







【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型
【论文原文】:DEGREE A Data-Efficient Generation-Based Event Extraction Mode
【作者信息】:I-Hung Hsu , Kuan-Hao Huang, Elizabeth Boschee , Scott Miller , Prem Natarajan , Kai-Wei Chang , Nanyun Peng!
论文:https://arxiv.org/pdf/2108.12724.pdf
代码:https://github.com/PlusLabNLP/DEGREE
博主关键词:少样本事件抽取,提示学习,标签语义
推荐论文:Event Extraction by Answering (Almost) Natural Questions、Retrieval-Augmented Generative Question Answering for Event Argument Extraction
摘要
事件抽取需要专家进行高质量的人工标注,这通常很昂贵。因此,学习一个仅用少数标记示例就能训练的数据高效事件抽取模型已成为一个至关重要的挑战。在本文中,我们关注低资源端到端事件抽取,并提出了DEGREE,这是一个数据高效模型,将事件抽取表述为一个条件生成问题。给定一篇文章和一个手动设计的提示,DEGREE学会将文章中提到的事件总结成一个遵循预定义模式的自然句子。然后用确定性算法从生成的句子中抽取出最终的事件预测。DEGREE有三个优势,训练数据少,学得好。首先,我们设计的提示(prompts)为DEGREE提供语义指导,以利用标签语义,从而更好地捕获事件论元。此外,DEGREE能够使用额外的弱监督信息,例如提示中编码的事件描述。最后,DEGREE以端到端的方式联合学习触发词和论元,这鼓励模型更好地利用它们之间的共享知识和依赖关系。实验结果表明,DEGREE算法在低资源事件抽取方面具有良好的性能。
1、简介
事件抽取(EE)旨在从给定的段落中抽取事件,每个事件由一个触发词和几个具有特定角色的参与者(论元)组成。例如,在图1中,Justice:Execute事件是由单词“execution”触发的,该事件包含三个论元角色,包括执行执行的Agent(Indonesia)、被执行的Person(convicts)和事件发生的Place(文中未提到)。之前的工作通常将EE分为两个子任务:(1)事件检测,它识别事件触发词及其类型;(2)事件论元抽取,它抽取给定事件触发词的论元及其角色。EE已被证明有益于广泛的应用,例如,构建知识图谱,问答,以及其他下游研究。

大多数先前关于EE的工作依赖于大量的标注数据进行训练。但是,获得高质量的事件标注的成本很高。例如,使用最广泛的EE数据集之一ACE 2005语料库需要语言学专家进行两轮标注。高昂的标注成本使得这些模型难以扩展到新的领域和新的事件类型。因此,如何学习仅用少量标注示例的数据训练高效EE模型是一个至关重要的挑战。
在本文中,我们专注于低资源事件抽取,其中只有少量的训练示例可用于训练。我们提出了DEGREE (Data-Efficient GeneRation-Based Event Extraction,基于数据高效生成的事件抽取),这是一种基于生成的模型,它将段落和手动设计的提示(prompt)作为输入,并学习按照预定义的模板将文章总结成自然的句子,如图2所示。然后可以使用确定性算法从生成的句子中抽取事件触发词和论元。
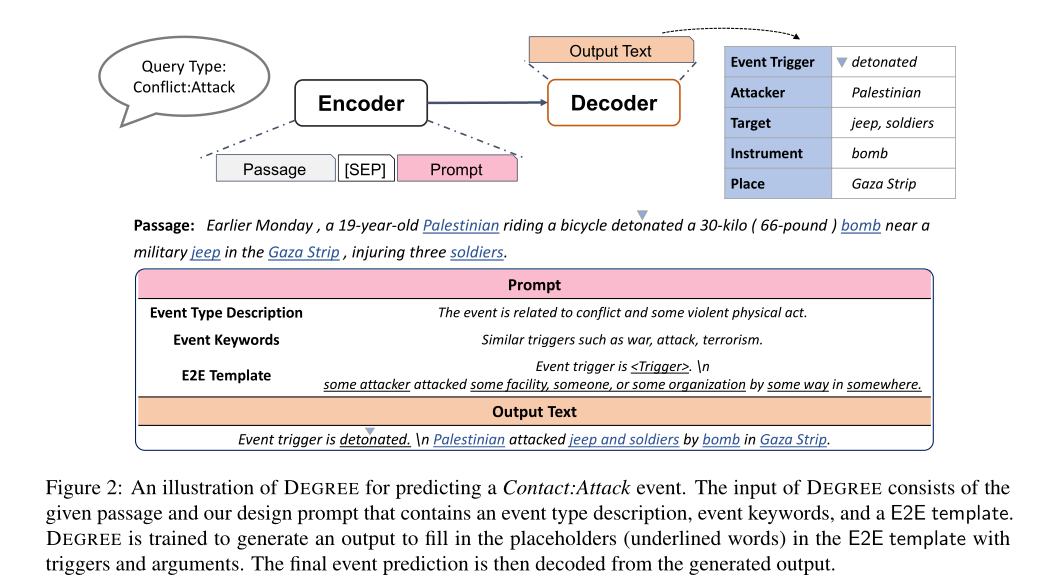
DEGREE具有以下优势,训练数据少,学得好。首先,框架通过提示中设计的模板提供标签语义。如图2中的示例所示,提示符中的单词“somewhere”指导模型预测与角色Place的位置相似的单词。此外,该模板的句子结构和“攻击”一词描述了角色“attacker”和角色“target”之间的语义关系。有了这些指导,DEGREE可以用更少的训练示例做出更准确的预测。其次,提示(prompt)可以包含关于任务的附加弱监督信号,例如事件描述和类似的关键字。这些资源通常很容易获得。例如,在我们的实验中,我们从标注指南中获取信息,标注指南随数据集一起提供。这些信息有助于DEGREE在资源不足的情况下学习。最后,DEGREE设计用于端到端事件抽取,可以同时解决事件检测和事件论元抽取问题。利用两个任务之间的共享知识和依赖关系使我们的模型数据效率更高。
现有的EE研究通常只具备上述一两个优点。例如,以前基于分类的模型很难对标签语义和其他弱监督信号进行编码。最近提出的基于生成的事件抽取模型以管道方式解决了这一问题;因此,他们**(生成的事件抽取模型)不能利用子任务之间的共享知识**。此外,它们生成的输出不是自然句子,这阻碍了标签语义的利用。因此,我们的DEGREE模型在低资源事件抽取方面可以获得比以前的方法更好的性能,我们将在第3节中演示。
我们的贡献可归纳如下:
- 我们提出了DEGREE,这是一种基于生成的事件抽取模型,通过更好地结合标签语义和子任务之间的共享知识,可以用更少的数据进行更好的学习(第2节)。
- ACE 2005和ERE-EN的实验证明了DEGREE在低资源环境下的强大表现(第3节)。
- 我们在低资源和高资源环境下进行了全面的消融研究,以更好地理解我们模型的优缺点(第4节)。
3、实验
我们进行了低资源事件抽取的实验,以研究DEGREE的表现。
3.1 实验设置
数据集:ACE 2005(ACE05-E、ACE05-E+)、ERE-EN。
低资源下的数据划分设置:我们生成不同比例(1%,2%,3%,5%,10%,20%,30%,50%)的训练数据来研究训练集大小的影响,并使用原始开发集和测试集进行评估。附录C列出了更多关于数据划分生成过程和数据统计的详细信息。
评估指标:Trigger F1-score、Argument F1-score。
对比baseline:OneIE、BERT_QA、TANL、Text2Event.
3.2 主要的结果
表2给出了三个训练数据占比不同的数据集的触发词分类F1-scores和论元分类F1-scores。结果如图3所示。由于我们的任务是端到端事件抽取,所以在比较模型时,论元分类F1-score是我们考虑的更重要的度量。
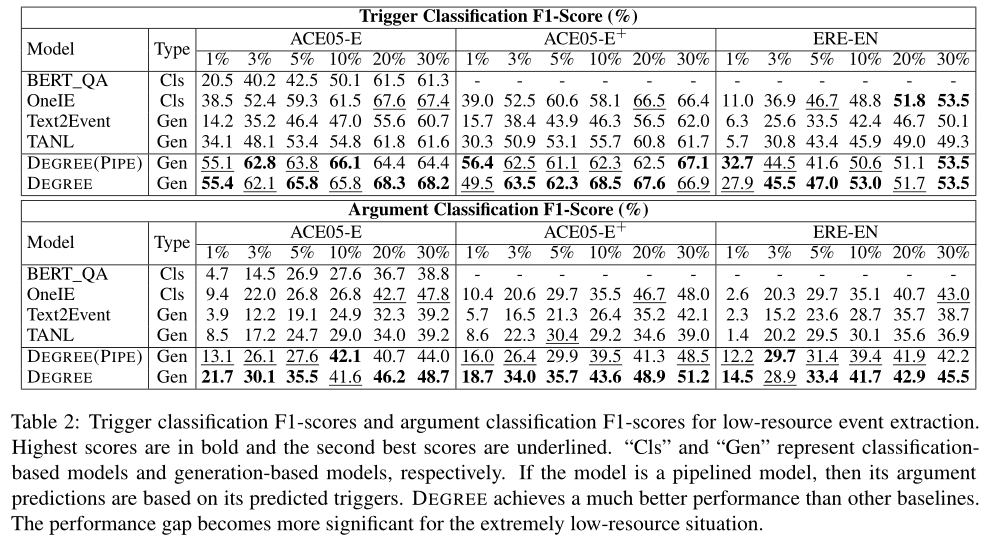
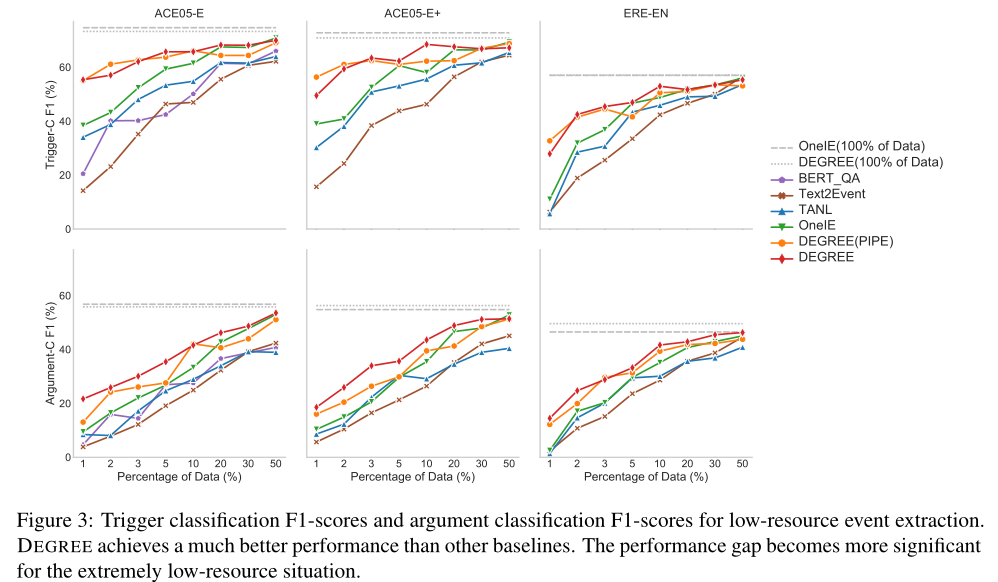
从图3和表2中,我们可以观察到,当使用不到10%的训练数据时,DEGREE和DEGREE(PIPE)都优于所有其他基线。在极低数据的情况下,性能差距变得更加显著。例如,当只有1%的训练数据可用时,DEGREE和DEGREE(PIPE)在触发词分类F1分数上取得了超过15分的提高,在论元分类F1分数上取得了超过5分的提高。这证明了我们设计的有效性。基于生成的模型,经过精心设计的提示,能够利用标签语义和额外的弱监督信号,从而帮助在低资源条件下的学习。
另一个有趣的发现是,DEGREE和DEGREE(PIPE)似乎更有利于预测论元,而不是预测触发词。例如,最强的基线OneIE需要20%的训练数据来实现对DEGREE和DEGREE(PIPE)的触发词预测的竞争性能;然而,它需要大约50%的训练数据才能在预测论点方面达到竞争性表现。原因是,对于论元预测来说,捕获依赖关系的能力比触发词预测更重要,因为与触发词相比,论元通常是相互强烈依赖的。因此,我们的论元预测模型的改进更为显著。
此外,我们观察到,在低资源设置下,DEGREE略优于DEGREE(PIPE)。这为在低资源环境中联合预测触发词和论元的好处提供了经验证据。
【论文速递 | 精选】

















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











