




前言
在实现高并发的分布式系统中,服务间调用的RPC也会面临高并发的场景。在这样的情况下,我们提供服务的每个服务节点就都可能由于访问量过大而引起一系列的问题(业务处理耗时过长/CPU飚高/频繁GC/服务进程直接宕机等等)。但是在生产环境中,我们要保证稳定性和高可用性,就要对微服务系统进行自我保护,从而保证高访问量、高并发。
RPC调用中的服务端自我保护最通用的做法就是限流,限流本身也有很多种做法,令牌桶、漏桶(单机),redis+lua脚本(分布式)。而本文要分析的是调用端分别是如何进行自我保护的,这里就引出了文章的主角 -- 熔断。
定义
服务治理中的熔断机制,指的是在发起服务调用的时候,如果被调用方返回的错误率超过一定的闻值,那么后续的请求将不会真正发起请求,而是在调用方直接返回错误。
需要熔断的几种场景:
1.服务依赖的资源出现大量错误。
2.某个用户超过资源配额时,后端任务会快速拒绝请求,返回"配额不足"的错误,但是拒绝回复仍然会消耗一定资源,有可能后端忙着不停发送拒绝请求,导致过载。
技术设计
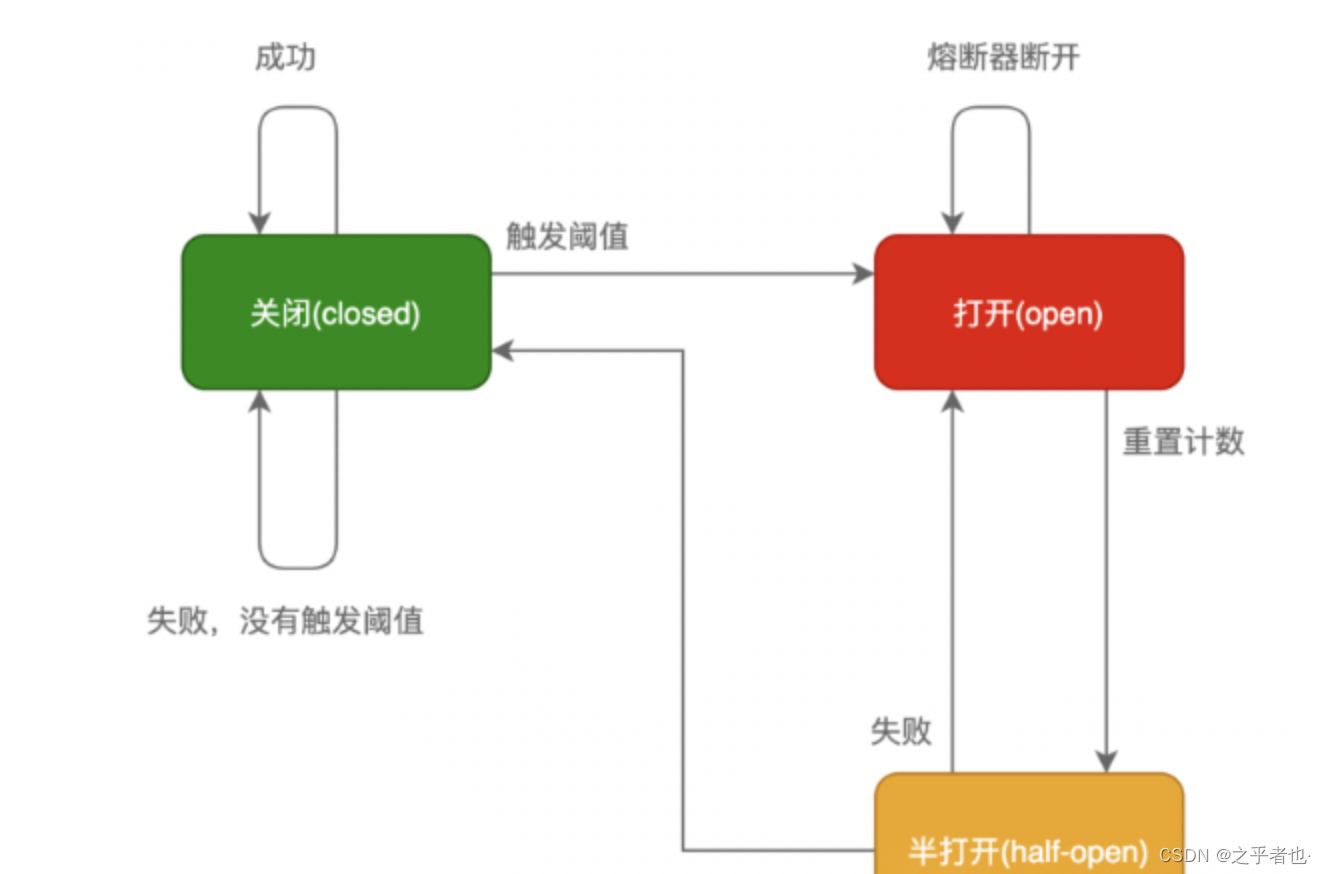
熔断器工作机制主要是关闭、打开和半打开这三个状态之间的切换。在正常情况下,熔断器是关闭的;
当调用端调用下游服务出现异常时,熔断器会收集异常指标信息进行计算,当达到熔断条件时熔断器打开,这时调用端再发起请求会直接被熔断器拦截,并快速地执行失败逻辑;
当熔断器打开一段时间后,会转为半打开状态,这时熔断器允许调用端发送一个请求给服务端,如果这次请求能够正常地得到服务端的响应,则将状态置为关闭状态,否则设置为打开。
注意:熔断器打开有两个条件-QPS超过多少以及错误率达到多少。如果QPS特别低,只有2,错了1个请求错误率就50%了,这个时候肯定是不能打开熔断器的。所以要同时判断错误率和QPS。
用户通过设置熔断规则(Rule)来给资源添加熔断器,修改配置文件时会将每一个熔断规则转换成对应的熔断器,熔断器对用户是不可见的。最终实现的每个熔断器都会有自己独立的统计结构。
熔断器的整体检查逻辑可以用几点来精简概括
1.基于熔断器的状态机来判断对资源是否可以访问;
2.对不可访问的资源会有探测机制,探测机制保障了对资源访问的弹性恢复;
3.熔断器会在对资源访问的完成态去更新统计,然后基于熔断规则更新熔断器状态机;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











