







 本文介绍了一种在不使用cookie的情况下,利用Python和BeautifulSoup爬取豆瓣电视剧评论的方法,详细展示了如何抓取用户信息及评论内容,并保存为CSV文件。
本文介绍了一种在不使用cookie的情况下,利用Python和BeautifulSoup爬取豆瓣电视剧评论的方法,详细展示了如何抓取用户信息及评论内容,并保存为CSV文件。
Python BeautifulSoup不需要cookie登录的状态下,爬取豆瓣电视剧评论!
什么是cookie呢?
cookie就是在浏览网站时服务器发送到浏览器上的一段数据,并通过用户浏览器存储到计算机硬盘或内存中的数据,主要用来服务器鉴别用户的身份,行为,当然也可以通过cookie来进行商品的推荐,cookie可以记录我们的浏览信息,购物车信息以及收藏夹的信息等等,总之cookie是很重要的,要保护好自己的cookie信息。
一般的情况下我们想要抓取网站上的评论的用户信息需要进行网站的用户登录,拿到cookie才能抓取用户的信息。然后我发现豆瓣电影品论前200好像不需要cookie信息也可以抓取用户信息。
由于最近在看古龙的《天涯明月刀》所以抓取了他的电视剧评论信息,方便爬取就简单的爬取三个字段。
网站:https://movie.douban.com/subject/6393366/comments?status=P
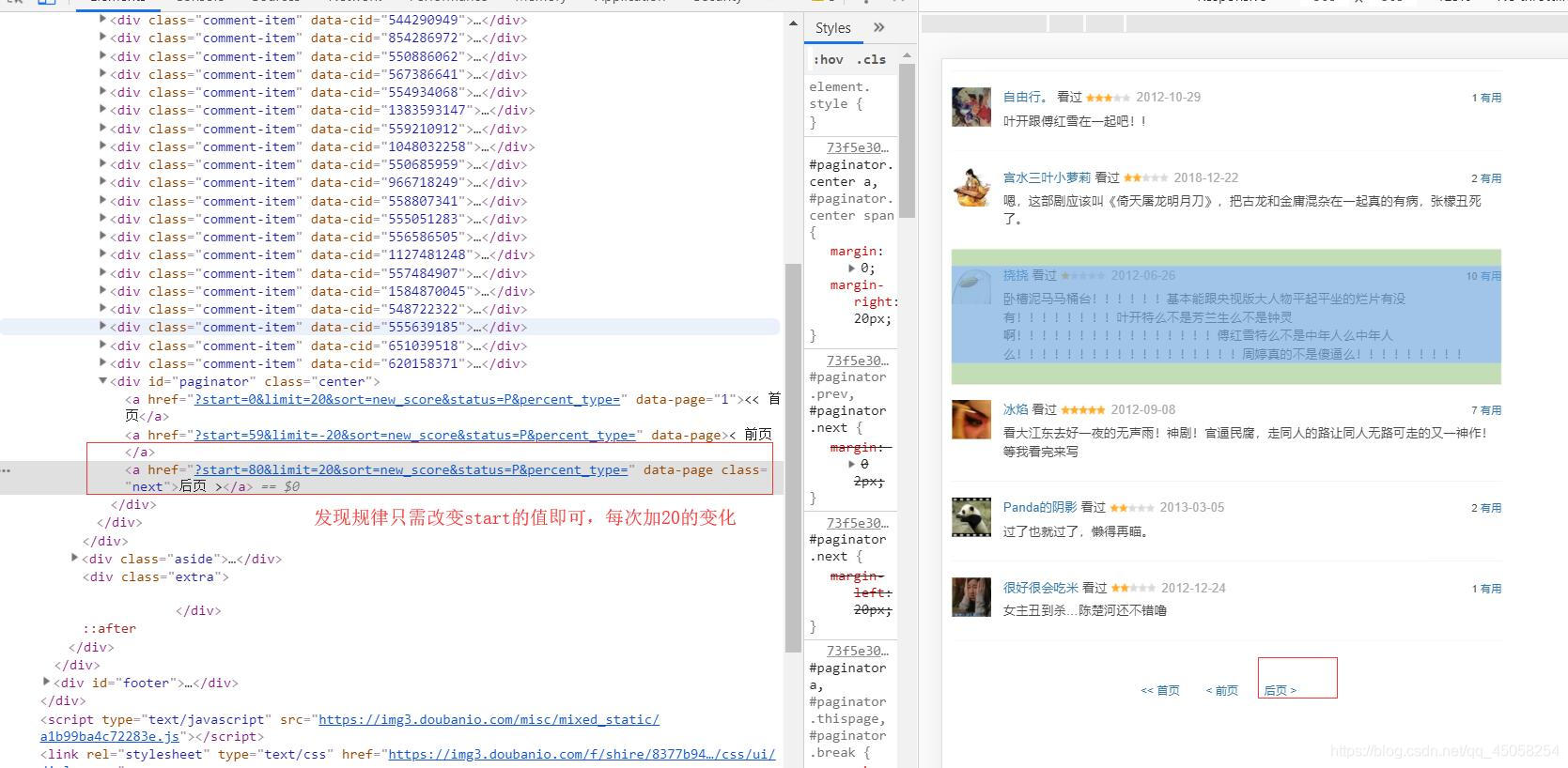
跳转页码
#encoding=utf-8
#@Project filename:PythonDemo Crawl-movieComments
#@IDE :PyCharm
#@Author :ganxiang
#@Date :2020/02/10 0010 20:29
import csv
import requests
from lxml import etree
from bs4 import BeautifulSoup
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
}
def visit_URL(url,x):
res = requests.get(url=url,headers=headers)
# print(res.status_code,res.text)
soup = BeautifulSoup(res.text,'lxml')
# print(soup.encode('gbk','ignore').decode('gbk'))
div_comment=soup.find_all(attrs={'class':'comment'})#找到所有评论的父div
with open('./comment.csv','a',newline='',encoding='gb18030')as f:
write = csv.writer(f)
i = x
for c in div_comment:
comment= c.find(attrs={'class':'comment-info'})#找到各一个评论者div的信息
people =comment.find('a')
author = people.get_text()
# print(str(author).encode('gbk','ignore').decode('gbk'))
author_href = people['href']
contents =c.p.span.get_text()#找到p标签下span标签下的评论内容
print("第"+str(i+1)+"评论:"+contents.encode('gbk','ignore').decode('gbk'))
row = [author, author_href,contents]
write.writerow(row)
i+=1
if __name__ == '__main__':
with open('./comment.csv', 'w', newline='', encoding='gb18030')as f:
head = ['author', ' author_href', 'comments']
write = csv.writer(f)
write.writerow(head)
list = []
for x in range(20, 200, 20):
ss = 'start='+str(x)+'&limit=20&sort=new_score&status=P&percent_type='
list.append(ss)
url = 'https://movie.douban.com/subject/6393366/comments?{}'.format(ss)
print(url)
visit_URL(url, x)
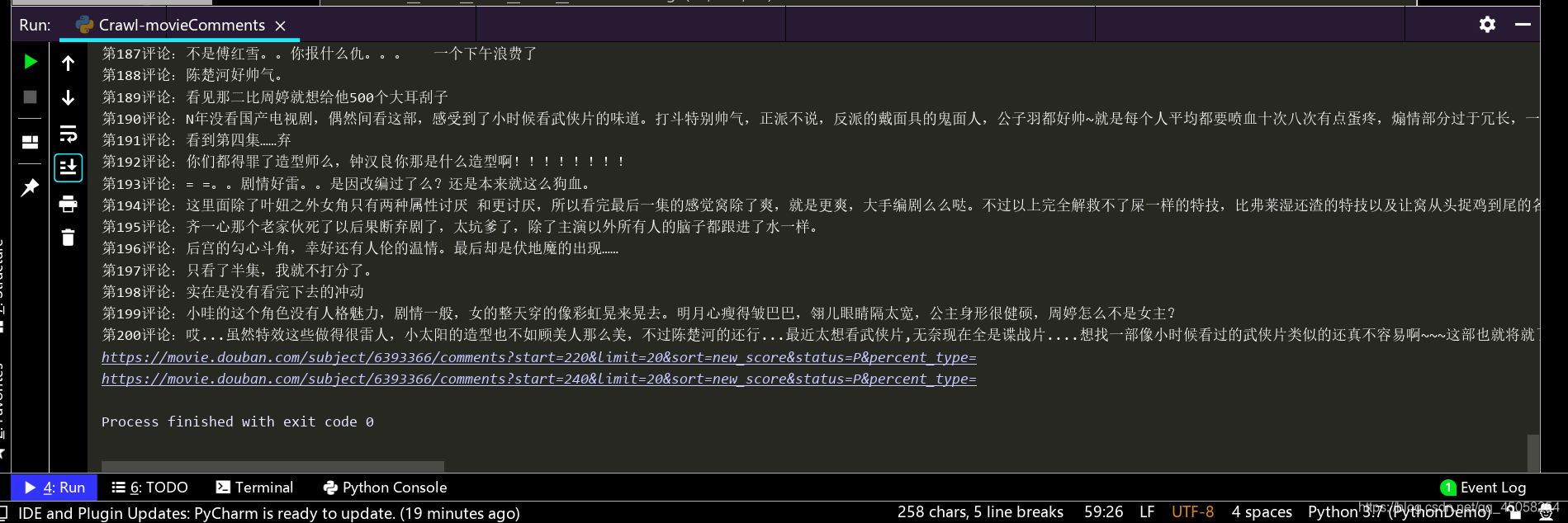
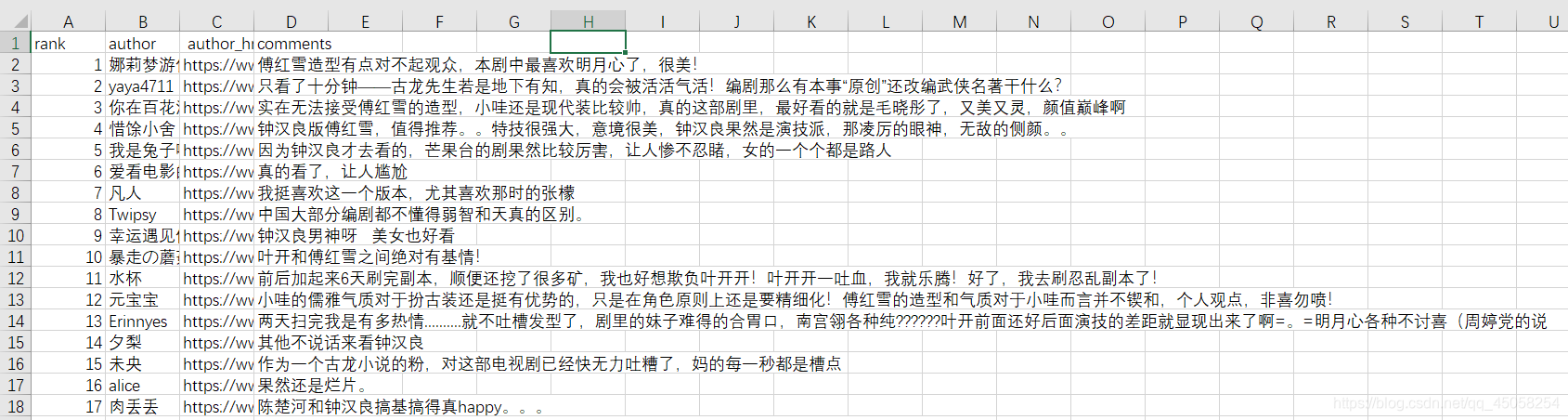
结果展示


















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









