







目录
什么是模态?
在人工智能中,模态(modality)是指一种表达或感知信息的方式,例如文本、图像、视频、音频等。
每一种信息的来源或形式,都可以称为一种模态。
人类生活在一个由多种模态信息构成的世界,我们可以通过视觉、听觉、触觉、嗅觉等感官来接收和理解外部的信息,也可以通过语言、文字、图画、音乐等方式来表达和传递信息。
不同的模态之间可以相互补充和增强,也可以相互冲突和干扰,从而影响我们的认知和交流。
多模态之前的模型是什么样子?
在人工智能的发展历史上,大多数的模型都是基于单一模态的数据来进行学习和推理的。
我们一起看几个不同领域的例子。大家在看这些例子的时候,可以只关注输入数据类型和输出结果类型,毕竟我们这篇文章重在介绍多模态的概念,对中间的模型框架不做过多的涉及。
基于文本的自然语言处理模型:
情感分析:分析文本中的情感色彩,确定评论或文章中的情感倾向(正面、负面、中性)。输入:文字 --> 输出:情感类别
命名实体识别 (NER):从文本中提取具有特定意义的实体,如人名、地名、组织机构等。输入:文字 --> 输出:实体类别及名字
文本摘要:利用文本生成简洁的摘要,提取关键信息而不失去原文主旨。输入:文字 --> 输出:文本
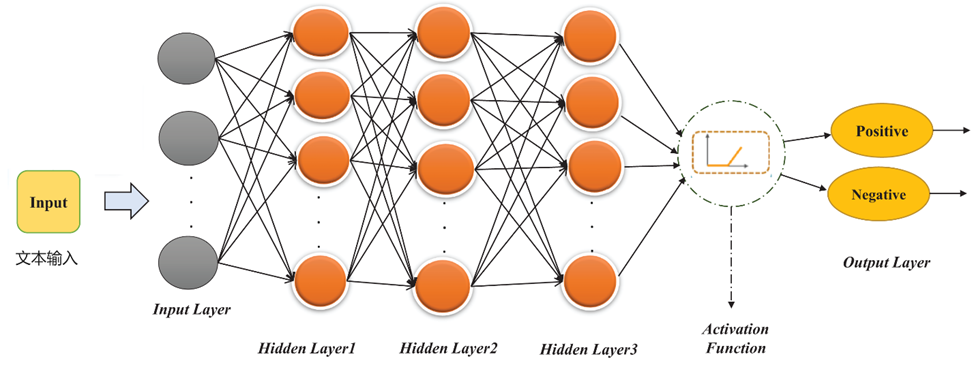
情感分析模型:输入为文本,输出为某类情感
基于图像的计算机视觉:
图像分类:将图像分为不同的类别,例如猫、狗、汽车等。输入:图像 --> 输出:类别
目标检测:在图像中定位和标识多个对象,例如检测图中的行人、车辆、建筑物等。输入:图像 --> 输出:对象类别 + 对象图中位置
图像生成:使用生成对抗网络 (GANs) 生成逼真的图像,例如生成艺术品、虚构的人脸等。输入:图像 --> 输出:新图像

图片目标检测,Image Source: https://mofii-notes.readthedocs.io/en/latest/paper-reading/detr.html
基于音频的语音识别:
语音转文本:将说话内容转换为文本,用于自动化转写、语音搜索等。输入:音频 --> 输出:文本
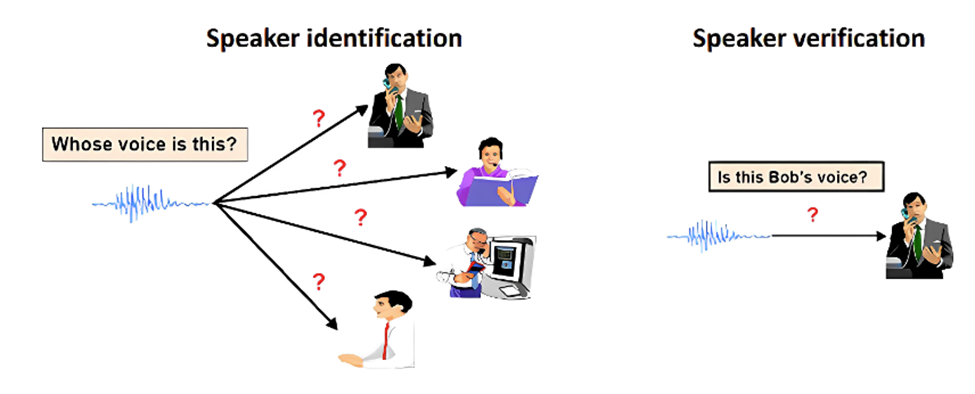
说话人识别:识别说话者的身份,用于身份验证或个性化服务。输入:音频 --> 输出:说话者
情感分析:通过分析语音中的语调和语速来识别说话者的情感状态。输入:音频 --> 输出:某类情感
这些模型虽然在各自的领域取得了很多成就,但也存在一些局限性,例如:
单一模态的数据往往是不完整和有噪声的,不能充分反映真实世界的复杂性和多样性。例如,一段文本可能没有描述清楚一个场景的细节,一张图像可能没有表达出一个物体的功能。
单一模态的模型往往是孤立和封闭的,不能有效地与其他模态的数据和模型进行交互和融合。例如,一个文本生成的模型可能无法根据图像的内容来生成合适的描述。
相比而言,我们人类认知世界的方式是通过多种感官,例如视觉、听觉、味觉、嗅觉、触觉等,这些感官可以让我们感受到外界的光、声、味、香、温等各种刺激,从而形成我们的感知和认知。
我们的大脑再加以综合,就可以把这些感知和认知转化为知识、思维、情感、创造力等高级的心智功能。
那模型能否做到这一点呢?答案是肯定的,这就是下面要介绍的多模态模型。
什么是多模态模型?
多模态模型是指能够处理和整合多种模态的数据和信息的模型,例如图像+文本、视频+音频、语音+文字等。
多模态模型的目的是利用不同模态之间的互补和协同,来提高模型的性能和泛化能力。
大家可能看过4D电影,通过整合多种感官体验,4D可以使观众深度地参与到故事或者画面中。引人入胜的视觉效果创造沉浸式体验,音响系统提升了听觉感知。释放特定香味进一步丰富了的感官体验,而座位跟随情节摇动使得现场氛围更加逼真动人。

类似地,多模态模型通过整合不同类型的数据,提高了模型的全面感知和综合能力,使其能够更贴近真实世界,应对更多复杂的任务和场景。
多模态模型可以细分为以下几种类型:
跨模态模型(Cross-modal model):
指能够在不同模态之间进行转换和生成的模型,例如文本到图像、图像到文本、语音到文字、文字到语音等。这类模型的挑战是如何在不同模态之间建立有效的对应和映射关系,以及如何保留和传递不同模态之间的语义和风格信息。
所以可以把跨模态模型看成一位造诣深厚的艺术大师,可以将一部作品演绎为不同的艺术形式,将作品的主题和情感完美传达给观众。例如将一段音乐演绎为一个舞蹈等。
例如下面这个模型将图片输出为文本描述。
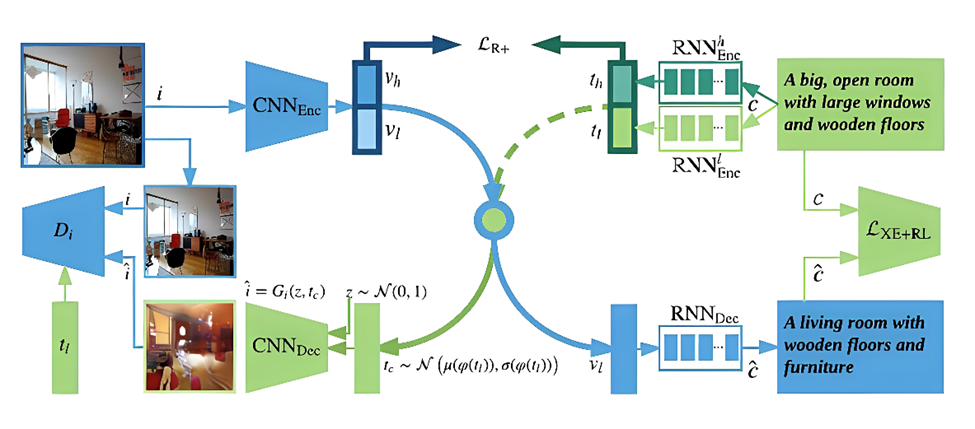
Image Source: https://www.researchgate.net/figure/The-proposed-generative-cross-modal-learning-framework-GXN-The-entire-framework_fig1_321160918
联合模态模型(Joint-modal model):
指能够同时处理和分析多种模态的数据的模型,例如图像+文本分类、视频+音频检索、语音+文字翻译等。
这类模型的挑战是如何在多种模态之间进行有效的对齐和匹配,以及如何利用多种模态之间的相互增强和约束。
我们可以将其比喻为一个协作默契的艺术团队。这个团队由专业领域的艺术家组成,每个艺术家擅长一种特定的表达方式,如绘画、音乐、舞蹈等。然而,这些艺术家都具有高度的协同能力,能够共同创作一个完整的作品。
在这个比喻中每个艺术家相当于一个模态:就像每个艺术家代表一种艺术形式,每个模态代表数据的一种类型,例如文本、图像、音频等。
就像联合模态模型可以协同处理不同模态的数据,这个艺术团队通过各自的专业领域共同创作一个综合且多元的作品。
混合模态模型(Hybrid-modal model):
常指的是将不同模态的数据直接组合或混合在一起进行处理,而不一定强调模态间的交互或共享信息。每个模态可能在独立的分支中进行处理,然后再进行整合。
跨模态模型更强调不同模态之间的交互和信息共享。它试图通过在模型的各个部分中引入跨模态注意力机制或其他交叉连接的方式,使得不同模态的信息能够更深层次地影响彼此。
我们举几个多模态模型的应用和例子。
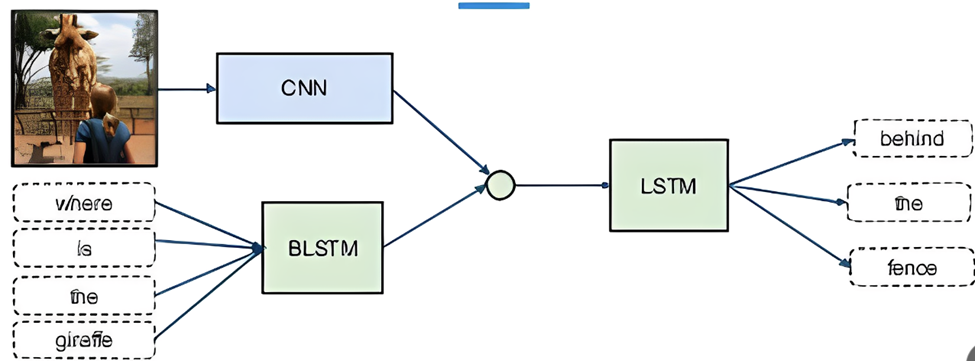
首先在下面这个模型中,输入为一幅图片和一个问题,模型的输出为问题的答案。结合图片和问题Where is the giraffe, 模型给出答案:behind the fence。
下面这个多模态神经网络的同时可以输入房子的图像、文本和结构化数据(例如面积、楼层等),以更全面地学习和预测房价。
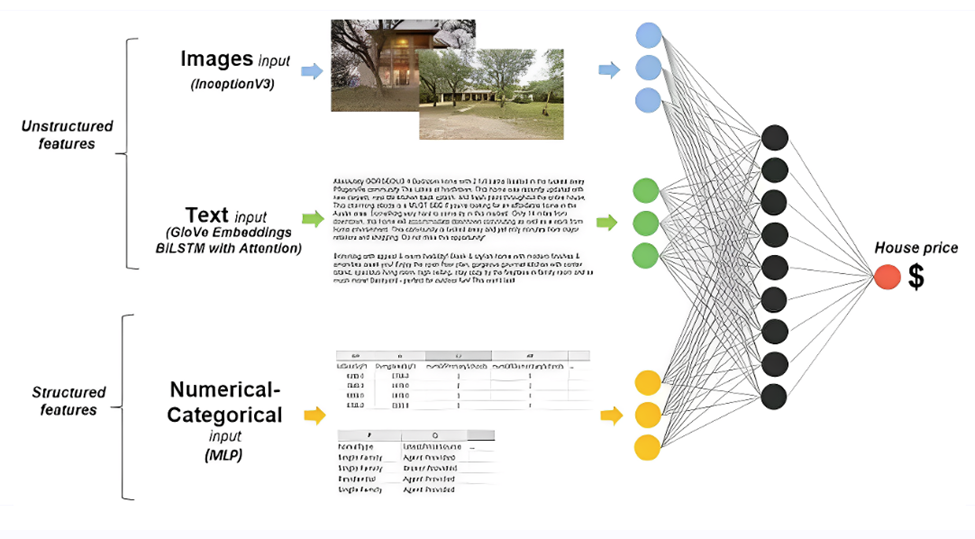
Image source:https://medium.com/@dave.cote.msc/hybrid-multimodal-neural-network-architecture-combination-of-tabular-textual-and-image-inputs-7460a4f82a2e
下面这个是一个阿尔茨海默诊断多模态深度学习模型。输入数据有三种类型:临床数据,基因数据,和影像数据。整个过程的目的是结合临床,基因,和影像数据,来诊断阿尔茨海默病痴呆的程度。

Image source:https://aliporetinytots.com/?u=multimodal-deep-learning-for-alzheimer-s-disease-dementia-assessment-vv-0qzJ3Mf6
下面是处理和分析多模态医学图像的一个模型,它有四种类型的医学脑部图像,分别标注为Flair,T1,T1c,和T2。所有类型的图像都输入到相应的多路径编码器中。最后的输出结果,是一个经过分析和处理的图像,显示特定的脑部区域。
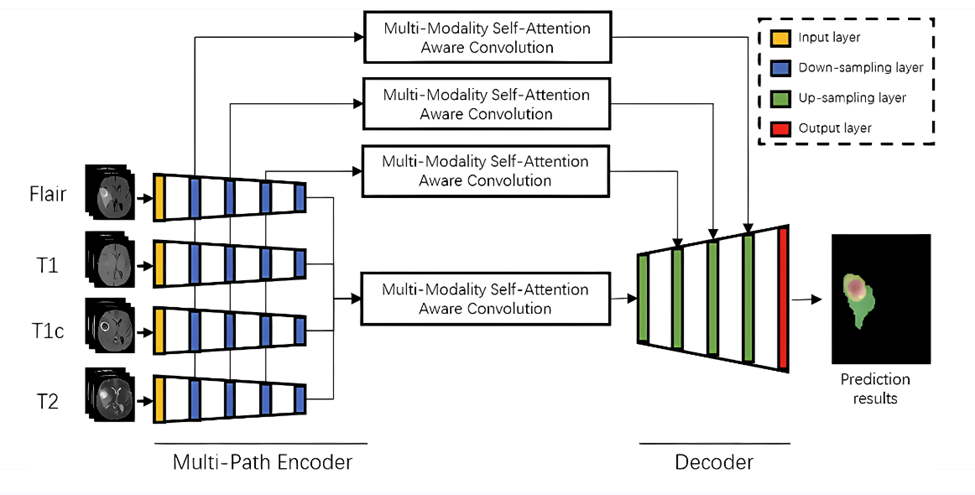
Image source:https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-020-1109-0/figures/3
多模态模型解决了什么问题?
人类的认知和交流是基于多种感官的信息,如视觉、听觉、触觉等。
多模态模型通过模仿和增强这种多感官的能力,对不同类型的数据和信息,如文本、图像、视频、音频等,进行学习、理解和融合,从而使模型能够更好地模拟人类感知和认知的复杂性,为人工智能的研究和应用带来了许多新的可能性和机遇。
多模态数据的引入丰富了模型的输入和输出,使其变得更加多样化,从而增强了模型的性能和泛化能力,同时也提升了模型的鲁棒性和可解释性。在一些问题中,多模态模型展现出更为显著的性能提升和强大的能力。
例如,一个情感分析的模型,如果能够同时利用语音的声音信息和文本的语义信息,就可以更好地理解说话者的情绪和意图,提供更好的情感分析结果并给出更为合理和全面的结果解释。
多模态模型不仅可以实现单一模态的任务,如文本分类、图像识别等,还可以实现跨模态的任务,如文本到图像、图像到文本、图像到语音等。
这些任务可以通过在不同模态之间进行转换和生成,以及在多种模态之间进行组合和变换,来满足不同的需求和场景。
例如,一个文本到图像的模型,可以根据给定的文本描述,生成相应的图像,从而实现图像的自动创作和编辑。这样的模型可以应用于艺术创作、教育辅助、广告设计等领域。
多模态模型是未来的趋势吗?
多模态模型是人工智能的一个重要的发展方向,它不仅可以提高单一模态模型的性能和泛化能力,也可以实现更多的功能和应用,以及模拟和扩展人类的认知和交流。
现在流行的大模型很多是多模态模型,例如Open AI的GPT-4,Google的Gemini等。这些模型都具有强大的数据处理和生成能力,可以跨越不同的领域和任务,如自然语言理解、计算机视觉、自然语言生成、图像生成、视频生成、音频生成等。
这些模型的优势在于它们可以利用不同模态之间的关联和互补,提高模型的表达和理解能力,以及创造和推理能力。
例如,GPT-4可以根据一段文本生成一张与之相关的图像,或者根据一张图像生成一段与之相关的文本,从而实现图文互动和融合。
Gemini可以根据一段视频和一个问题生成一个与之相关的答案,或者根据一个答案和一个问题生成一个与之相关的视频,从而实现视频问答和生成。
结语
多模态是一种表达或感知信息的方式,它涉及到多种信息的来源或形式,例如文本、图像、视频、音频等。
多模态模型是能够处理和整合多种模态的数据和信息的模型,它可以分为跨模态模型、联合模态模型和混合模态模型三种类型。
多模态模型的出现和发展,为人工智能的研究和应用带来了许多新的可能性和机遇,也是人工智能的一个重要的发展方向。
本文介绍了多模态的概念和意义,以及一些多模态模型的例子,希望这篇科普文章对您有所帮助,感谢阅读!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











