







概要:总结ollama、vllm部署大模型的特点、步骤及注意事项。langchain接入本地大模型可能遇到的问题。
零、基础准备
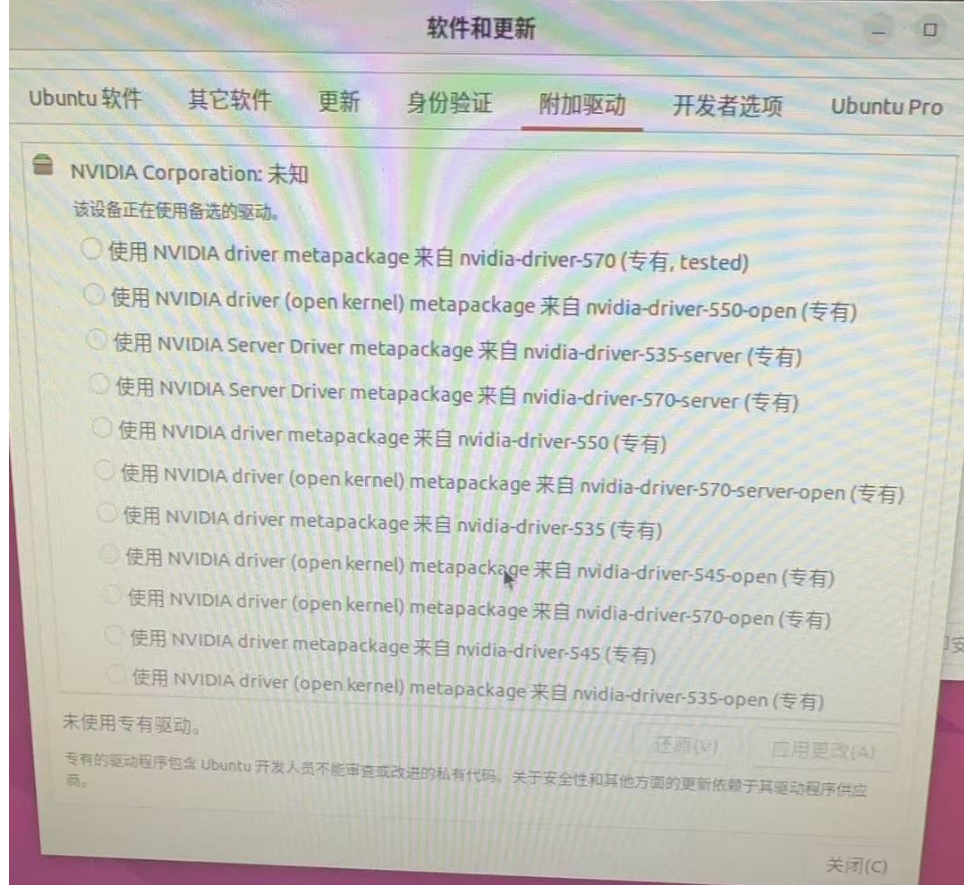
如果你只有CPU,只想做一些简单测试,那么这步可以跳过。如果你想使用GPU,则需要先安装驱动。Windows就去官网下载安装包,如:NVIDIA-GRID-WHQL-512.95.exe。ubuntu推荐在【软件和更新】里的【附件驱动】里选择你要的版本,一键安装。通过命令行安装比较麻烦,容易出错。
一、ollama
ollama部署大模型,过程比较简单,不易出错。但缺点是并发性能较差,前段时间还爆出安全性问题。适合个人或实验阶段。支持llama、deepseek、千问等模型,框架支持mac、Linux、Windows。
mac和windows安装应用,可视化操作,没什么额外需要讲的。这里总结基于容器的部署。
1、拉取官方镜像
docker pull ollama/ollama如果不了解docker的,可以先看下这篇总结:
docker安装使用基础_docker 安装使用-CSDN博客
2、创建容器
# -v 是路径挂载,主要为了同步模型文件。/llm/models是宿主机的路径,名字无所谓
docker run -d --gpus=all -v /llm/models:/llm/models -v /llm/ollama:/root/.ollama -p 22515:11434 --restart=always --name ollama ollama/ollama3、启动模型
# 进入容器
docker exec -it ollama /bin/bash/
# 执行,会自动下载模型文件,也可以自行下载后上传,将deepseek-r1:70b替换为你的路径
ollama run deepseek-r1:70b4、使用
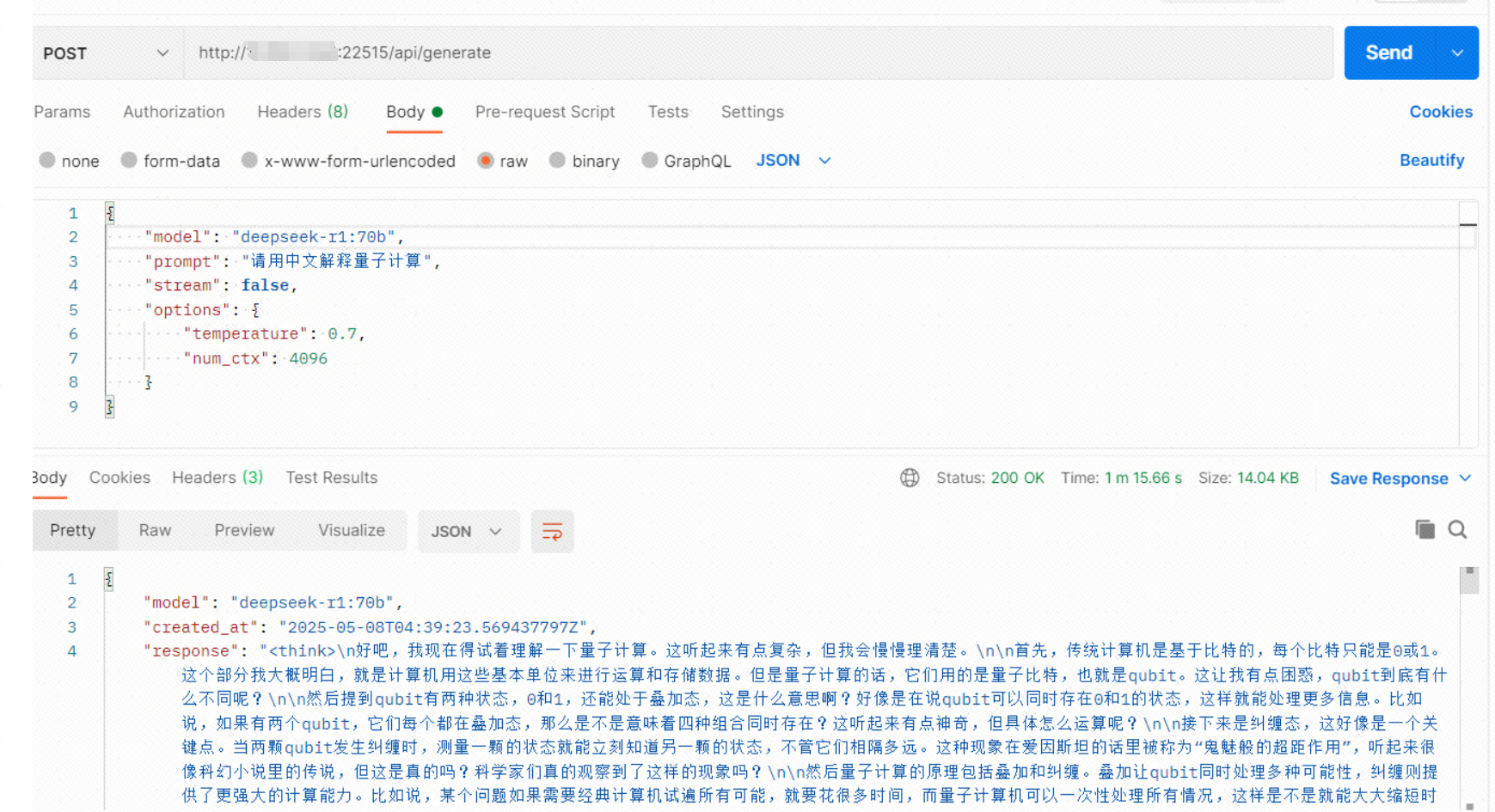
启动后会自动进入对话窗,可以做一些简单测试。另外,默认开启API接口,使用postman测试如下:(注意:我对外的端口不是默认的11434)
二、vllm
相对于ollama,vllm部署大模型稍微复杂一点。但优势在于能够更好的使用多张显卡,提供多种加速推理的技术,如混合精度(FP16)和张量并行(Tensor Parallelism)等。推理速度和并发性能更强,适合企业正式部署。
1、拉取包含驱动的基础镜像
其实最复杂的就是驱动的问题,所以有现成的镜像可用,直接解决了一半问题。如果不想研究版本的,可以直接参考我的。
# 更多版本详见https://catalog.ngc.nvidia.com/orgs/nvidia/containers/cuda-dl-base/tags
docker pull nvcr.io/nvidia/24.10-cuda12.6-devel-ubuntu22.042、创建容器
# --mount 路径挂载的另一种方式
docker run --restart=unless-stopped --mount type=bind,source=/AI-Agent/models,target=/AI-Agent/models --gpus all --name ai_model -p 22525:22525 -it your_image_id /bin/bash3、配置容器环境
# 安装python环境,推荐conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 创建一个新的python环境
conda create --name python311 python=3.11.11
conda activate python311
# 安装vllm
pip install vllm==0.8.04、启动模型
前面创建容器时,做了路径挂载,你需要把下载好的模型放到这个路径。
(Qwen3建议使用vllm0.9.0)
# CUDA_VISIBLE_DEVICES:指定使用的显卡编号
# tensor-parallel-size:张量并行数,和前面指定的显卡对应
# swap-space:每个GPU配置的内存交换 G,主要考虑显存波动时,需要动态CPU支持
# --cpu-offload-gb:直接卸载一部分权重到CPU,对响应速度影响较大
# max-num-seqs:并发数
# gpu-memory-utilization:每张显卡占用的上限
# --dtype half:半精度,可选参数值:auto,half,float16,bfloat16,float,float32
# float16,bfloat16都是16位,首位表示正负,剩下15位。float16:5+10,bfloat16:8+7
# float16能表示的数值范围较小,但小数位更多,精度更高
# --max-model-len:单个输入token长度限制
# --max_num_batched_tokens:总吞吐量,考虑并发请求
# --enable-lora:开启lora,通过矩阵分解降低参数量
# --kv-cache-dtype:设置kv缓存精度,如fp8,也可降低显存需求
# --served-model-name:取一个名字,默认是路径名字,调用接口时需要传递
# --quantization:量化方式:aqlm,awq,deepspeedfp,tpu_int8,fp8等
# --enable-reasoning --reasoning-parser deepseek_r1/qwen3 需要深度思考并指定解析方式
# --enable-auto-tool-choice --tool-call-parser hermes 需要工具解析
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m vllm.entrypoints.openai.api_server --model /AI-Agent/models/deepseek-r1-70b --port 22525 --tensor-parallel-size 8 --swap-space 16 --max-num-seqs 16 --gpu-memory-utilization 0.8 --dtype half --max-model-len 10240 --served-model-name dsk70b5、调用接口
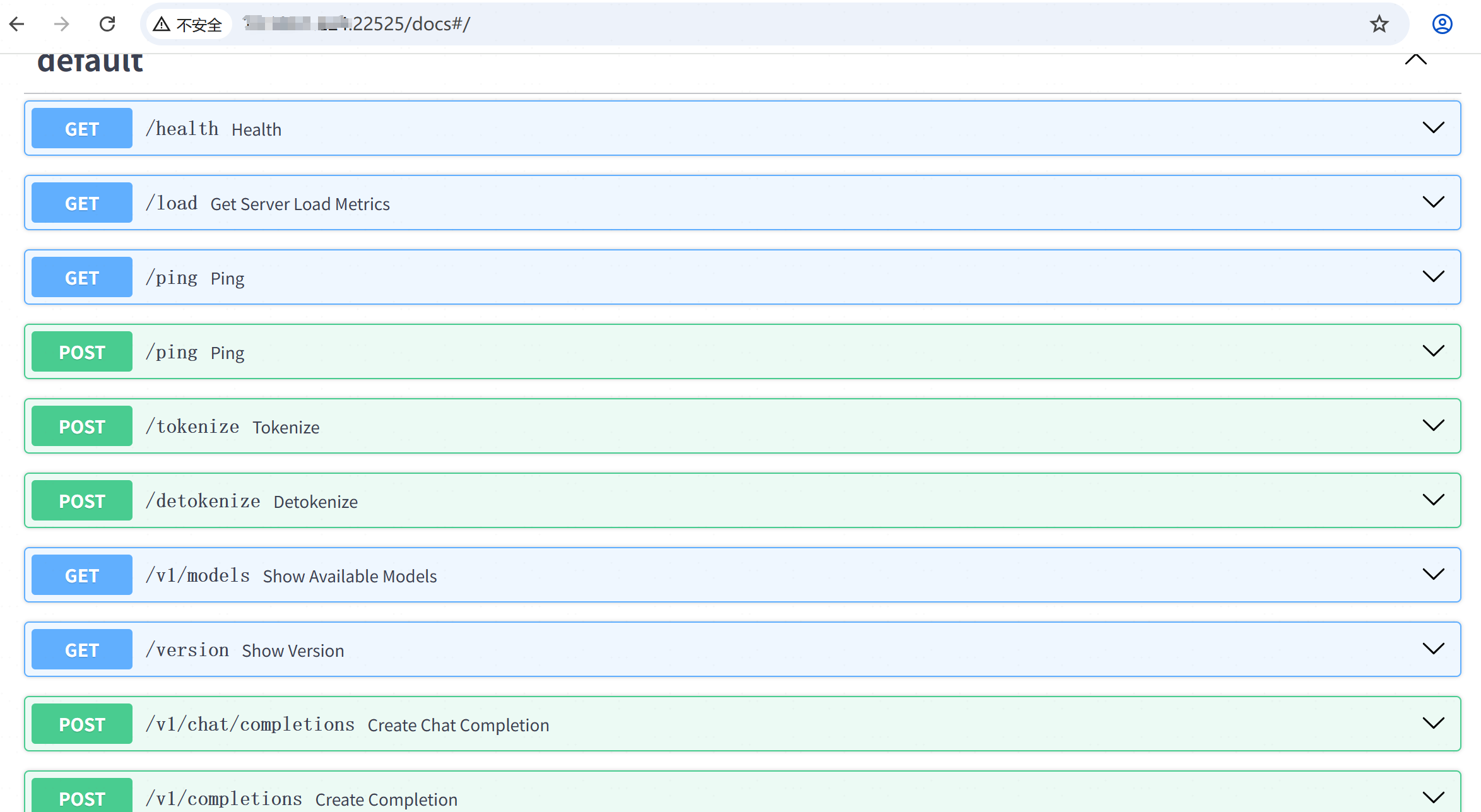
因为vllm的接口部分使用的是fastapi,其提供了一个文档接口,其中v1/chat就是对话窗口。兼容langchain中的ChatOpenAI接口。
三、问题解决
1、启动时写入临时文件失败
如果你跟着上述步骤操作,那么大概率会遇到NCCL运行错误,通过增加参NCCL_DEBUG=INFO可以大致看到,启动时往路径/dev/shm写入文件失败。这是因为这个文件夹是默认的临时文件夹,容量受限,可以根据自己的模型大小修改。
重新生成容器:
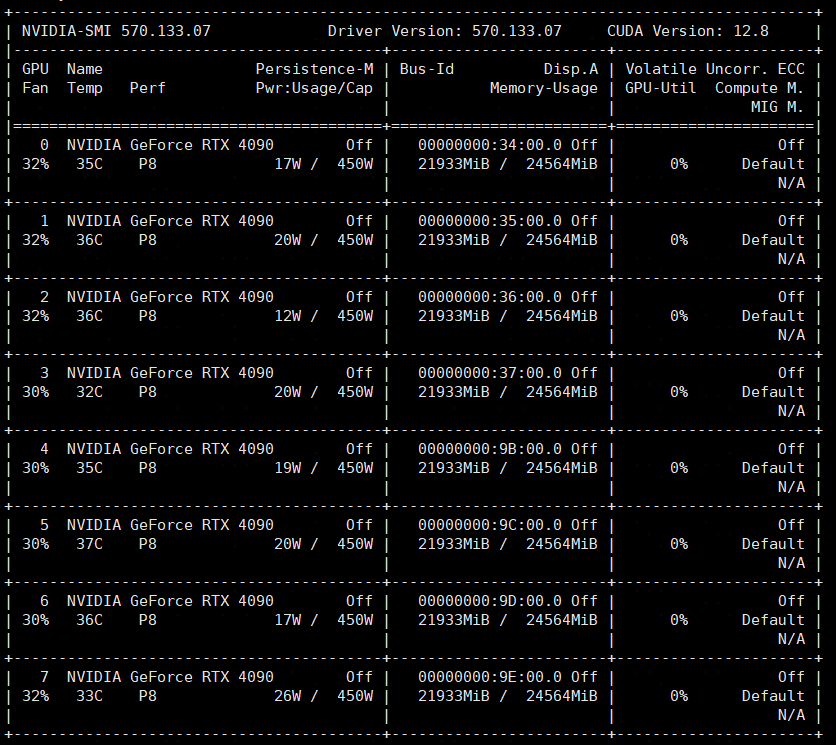
docker run --shm-size=128G ……模型启动后,通过nvidia-smi命令查看显卡占用情况:
2、分词器下载失败
如果将本地模型接入Agent,并且使用langchain_openai.ChatOpenAI去接入该服务。会涉及一个token计算过程,如果遇到下载失败或你的环境不允许访问外网,会出现如下报错信息:
File "/root/anaconda3/lib/python3.11/site-packages/tiktoken_ext/openai_public.py", line 76, in cl100k_base
mergeable_ranks = load_tiktoken_bpe(
^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/tiktoken/load.py", line 148, in load_tiktoken_bpe
contents = read_file_cached(tiktoken_bpe_file, expected_hash)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/tiktoken/load.py", line 63, in read_file_cached
contents = read_file(blobpath)
^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/tiktoken/load.py", line 22, in read_file
resp = requests.get(blobpath)
^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/requests/api.py", line 73, in get
return request("get", url, params=params, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/anaconda3/lib/python3.11/site-packages/requests/adapters.py", line 501, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer'))可以提前单独下载后复制到部署服务器:
# 在能访问外网的服务器下载cl100k_base分词器
wget https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken \
-P ~/.cache/tiktoken/并配置环境变量或在代码中增加:
# 替换为你实际的路径
os.environ["TIKTOKEN_CACHE_DIR"] = '/root/.cache/tiktoken'3、 get_num_tokens_from_messages 方法未实现
第2步完成后,遇到新的问题。提示这个分词器没有实现get_num_tokens_from_messages方法。查看报错具体位置:
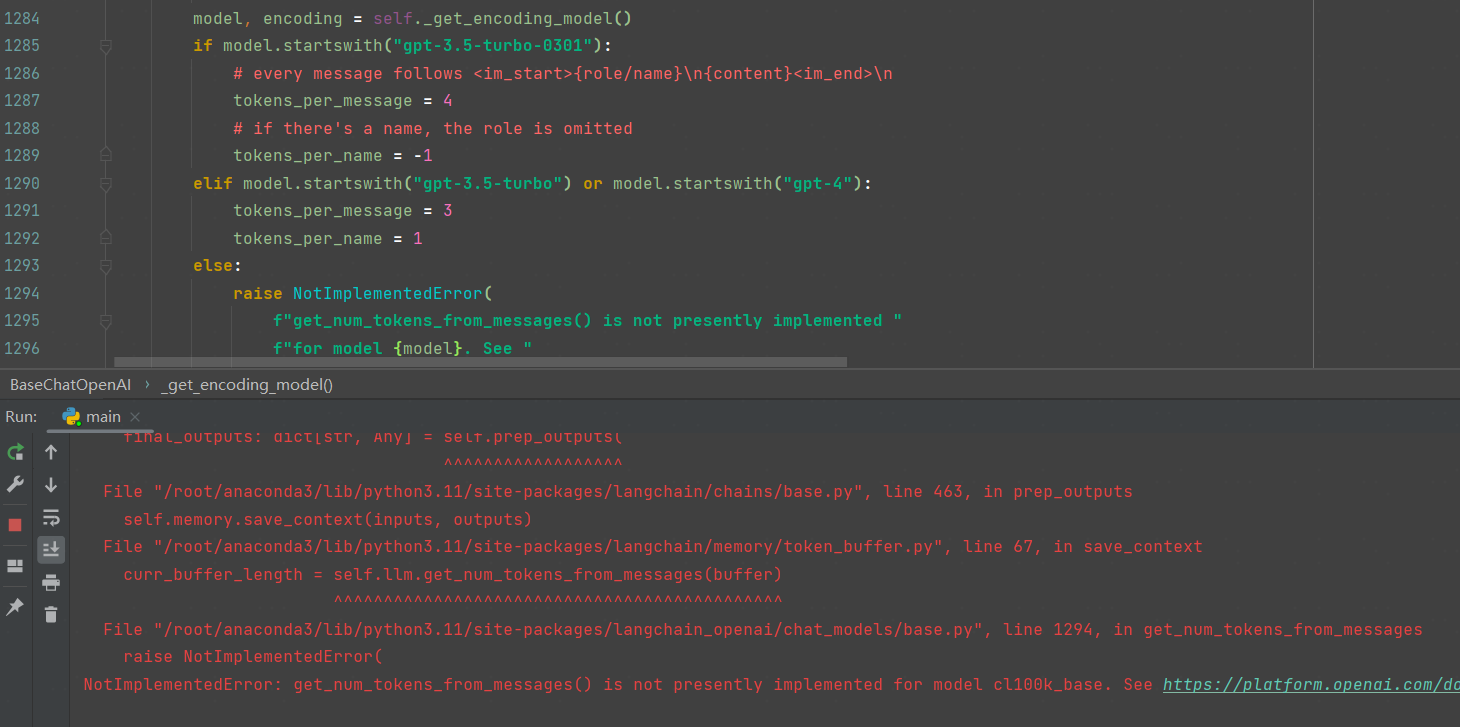
从源码可以看出,该模块仅支持gpt系列,因为接入时使用的是ChatOpenAI。解决方法就是,我们本地起的模型,可以取一个名字伪装,比如就叫gpt-4。如果langchai中后面有vLLM专用接口,或许就能解决这个问题。
4、工具调用异常
因为我的模型是Qwen,指定了工具解析是hermes,因此必须按照其格式要求定义函数。其中,工具函数必须有输入参数,没有也硬凑一个吧,否则会报错:validation erro。


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









