatile Memory Express)协议,提供更高的数据传输速度和更低的延迟。
-
M.2(NGFF): M.2是一种小型、高密度的接口,广泛用于连接固态硬盘和无线通信设备。M.2接口支持SATA和PCI Express协议,适用于轻薄型笔记本电脑和台式机。
-
mSATA: mSATA是一种较老的小型接口,用于连接固态硬盘。它采用SATA协议,通常用于一些较老的笔记本电脑和嵌入式系统。
-
U.2: U.2是一种适用于企业级硬盘的接口,支持SATA和PCI Express协议。U.2接口通常用于连接高性能企业级固态硬盘,提供更大的功率和散热能力。
M.2 固态硬盘类型
M.2 固态硬盘包含 SATA 和 NVMe(使用PCIe) 两种类型。
注意:M.2 固态硬盘仅兼容支持 M.2 插槽的主板。检查计算机的主板,确保包含 M.2 插槽。
M.2接口类型分为Socket 2和Socket 3:
-
Socket 2:也可以叫做B key,支持sata,pcie x2 通道。
-
Socket 3:也可以叫做M key,支持sata,pcie x4 通道。
一开始,B key的只能插在B key(Socket 2)的接口中,M key的只能插在 M key(Socket 3)的接口中,但是随着M key接口的普及,越来越多电脑主板只有M key 接口,B key的固态硬盘根本插不上去,于是厂商们又设计了一个B&M key接口的固态硬盘(SSD)。
B&M key接口即可以插上B key也可以插上M key。B&M key支持的通道和B key支持的通道一样,都是sata和pcie x2 通道,但是 B&M key可以兼容 M key 和 B key两种,而B key只能兼容B key一种,这就导致了B key毫无优势,B key被B&M key取代,现在市面上只有B&M key和M key两种M.2 ssd卖, B key的 M.2 SSD 已经绝迹。
注意:固态硬盘(SSD)的金手指有B key,B key ,B&M key三种,但是主板上的M.2接口只有B key和M key两种。
SATA M.2 固态硬盘:
SATA 固态硬盘是性能最低的固态硬盘,采用的接口与机械硬盘相同。尽管如此,SATA 固态硬盘的带宽是旋转式机械硬盘的三到四倍。SATA M.2 固态硬盘使用的 SATA 接口最大数据传输速率为 6Gbps。SATA 固态硬盘比 NVMe 固态硬盘更加普及、更加便宜。如果计算机没有空间安装 2.5 英寸固态硬盘,SATA M.2 固态硬盘可能是 2.5 英寸固态硬盘的出色替代选项。
如图所示,同时具有 M 键和 B 键的 M.2 固态硬盘将是 SATA 固态硬盘。
SATA 一直是用于存储技术的主要接口。使用 SATA 线缆的 SATA 硬盘需要两根线缆才能工作。一根用于将数据传输到主板,另一根用于连接 PSU(电源)。当使用多个 SATA 存储硬盘时,杂乱无章的线缆是可能影响 PC 机箱性能的问题之一。包括超级本在内的纤薄笔记本电脑和便携式计算机甚至没有空间来安放 SATA 线缆,所以需要采用 M.2 的外形尺寸。SATA M.2 外形尺寸的固态硬盘解决了这个问题,它没有其他 SATA 存储硬盘所使用的两个线缆连接。
NVMe M.2 固态硬盘
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











