









Windows+YOLOV8环境配置
下载链接1: https://download.csdn.net/download/qq_45077760/89018721 (CSDN)
下载链接2:https://github.com/up-up-up-up/YOLOv8/tree/master (github)
一、 YOLOv8环境配置
1.创建虚拟环境
YOLOv8所需要python>=3.8,博主之前用的是3.7,配置到最后发现python3.7对应的numpy最高是1.21,而YOLOv8要求的numpy最低是1.22.2,因此需要创建一个虚拟环境
conda create -n yolov8 python=3.8
2.下载YOLOv8源码
https://github.com/ultralytics/ultralytics,自己所用的是8.1.30版本,然后activate yolov8激活环境,安装requirements.txt里所需要的库,官网代码里requirements.txt文件是没有的,创建一个requirements.txt文件并把以下代码贴进去放在YOLOv8目录下,执行命令安装库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
requirements.txt代码内容
# Ultralytics requirements
# Example: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.3.0
numpy>=1.22.2 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
# torch>=1.8.0
# torchvision>=0.9.0
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=7.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1,<=2.13.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# jax<=0.4.21 # tensorflowjs bug https://github.com/google/jax/issues/18978
# jaxlib<=0.4.21 # tensorflowjs bug https://github.com/google/jax/issues/18978
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
接下来安装ultralytics和yolo包
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install yolo -i https://pypi.tuna.tsinghua.edu.cn/simple
3.推理运行
官网下载yolov8n.pt文件,并把他放在YOLOv8目录下,执行推理命令
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg'
如果遇到以下错误,执行命令
python setup.py install
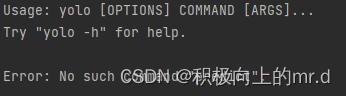
官网下载代码里是没有setup.py文件的,创建上setup.py文件并把它放在YOLOv8目录下,当然这些缺失文件我会在我的工程代码里打包给大家
setup.py
# Ultralytics YOLO 🚀, AGPL-3.0 license
import re
from pathlib import Path
from setuptools import setup
# Settings
FILE = Path(__file__).resolve()
PARENT = FILE.parent # root directory
README = (PARENT / 'README.md').read_text(encoding='utf-8')
def get_version():
"""
Retrieve the version number from the 'ultralytics/__init__.py' file.
Returns:
(str): The version number extracted from the '__version__' attribute in the 'ultralytics/__init__.py' file.
"""
file = PARENT / 'ultralytics/__init__.py'
return re.search(r'^__version__ = [\'"]([^\'"]*)[\'"]', file.read_text(encoding='utf-8'), re.M)[1]
def parse_requirements(file_path: Path):
"""
Parse a requirements.txt file, ignoring lines that start with '#' and any text after '#'.
Args:
file_path (str | Path): Path to the requirements.txt file.
Returns:
(List[str]): List of parsed requirements.
"""
requirements = []
for line in Path(file_path).read_text().splitlines():
line = line.strip()
if line and not line.startswith('#'):
requirements.append(line.split('#')[0].strip()) # ignore inline comments
return requirements
setup(
name='ultralytics', # name of pypi package
version=get_version(), # version of pypi package
python_requires='>=3.8',
license='AGPL-3.0',
description=('Ultralytics YOLOv8 for SOTA object detection, multi-object tracking, instance segmentation, '
'pose estimation and image classification.'),
long_description=README,
long_description_content_type='text/markdown',
url='https://github.com/ultralytics/ultralytics',
project_urls={
'Bug Reports': 'https://github.com/ultralytics/ultralytics/issues',
'Funding': 'https://ultralytics.com',
'Source': 'https://github.com/ultralytics/ultralytics'},
author='Ultralytics',
author_email='hello@ultralytics.com',
packages=['ultralytics'] + [str(x) for x in Path('ultralytics').rglob('*/') if x.is_dir() and '__' not in str(x)],
package_data={
'': ['*.yaml'],
'ultralytics.assets': ['*.jpg']},
include_package_data=True,
install_requires=parse_requirements(PARENT / 'requirements.txt'),
extras_require={
'dev': [
'ipython',
'check-manifest',
'pre-commit',
'pytest',
'pytest-cov',
'coverage',
'mkdocs-material',
'mkdocstrings[python]',
'mkdocs-redirects', # for 301 redirects
'mkdocs-ultralytics-plugin>=0.0.30', # for meta descriptions and images, dates and authors
],
'export': [
'coremltools>=7.0',
'openvino-dev>=2023.0',
'tensorflow<=2.13.1',
'tensorflowjs', # automatically installs tensorflow
], },
classifiers=[
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Intended Audience :: Education',
'Intended Audience :: Science/Research',
'License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: 3.9',
'Programming Language :: Python :: 3.10',
'Programming Language :: Python :: 3.11',
'Topic :: Software Development',
'Topic :: Scientific/Engineering',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'Topic :: Scientific/Engineering :: Image Recognition',
'Operating System :: POSIX :: Linux',
'Operating System :: MacOS',
'Operating System :: Microsoft :: Windows', ],
keywords='machine-learning, deep-learning, vision, ML, DL, AI, YOLO, YOLOv3, YOLOv5, YOLOv8, HUB, Ultralytics',
entry_points={'console_scripts': ['yolo = ultralytics.cfg:entrypoint', 'ultralytics = ultralytics.cfg:entrypoint']})
然后再次执行推理命令,一般不会再出现问题,如果出现pandas、scipy等报错,直接pip install 安装就行
推理结果
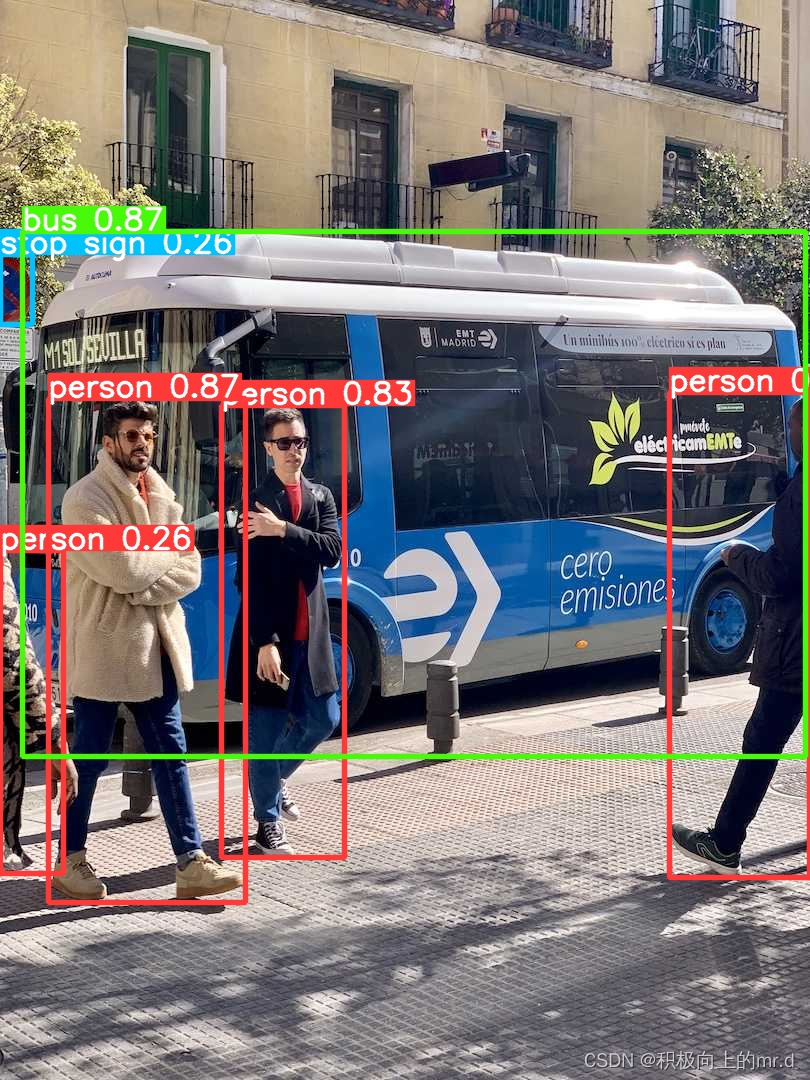
若想打印输出检测类别和边框坐标,可执行以下代码
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
file_path = 'ultralytics/assets/bus.jpg'
results = model.predict(source=file_path, show=True, save=True)
boxes = results[0].boxes.xywh.cpu()
classes = results[0].names
for box, class_idx in zip(boxes, classes):
x_center, y_center, width, height = box.tolist()
name = classes[int(class_idx)]
x1 = x_center - width / 2
y1 = y_center - height / 2
x2 = x_center + width / 2
y2 = y_center + height / 2
print("class name:", name)
print("Bounding box coordinates (x1, y1, x2, y2):", x1, y1, x2, y2)

检测某些类别,如人和车
model = YOLO('yolov8n-seg.pt')
model.predict(source='ultralytics/assets', show=True, save=True, classes=[0,2])
4.训练数据集
数据集采用YOLO格式,目录如下:
dataset
|
coco
|
images
|
train2017
|
1.jpg
2.jpg
val2017
|
11.jpg
22.jpg
labels
|
train2017
|
1.txt
2.txt
val2017
|
11.txt
22.txt
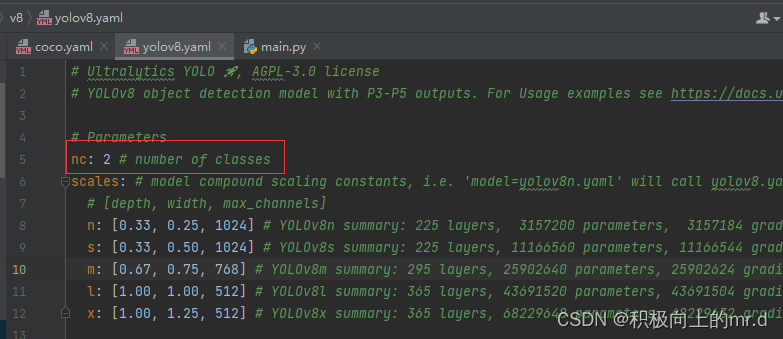
打开ultralytics/cfg/datasets/coco.yaml文件,把里边的内容修改如下(这里训练两个类别)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset https://cocodataset.org by Microsoft
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../dataset/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 118287 images
val: images/val2017 # val images (relative to 'path') 5000 images
#test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: person
1: bicycle
同时把ultralytics/cfg/models/v8/yolov8.yaml文件的类别改成与上边对应的类别数
接下来执行训练命令即可
yolov8n.pt是你选择的预训练模型,yolov8n.yaml与yolov8n.pt对应
from ultralytics import YOLO
import cv2
import os
from ultralytics.utils.plotting import Annotator, colors
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8n.yaml').load('yolov8n.pt')
# Train the model
model.train(data='ultralytics/cfg/datasets/coco.yaml', epochs=100, imgsz=640, save_period=5, device='0',batch=32)
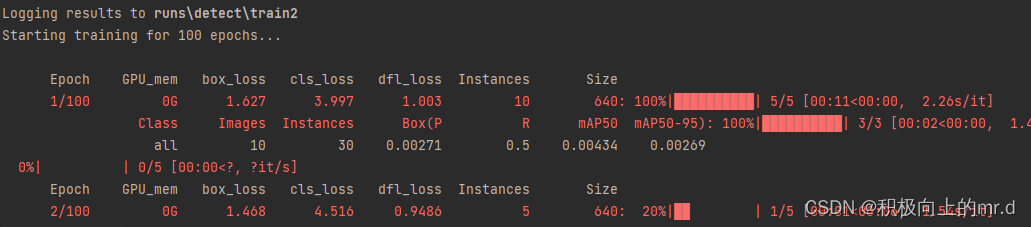
训练好在runs\detect\train文件夹下会生成权重,直接使用即可
二、YOLOv8分割、跟踪、姿态估计
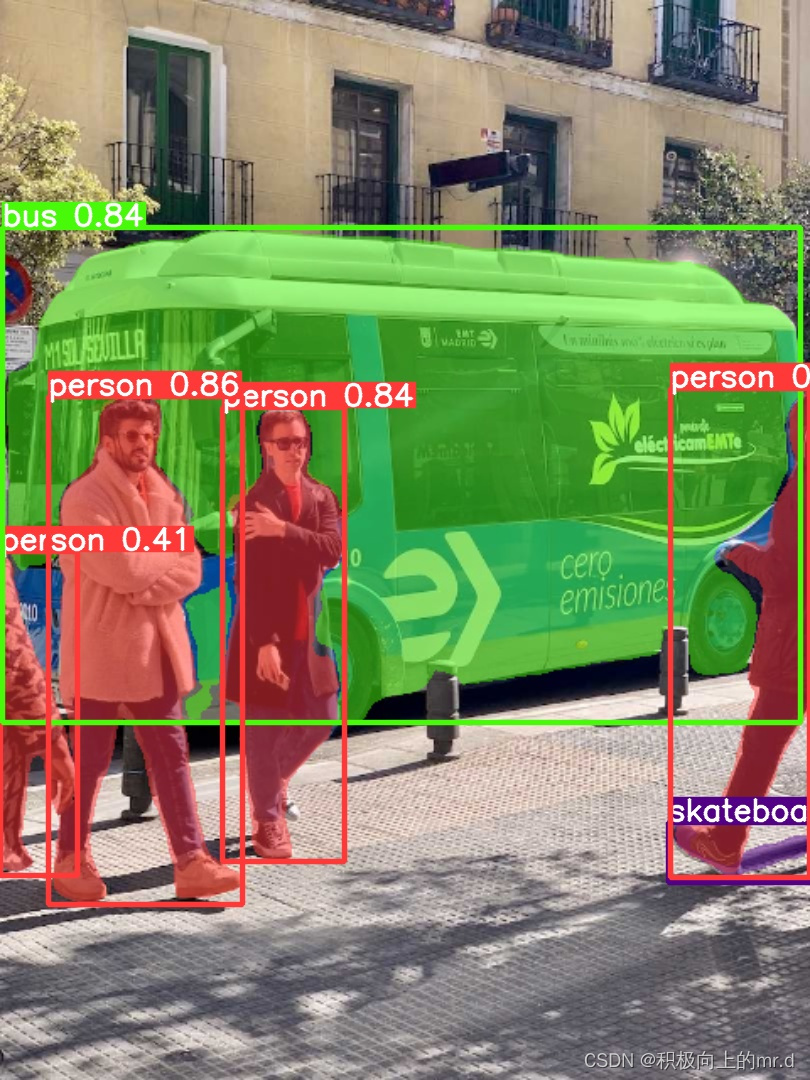
1. YOLOv8分割
执行以下命令,也可换成其他权重
yolo task=segment mode=predict model=yolov8n-seg.pt source='ultralytics/assets/bus.jpg' show=True
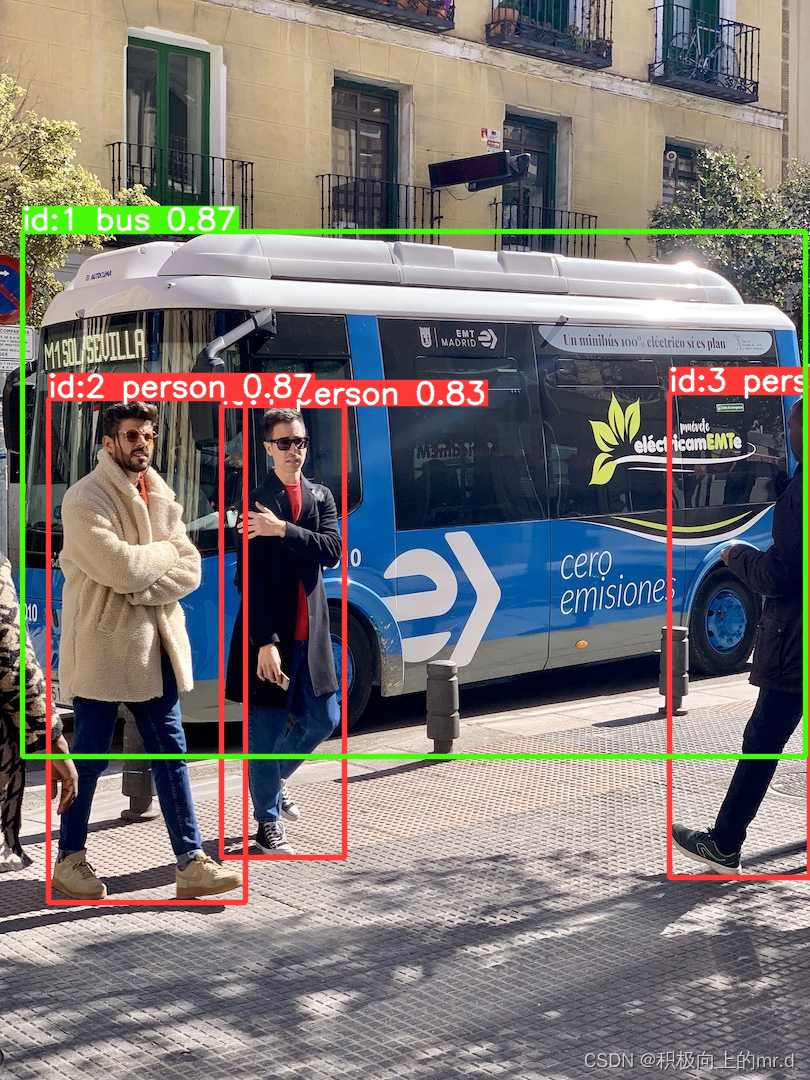
2. YOLOv8跟踪
yolo track model=yolov8n.pt source='ultralytics/assets/bus.jpg'
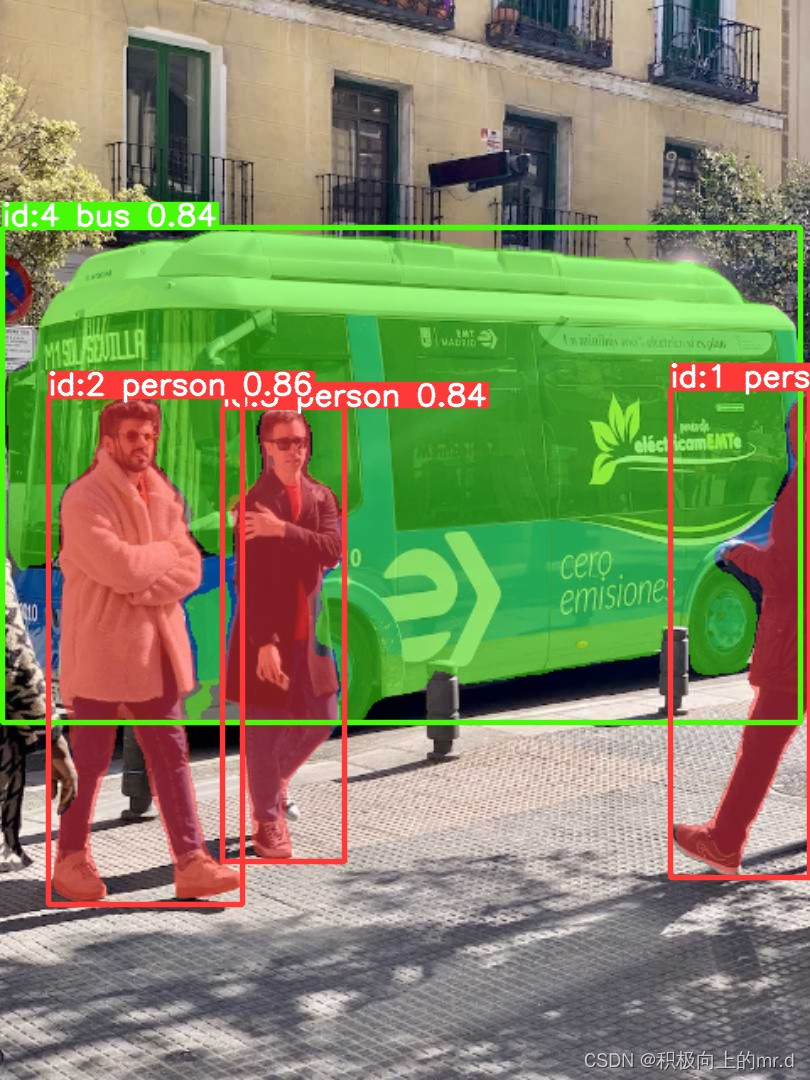
3. YOLOv8姿态估计
yolo pose predict model=yolov8n-pose.pt source='ultralytics/assets' show=True save=True

4. 集成运行
(1)检测、跟踪和分割
yolo pose predict track model=yolov8n-seg.pt source='ultralytics/assets' show=True save=True
(2)检测、跟踪和姿态估计
yolo pose predict track model=yolov8n-pose.pt source='ultralytics/assets' show=True save=True
(3)集成
把以上代码整合到main.py文件里,可同时进行检测+跟踪+分割方便运行,也可单独运行推理、训练、验证、分割、跟踪、姿态估计,想用哪个直接免去注释即可
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
# 直接使用预训练模型创建模型
# model = YOLO('yolov8n.pt')
# model.train(**{'cfg':'ultralytics/cfg/default.yaml', 'data':'ultralytics/models/yolo/detect/mydata/traffic.yaml'}, epochs=10, imgsz=640, batch=32)
# #使用yaml配置文件来创建模型,并导入预训练权重
#model = YOLO('ultralytics/cfg/models/v8/yolov8n.yaml') # build a new model from YAML
#model.load('yolov8n.pt')
#model.train(**{'cfg': 'ultralytics/cfg/default.yaml', 'data': 'ultralytics/models/yolo/detect/mydata/traffic.yaml'},
# epochs=10, imgsz=640, batch=32, name='train') # name:是此次训练结果保存的文件夹 数据集是我自己的数据集
# # # 模型验证:用验证集
# model = YOLO('runs/detect/train/weights/best.pt')
# model.val(**{'data':'ultralytics/models/yolo/detect/mydata/traffic.yaml', 'name':'val', 'batch':32}) #模型验证用验证集
# model.val(**{'data':'ultralytics/models/yolo/detect/mydata/traffic.yaml', 'split':'test', 'iou':0.9}) #模型验证用测试集
# # 推理:
'''model = YOLO('yolov8n.pt')
model.predict(source='ultralytics/assets', show=True, save=True)'''
# model.predict(source='ultralytics/assets', name='predict', **{'save':True}) # 写法二
# 分割:
''''model = YOLO('yolov8n-seg.pt')
model.predict(source='ultralytics/assets', name='predict', **{'save': True})'''
# 跟踪:
'''model = YOLO('yolov8n.pt')
model.track(source="ultralytics/assets", show=True, save=True)'''
# 姿态估计:
'''model = YOLO('yolov8n-pose.pt')
model.predict(source="ultralytics/assets", show=True, save=True)'''
# 检测、跟踪、分割:
'''model = YOLO('yolov8n-seg.pt') # 加载一个官方的分割模型
model.track(source="ultralytics/assets", show=True, save=True)'''
# 检测、跟踪、姿态估计:
'''model = YOLO('yolov8n-pose.pt') # 加载一个官方的分割模型
model.track(source="ultralytics/assets", show=True, save=True)'''
#results = model.track(source="ultralytics/assets", show=True, tracker="bytetrack.yaml") # 使用ByteTrack追踪器进行追踪
5. 实例分割+跟踪
实例分割和上边掩码分割不同,实例着重关注轮廓
实例分割
(1)Instance Segmentation-pic-video,py文件,检测文件夹里的所有图和视频
from ultralytics import YOLO
import cv2
import os
from ultralytics.utils.plotting import Annotator, colors
if __name__ == '__main__':
# 实例分割检测文件夹里所有图片视频(实例分割和掩码分割不同):
model = YOLO('yolov8n-seg.pt')
names = model.model.names
input_folder = 'ultralytics/assets' # 输入文件夹
output_folder = 'runs/detect/test' # 输出文件夹
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取输入文件夹中所有文件的文件名
all_files = [f for f in os.listdir(input_folder)]
for file_name in all_files:
file_path = os.path.join(input_folder, file_name)
if file_name.endswith('.jpg') or file_name.endswith('.png'):
# 处理图片
im0 = cv2.imread(file_path)
results = model.predict(im0)
annotator = Annotator(im0, line_width=2)
if results[0].masks is not None:
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
for mask, cls in zip(masks, clss):
annotator.seg_bbox(mask=mask,
mask_color=colors(int(cls), True),
det_label=names[int(cls)])
output_path = os.path.join(output_folder, file_name)
cv2.imwrite(output_path, im0)
elif file_name.endswith('.mp4') or file_name.endswith('.avi'):
# 处理视频
cap = cv2.VideoCapture(file_path)
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter(os.path.join(output_folder, file_name + '_segmented.avi'), cv2.VideoWriter_fourcc(*'MJPG'),
fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
print(f"视频 {file_name} 处理完成")
break
results = model.predict(im0)
annotator = Annotator(im0, line_width=2)
if results[0].masks is not None:
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
for mask, cls in zip(masks, clss):
annotator.seg_bbox(mask=mask,
mask_color=colors(int(cls), True),
det_label=names[int(cls)])
out.write(im0)
cv2.imshow("instance-segmentation", im0)
out.release()
cap.release()
(2)Instance Segmentation-camera,py文件,调用摄像头检测
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolov8n-seg.pt") # segmentation model
names = model.model.names
cap = cv2.VideoCapture(0)
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter('instance-segmentation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
print("Video frame is empty or video processing has been successfully completed.")
break
results = model.predict(im0)
annotator = Annotator(im0, line_width=2)
if results[0].masks is not None:
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
for mask, cls in zip(masks, clss):
annotator.seg_bbox(mask=mask,
mask_color=colors(int(cls), True),
det_label=names[int(cls)])
out.write(im0)
cv2.imshow("instance-segmentation", im0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
out.release()
cap.release()
cv2.destroyAllWindows()

实例分割+跟踪
(1)Instance Segmentation-track-pic-video,py文件,检测文件夹里的所有图和视频
from ultralytics import YOLO
import cv2
import os
from ultralytics.utils.plotting import Annotator, colors
from collections import defaultdict
if __name__ == '__main__':
# 实例分割检测文件夹里所有图片视频(实例分割和掩码分割不同):
model = YOLO('yolov8n-seg.pt')
names = model.model.names
input_folder = 'ultralytics/assets' # 输入文件夹
output_folder = 'runs/detect/test1' # 输出文件夹
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取输入文件夹中所有文件的文件名
all_files = [f for f in os.listdir(input_folder)]
for file_name in all_files:
file_path = os.path.join(input_folder, file_name)
if file_name.endswith('.jpg') or file_name.endswith('.png'):
# 处理图片
im0 = cv2.imread(file_path)
results = model.track(im0)
annotator = Annotator(im0, line_width=2)
if results[0].boxes.id is not None and results[0].masks is not None:
masks = results[0].masks.xy
track_ids = results[0].boxes.id.int().cpu().tolist()
for mask, track_id in zip(masks, track_ids):
annotator.seg_bbox(mask=mask,
mask_color=colors(track_id, True),
track_label=str(track_id))
output_path = os.path.join(output_folder, file_name)
cv2.imwrite(output_path, im0)
elif file_name.endswith('.mp4') or file_name.endswith('.avi'):
# 处理视频
cap = cv2.VideoCapture(file_path)
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter(os.path.join(output_folder, file_name + '_segmented.avi'), cv2.VideoWriter_fourcc(*'MJPG'),
fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
print(f"视频 {file_name} 处理完成")
break
results = model.track(im0)
annotator = Annotator(im0, line_width=2)
if results[0].boxes.id is not None and results[0].masks is not None:
masks = results[0].masks.xy
track_ids = results[0].boxes.id.int().cpu().tolist()
for mask, track_id in zip(masks, track_ids):
annotator.seg_bbox(mask=mask,
mask_color=colors(track_id, True),
track_label=str(track_id))
out.write(im0)
cv2.imshow("instance-segmentation", im0)
out.release()
cap.release()
(2)Instance Segmentation-track-camera,py文件,调用摄像头检测
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
from collections import defaultdict
track_history = defaultdict(lambda: [])
model = YOLO("yolov8n-seg.pt") # segmentation model
cap = cv2.VideoCapture(0)
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter('instance-segmentation-object-tracking.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
print("Video frame is empty or video processing has been successfully completed.")
break
annotator = Annotator(im0, line_width=2)
results = model.track(im0, persist=True)
if results[0].boxes.id is not None and results[0].masks is not None:
masks = results[0].masks.xy
track_ids = results[0].boxes.id.int().cpu().tolist()
for mask, track_id in zip(masks, track_ids):
annotator.seg_bbox(mask=mask,
mask_color=colors(track_id, True),
track_label=str(track_id))
out.write(im0)
cv2.imshow("instance-segmentation-object-tracking", im0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
out.release()
cap.release()
cv2.destroyAllWindows()

有关YOLOv8的更多使用说明可见 Ultralytics YOLO

















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











